クイックスタート
私たちは、前処理と後処理のロジックを含むシンプルなモデル推論インターフェースを提供しています。
まず、必要な依存関係をインポートし、DocClassifier クラスを作成する必要があります。
登録データ
モデルについて話す前に、登録データについて説明します。
推論データフォルダには register フォルダがあり、そこにはすべての登録データが含まれています。自分のデータを登録したい場合は、そのフォルダにデータを配置すれば、DocClassifier が自動的にそのデータを読み取ります。自分のデータセットを使用する場合は、DocClassifier を作成するときに register_root パラメータを指定し、データセットのルートディレクトリを設定してください。
モジュール内にはいくつかのサンプル画像データが登録されていますので、これらを参考にして自分で拡張することができます。また、モデルがあなたのアプリケーションシーンに適応するように、独自のデータセットの使用を強くお勧めします。

登録データにはフルサイズの画像を使用し、背景の干渉を最小限に抑えることで、モデルの安定性を向上させることをお勧めします。
フォルダ内にあらかじめ配置されている画像は、インターネットから収集されたものが多く、解像度が低いため、展示用であり、実際のデプロイには適していません。register_root パラメータを使って、自分のデータセットを適切に設定してください。これにより、モデルがあなたのアプリケーションシーンに適応することができます。
重複登録
この問題には 2 つのケースがあります:
-
ケース 1:重複したファイル名
実装されたロジックでは、登録フォルダ内のファイル名がデータの検索インデックスとして使用されます。
したがって、ファイル名が重複すると、後に登録されたファイルが前のファイルを上書きします。
この場合、上書きされたファイルは使用されませんが、モデルの推論には影響しません。
-
ケース 2:重複したファイル内容
同じファイルが複数回登録された場合です。
例えば、ユーザーが同じ画像を 3 回登録し、異なるラベルを付けた場合、推論中に類似性を評価する際、スコアが同じになりますが、常に最初のファイルが優先されます。このような場合、モデルは必ずしも毎回同じラベルを返すわけではありません。
このケースも大きな問題ではありませんが、モデルに不確実性が入り込み、原因も追いにくくなります。(
あれ?)
要するに、登録データはきちんと管理してください。
モデル推論
モデルが不足している場合、プログラムは自動的にサーバーからダウンロードする機能を提供しています。
登録データが準備できたら、モデル推論を開始することができます。
以下は簡単なサンプルです。まず、モデルを起動します:
import cv2
from skimage import io
from docclassifier import DocClassifier
img = io.imread('https://github.com/DocsaidLab/DocClassifier/blob/main/docs/test_driver.jpg?raw=true')
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
model = DocClassifier()
most_similar, max_score = model(img)
print(f'most_similar: {most_similar}, max_score: {max_score:.4f}')
# >>> most_similar: None, max_score: 0.0000
上記の例で使用されている画像のダウンロードリンクはこちらです:test_driver.jpg
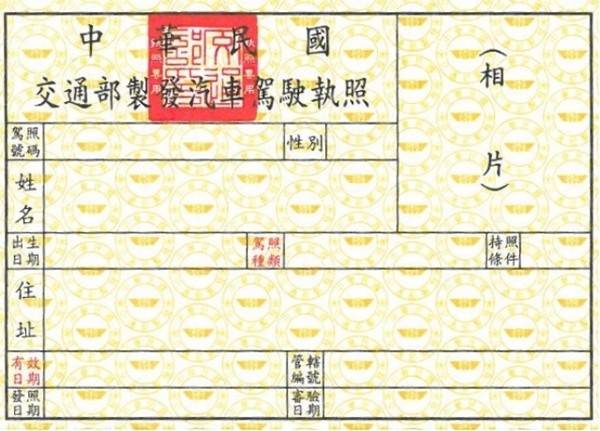
デフォルトでは、この例は None と 0.0000 を返します。これは、デフォルトの登録データと入力画像に大きな違いがあるため、モデルが入力画像と登録データの類似性を非常に低く評価したためです。
デフォルトで登録されている運転免許証データはヘラジカで、入力画像は空白の運転免許証です。(差が大きすぎます)
このような場合、threshold パラメータを下げることを検討できます:
model = DocClassifier(
threshold=0.6
)
# 再度推論を実行
most_similar, max_score = model(img)
print(f'most_similar: {most_similar}, max_score: {max_score:.4f}')
# >>> most_similar: 台湾運転免許証正面, max_score: 0.6116
これで、台湾運転免許証正面 と 0.6116 というラベル名とスコアが返されます。このスコアは、入力画像と登録データとの類似性を示しています。
DocClassifier は __call__ でラップされているので、インスタンスを直接呼び出して推論を実行できます。
閾値設定
モデルの能力を評価する際には、TPR@FPR=1e-4 の基準を使用していますが、実際にはこの基準は比較的厳しく、デプロイ時にはあまり良いユーザー体験を提供できません。
そのため、デプロイ時には TPR@FPR=1e-1 または TPR@FPR=1e-2 の閾値設定を採用することをお勧めします。
現在、私たちのデフォルトの閾値は TPR@FPR=1e-2 で、これはテストと評価の結果、最も適した閾値だと考えています。詳細な閾値設定は以下の通りです:
-
lcnet050_cosface_f256_r128_squeeze_imagenet_clip_20240326 の結果
-
model_cfgを "20240326" に設定 -
TPR@FPR=1e-4: 0.912
FPR 1e-05 1e-04 1e-03 1e-02 1e-01 1 TPR 0.856 0.912 0.953 0.980 0.996 1.0 Threshold 0.705 0.682 0.657 0.626 0.581 0.359
-