快速開始
萬事起頭難,所以我們需要一個簡單的開始。
從一個字串開始
先給定一個基本宣告,然後就可以開始使用了。
from wordcanvas import WordCanvas
gen = WordCanvas(return_infos=True)
全部使用預設功能,直接調用函數即可生成文字圖像。
text = "你好!Hello, World!"
img, infos = gen(text)
print(img.shape)
# >>> (67, 579, 3)
print(infos)
# {'text': '你好!Hello, World!',
# 'bbox(xyxy)': (0, 21, 579, 88),
# 'bbox(wh)': (579, 67),
# 'offset': (0, -21),
# 'direction': 'ltr',
# 'background_color': (0, 0, 0),
# 'text_color': (255, 255, 255),
# 'spacing': 4,
# 'align': 'left',
# 'stroke_width': 0,
# 'stroke_fill': (0, 0, 0),
# 'font_path': 'fonts/NotoSansTC-Regular.otf',
# 'font_size_actual': 64,
# 'font_name': 'NotoSansTC-Regular',
# 'align_mode': <AlignMode.Left: 0>,
# 'output_direction': <OutputDirection.Remain: 0>}

在預設模式下,輸出影像的尺寸取決於:
- 字型大小:預設為 64,隨著字型大小的增加,影像尺寸也會增加。
- 文字長度:文字越長,影像寬度也會增加,具體長度由
pillow決定。 - 輸出資訊
infos內涵蓋所有繪製參數,包含文字、背景顏色、文字顏色等。 - 如果要單純輸出影像,設定
return_infos=False即可,這也是預設值。
指定特定字型
使用 font 參數可以指定自己喜歡的字型。
from wordcanvas import WordCanvas
# 不指定 return_infos,預設為 False,將不會返回 infos
gen = WordCanvas(
font_path="/path/to/your/font/OcrB-Regular.ttf"
)
text = 'Hello, World!'
img = gen(text)

當字型不支援輸入文字時,會出現豆腐字。
text = 'Hello, 中文!'
img = gen(text)

檢查字型是否支援的方法:
目前我沒有這種需求,所以我留下了一個基礎的方法。這個方法是一個簡單的檢查,每次只能檢查一個字元,所以需要遍歷所有的字元。如果你有其他需求,請自行擴展。
from wordcanvas import is_character_supported, load_ttfont
target_text = 'Hello, 中文!'
font = load_ttfont("/path/to/your/font/OcrB-Regular.ttf")
for c in target_text:
status = is_character_supported(font, c)
# >>> Character '中' (0x4e2d) is not supported by the font.
# >>> Character '文' (0x6587) is not supported by the font.
設定影像尺寸
使用 output_size 參數可以調整影像尺寸。
from wordcanvas import WordCanvas
gen = WordCanvas(output_size=(64, 1024)) # 高度 64,寬度 1024
img = gen(text)
print(img.shape)
# >>> (64, 1024, 3)

當設定的尺寸小於文字圖像的尺寸時,會自動縮放文字圖像。
也就是說,文字會擠在一起,變成瘦瘦地長方形,例如:
from wordcanvas import WordCanvas
text = '你好' * 10
gen = WordCanvas(output_size=(64, 512)) # 高度 64,寬度 512
img = gen(text)

調整背景顏色
使用 background_color 參數可以調整背景顏色。
from wordcanvas import WordCanvas
gen = WordCanvas(background_color=(255, 0, 0)) # 藍色背景
img = gen(text)

調整文字顏色
使用 text_color 參數可以調整文字顏色。
from wordcanvas import WordCanvas
gen = WordCanvas(text_color=(0, 255, 0)) # 綠色文字
img = gen(text)

調整文字對齊
還記得剛才提到的影像尺寸嗎?
在預設的情況下,設定文字對齊是沒有意義的。繪製圖像時,必須讓文字影像有多餘的空間,才能看到對齊的效果。
使用 align_mode 參數可以調整文字對齊模式。
from wordcanvas import AlignMode, WordCanvas
gen = WordCanvas(
output_size=(64, 1024),
align_mode=AlignMode.Center
)
text = '你好! Hello, World!'
img = gen(text)
-
中間對齊:
AlignMode.Center
-
靠右對齊:
AlignMode.Right
-
靠左對齊:
AlignMode.Left -
分散對齊:
AlignMode.Scatter 提示
提示在分散對齊的模式中,不是每個字元都會分散開來,而是以單詞為單位進行分散。在中文中,單詞的單位是一個字;在英文中,單詞的單位是一個空格。
以上圖為例:輸入文字是 "你好! Hello, World!"。這個字串會被拆分為:
- ["你", "好", "!", "Hello,", "World!"]
並忽略空白後,再進行分散對齊。
另外,當輸入文字只能拆分出一個單詞的時候,中文單詞的分散對齊等價於置中對齊,英文單詞則會被拆分成單字後,再進行分散對齊。
這個部分我們使用的邏輯是:
def split_text(text: str):
""" Split text into a list of characters. """
pattern = r"[a-zA-Z0-9\p{P}\p{S}]+|."
matches = regex.findall(pattern, text)
matches = [m for m in matches if not regex.match(r'\p{Z}', m)]
if len(matches) == 1:
matches = list(text)
return matches注意這只是個很簡單的實現,不一定能滿足所有的需求。如果你有更完整拆分字串的解決方案,歡迎提供。
調整文字方向
使用 direction 參數可以調整文字方向。
-
輸出橫向文字
from wordcanvas import AlignMode, WordCanvas
text = '你好!'
gen = WordCanvas(direction='ltr') # 從右到左的橫向文字
img = gen(text)
-
輸出直向文字
from wordcanvas import AlignMode, WordCanvas
text = '你好!'
gen = WordCanvas(direction='ttb') # 從上到下的直向文字
img = gen(text)
-
輸出直向文字且分散對齊
from wordcanvas import AlignMode, WordCanvas
text = '你好!'
gen = WordCanvas(
direction='ttb',
align_mode=AlignMode.Scatter,
output_size=(64, 512)
)
img = gen(text)
調整輸出方向
使用 output_direction 參數可以調整輸出方向。
這個參數的使用時機是:當你選擇:「輸出直向文字」時,卻又希望可以用水平的方式查看文字圖像時,可以使用這個參數。
-
直向文字,水平輸出
from wordcanvas import OutputDirection, WordCanvas
gen = WordCanvas(
direction='ttb',
output_direction=OutputDirection.Horizontal
)
text = '你好!'
img = gen(text)
-
橫向文字,垂直輸出
from wordcanvas import OutputDirection, WordCanvas
gen = WordCanvas(
direction='ltr',
output_direction=OutputDirection.Vertical
)
text = '你好!'
img = gen(text)
壓扁文字
有些場景的文字會特別扁,這時候可以使用 text_aspect_ratio 參數。
from wordcanvas import WordCanvas
gen = WordCanvas(
text_aspect_ratio=0.25, # 文字高度 / 文字寬度 = 1/4
output_size=(32, 1024),
) # 壓扁文字
text="壓扁測試"
img = gen(text)

需要注意的是,當壓扁後的文字尺寸大於 output_size 時,圖像會進入自動縮放的流程。因此,你可能壓扁了圖像,卻又被縮放回來,結果什麼事情都沒發生。
文字外框
使用 stroke_width 參數可以調整文字外框的寬度。
from wordcanvas import WordCanvas
gen = WordCanvas(
font_size=64,
text_color=(0, 0, 255), # 紅色文字
background_color=(255, 0, 0), # 藍色背景
stroke_width=2, # 外框寬度
stroke_fill=(0, 255, 0), # 綠色外框
)
text="文字外框測試"
img = gen(text)

使用 stroke_width 會收到警告:
Using `stroke_width` may cause an OSError: array allocation size too large error with certain text.
This is a known issue with the `Pillow` library (see https://github.com/python-pillow/Pillow/issues/7287) and cannot be resolved directly.
因為我們在測試中發現,在 Pillow 內使用 stroke_width 會不定期出現 OSError 的錯誤。這是 Pillow 的一個已知問題,我們把相關的 issue 連結放在了警告中,你可以點擊查看。
多行文字
使用 \n 換行符號可以實現多行文字。
from wordcanvas import WordCanvas
gen = WordCanvas()
text = '你好!\nHello, World!'
img = gen(text)

在多行文字的情況中,可以和上述大部分的功能進行搭配,例如:
from wordcanvas import WordCanvas, AlignMode
gen = WordCanvas(
text_color=(0, 0, 255), # 紅色文字
output_size=(128, 512), # 高度 128,寬度 512
background_color=(0, 0, 0), # 黑色背景
align_mode=AlignMode.Center, # 中間對齊
stroke_width=2, # 外框寬度
stroke_fill=(0, 255, 0), # 綠色外框
)
text = '你好!\nHello, World!'
img = gen(text)

以下幾種情況不支援多行文字:
-
align_mode不支援AlignMode.Scattergen = WordCanvas(align_mode=AlignMode.Scatter) -
direction不支援ttbgen = WordCanvas(direction='ttb')
如果你需要這些功能,請不要使用多行文字。
儀表板
基礎功能大致上就是這樣。
最後我們介紹一下儀表板的功能。
from wordcanvas import WordCanvas
gen = WordCanvas()
print(gen)
你也可以不需要 print,直接輸出就好,因為我們有實作 __repr__ 方法。
輸出後可以看到一個簡單的儀表板。
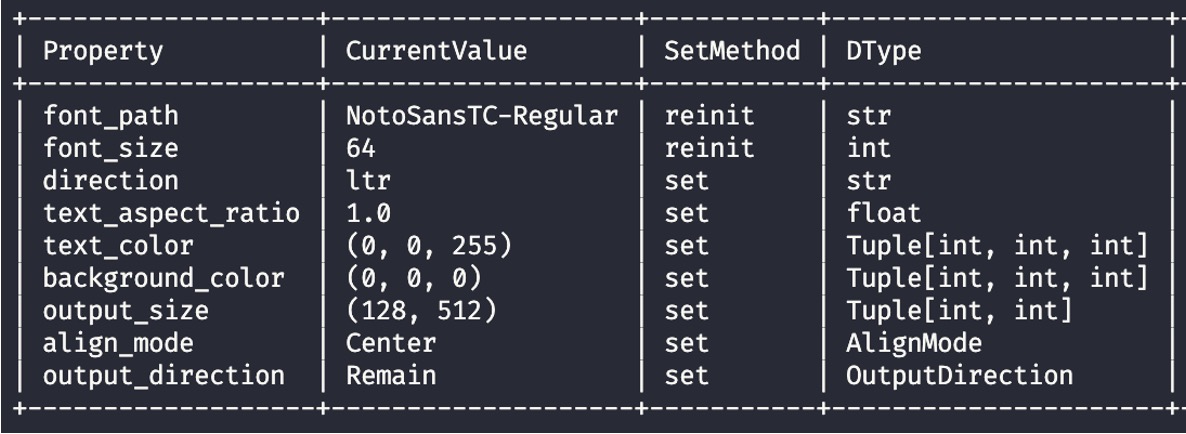
你可以看到:
- 第一個 column 是 Property,是所有的設定參數。
- 第二個 column 是 Current Value,是參數「此時此刻」的值。
- 第三個 column 是 SetMethod,是參數的設定方法。
set的參數,可以直接指定修改;reinit的參數,需要重新初始化WordCanvas物件。
- 第四個 column 是 DType,是參數的資料型態。
- 第五個 column 是 Description,是參數的描述。(上圖中沒有顯示,節省空間)
大部分的參數可以直接設定,這表示當你需要修改輸出特性時,不需要重新建立一個物件,直接改設定就好。會需要使用 reinit 的參數,通常是涉及到字型格式的初始化,例如文字高度 font_size 之類的。
gen.output_size = (64, 1024)
gen.text_color = (0, 255, 0)
gen.align_mode = AlignMode.Center
gen.direction = 'ltr'
gen.output_direction = OutputDirection.Horizontal
設定完之後,直接調用,就可以得到新的文字圖像。另外,如果你直接更改了 reinit 相關的參數,則會收到對應的錯誤:
-
AttributeError: can't set attribute
gen.font_size = 128
# >>> AttributeError: can't set attribute
當然,你還是可以強硬地進行參數設定,同樣身為 Python 使用者,我阻止不了你:
gen._font_size = 128
但是這樣在後續出圖的時候會出錯呀!
不要堅持,重新初始化一個物件吧。
小結
還有許多功能沒有提到,但是基本功能已經介紹完畢。
以上就是本專案的基本使用方法,我們下一章節會介紹進階功能。