Introduction
In the current research on Optical Character Recognition (OCR), the accuracy of models depends on the quality and diversity of the dataset.
Here are a few issues faced by current research:
- Insufficient Data: Existing datasets are limited in size and cannot cover all possible scenarios and samples.
- Class Imbalance: Some classes have too few samples, leading to a severe long-tail distribution.
- Lack of Diversity: Existing datasets contain overly homogeneous samples that cannot cover the diverse scenarios in the real world.
- Difference Between Synthetic and Real Data: Synthetic datasets differ from data in real-world applications.
Additionally, compared to a few dozen to a few hundred Latin letters, the number of Chinese characters is a disaster. (Hey! Show some respect!)
In Chinese OCR research, in addition to the issues mentioned above, there are more unique challenges:
-
Character Diversity and Quantity
Chinese characters include thousands of commonly used ones and nearly one hundred thousand rare characters, with a very uneven distribution from common to rare characters.
tipOne hundred thousand? Are you kidding me?
This number is based on data from the Wikipedia Unicode Expansion of Chinese Characters. Currently, there are about 90,000 Chinese characters and the number continues to grow.
-
Complex Character Structure and Semantic Dependence
Chinese characters consist of multiple strokes, with varying stroke shapes and arrangements. Many similar characters can only be distinguished through context.
tipFor example: (口, 囗), (日, 曰), (木, 朩), etc.
-
Writing Style
The difficulties caused by writing styles are not limited to individual characters. Each character can have many different forms. With the vast number of Chinese characters, various fonts and writing styles further increase the difficulty of recognition.

-
Vertical Text and Mixed Chinese-English Layouts
Chinese often appears in vertical text, especially in applications related to traditional culture. Additionally, influenced by Western culture, mixed Chinese-English texts are now common, which adds further challenges to text recognition.

-
Limited Annotation Resources
This is probably the most difficult part. Unlike phonetic languages with just a few dozen letters, the vast number of Chinese characters makes annotating a high-quality dataset both time-consuming and expensive.
tipForget about the difficulty of finding material. Even if you find it, the annotators may not recognize those rare characters.
Goal
Therefore, the goal of this project is to address the above issues...
Well, sorry, these problems are too big. At least we can start by solving part of them.
We generate a large number of diverse Chinese text images through synthetic data to address issues like insufficient data, class imbalance, and lack of diversity. To do this, we referenced some existing text synthesis tools.
For more details, refer to: Related Resources
Their design inspired us to create a new text image generator from scratch.
Our generation module is not based on a predefined text encoding table, but rather on fonts (more precisely, based on Pillow implementation). In other words, we can generate text images in any font, supporting various text directions, alignments, text lengths, text colors, background colors, etc.
As long as you can find the font, we can use it to generate images.
Design Philosophy
In the design process, we considered using a "functional design" or "object-oriented design."
In the end, we chose the latter because, no matter what, you'll find it hard to use either one. (???)
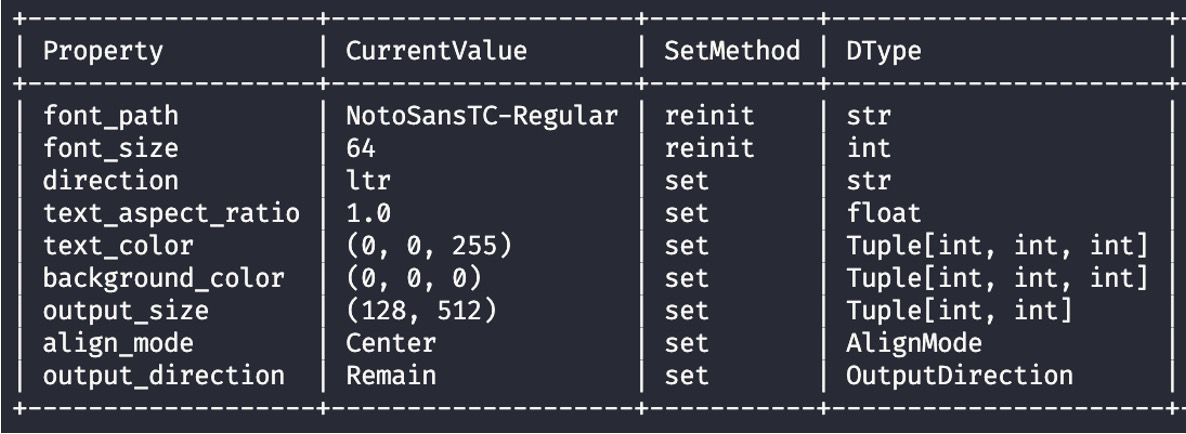
In fact, a large number of selectable parameters can overwhelm the user, and object-oriented design allows us to organize these parameters better. To this end, we designed a dashboard (as shown below), hoping you can understand the current settings and make adjustments as if you were driving a car.
Conclusion
In this project, we completed several features:
- Dashboard: Understand and adjust the current settings.
- Image Generation: Generate diverse text images.
- Output Alignment: Support four alignment methods.
- Output Direction: Support both horizontal and vertical output directions.
- Text Compression: Support compressed text feature.
- Standardized Output Size: Support standardized image size output.
- Random Fonts: Support random font selection.
- Random Text: Support random text selection.
- Random Text Length: Support random text length selection.
- Random Text Color: Support random text color selection.
- Random Background Color: Support random background color selection.
- Random Text Direction: Support random text direction selection.
- Random Alignment: Support random alignment method selection.
- Random Minimum Text Length: Support specifying the minimum text length.
- Random Maximum Text Length: Support specifying the maximum text length.
If you have any other needs, feel free to leave a comment below.
When the time comes, we'll add new features according to your requests.