Quick Start
We provide a simple model inference interface, including preprocessing and postprocessing logic.
First, you need to import the required dependencies and create the DocClassifier class.
Registering Data
Before we talk about the model, let's first discuss registering data.
In the inference data folder, there is a register folder that contains all the registered data. You can place your registration data here, and DocClassifier will automatically read all the data in the folder during inference. If you want to use your own dataset, specify the register_root parameter when creating the DocClassifier, and set it to the root directory of your dataset.
We have preloaded several image registration files within the module. You can refer to these files and expand them as needed. We strongly recommend using your own dataset to ensure the model can adapt to your application scenario.

We recommend using full-page images with minimal background interference to improve the stability of the model.
Many of the images preloaded in the folder are collected from the internet, and their resolution is low. They are only for demonstration purposes and are not suitable for deployment. Please use the register_root parameter with your own dataset to ensure the model adapts to your use case.
Duplicate Registration
This issue is divided into two situations:
-
Situation 1: Duplicate file names
In our implementation, the file names in the registration folder serve as the query index for the data.
Therefore, when file names are duplicated, the latter files will overwrite the former ones.
This issue is not serious, as the overwritten files won't be used, and it won't affect the model's inference.
-
Situation 2: Duplicate file contents
The same file is registered more than once.
Suppose the user registers three identical images with different labels. During inference, the scores will be the same in the similarity ranking process, but one will always appear first. In this case, the model cannot guarantee that the same label will be returned each time.
This issue is also not severe, but it does introduce uncertainty, and you may end up with no idea why it is happening. (
Hey!)
In short, please take your registration data seriously.
Model Inference
We have designed an automatic model download feature. When the program detects that you are missing a model, it will automatically connect to our server to download it.
Once the registration data is ready, you can start model inference.
Here is a simple example, starting with the model:
import cv2
from skimage import io
from docclassifier import DocClassifier
img = io.imread('https://github.com/DocsaidLab/DocClassifier/blob/main/docs/test_driver.jpg?raw=true')
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
model = DocClassifier()
most_similar, max_score = model(img)
print(f'most_similar: {most_similar}, max_score: {max_score:.4f}')
# >>> most_similar: None, max_score: 0.0000
For the above example, refer to the image download link: test_driver.jpg
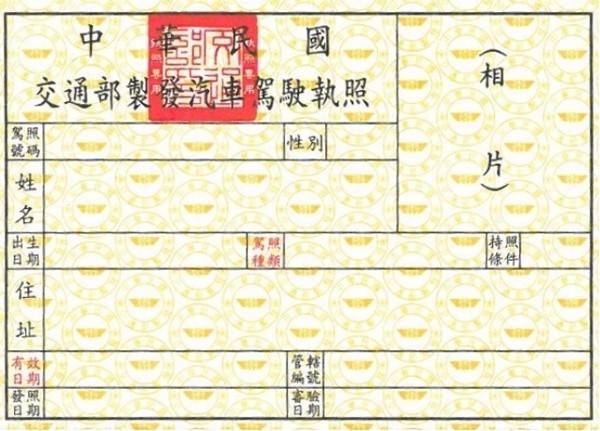
By default, this example returns None and 0.0000 because the difference between our default registration data and the input image is significant. Therefore, the model finds the similarity between the image and the registration data to be very low.
The default registered driver's license sample is a moose; the input image is a blank driver's license. (That's quite a mismatch!)
In this case, you may consider lowering the threshold parameter:
model = DocClassifier(
threshold=0.6
)
# Re-run the inference
most_similar, max_score = model(img)
print(f'most_similar: {most_similar}, max_score: {max_score:.4f}')
# >>> most_similar: Taiwan driver's license front, max_score: 0.6116
This time, you will get a label name and a score: Taiwan driver's license front and 0.6116. This score represents the similarity between the input image and the registration data.
DocClassifier is wrapped with __call__, so you can directly call the instance for inference.
Threshold Settings
We use the TPR@FPR=1e-4 standard to evaluate the model's capability, but this standard is relatively strict and may lead to a suboptimal user experience during deployment.
Therefore, we recommend using a TPR@FPR=1e-1 or TPR@FPR=1e-2 threshold setting during deployment.
Currently, our default threshold uses the TPR@FPR=1e-2 standard, which we have determined through testing and evaluation to be a more suitable threshold. The detailed threshold settings are shown in the table below:
-
lcnet050_cosface_f256_r128_squeeze_imagenet_clip_20240326 results
-
Setting
model_cfgto "20240326" -
TPR@FPR=1e-4: 0.912
FPR 1e-05 1e-04 1e-03 1e-02 1e-01 1 TPR 0.856 0.912 0.953 0.980 0.996 1.0 Threshold 0.705 0.682 0.657 0.626 0.581 0.359
-