[21.07] YATR

偽りのデータは信じられない
Why You Should Try the Real Data for the Scene Text Recognition
STR 領域では、ほとんどのモデルが合成データから始まります。
標準的な方法は、まず合成データで事前訓練を行い、その後、検証データセットで直接評価を行うか、少量の実データで微調整を行ってから評価を行うことです。
問題の定義
実データの重要性は誰も否定しません。なぜなら、合成データは特定の生成ルールに基づいており、特定のフォントの選択やノイズの追加、背景の選定が含まれるからです。
ルールがあれば例外もありますが、これらの例外は合成データではカバーできないことがあり、その結果、モデルの汎化能力に影響を与える可能性があります。そして、実世界においては、合成データこそが例外であり、実データこそがルールです。
例外を使ってルールを適合させ、そしてそのモデルが優れた汎化能力を持っていると言われても、あなたは信じられますか?
この論文の著者は、合成データと実データを組み合わせることが最良の訓練データであると考えています。
問題の解決
モデルアーキテクチャ
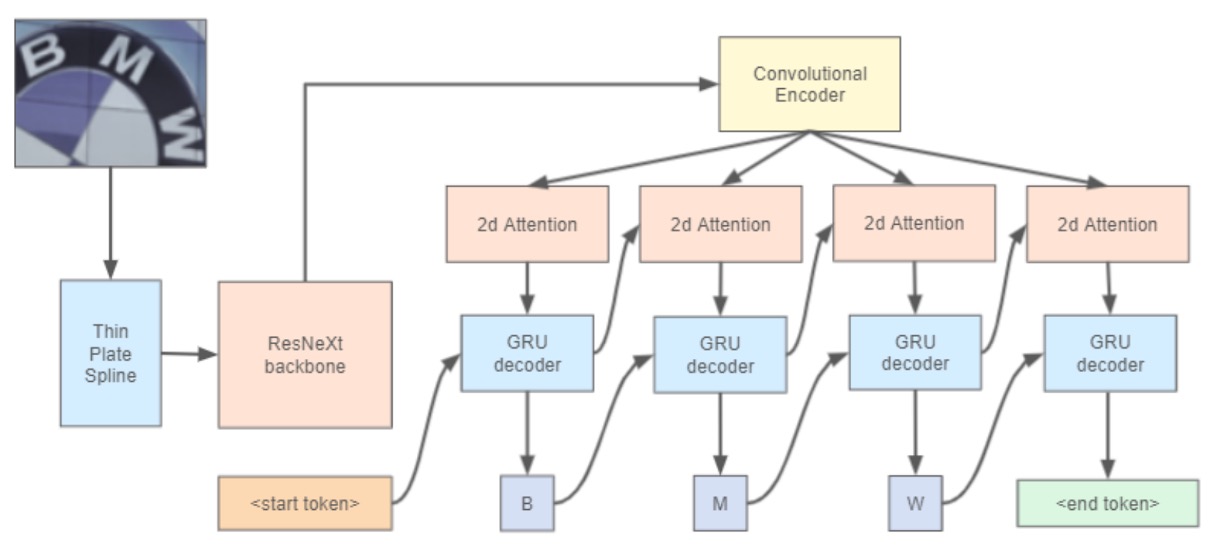
著者は WWWSTR の方法を参考にしました:
ただし、最終段階の 2 つのフェーズを分けず、テキスト認識の最終段階にシーケンスモデリングと最終予測を含めています。
画像補正部分では ASTER の Thin Plate Spline (TPS)技術を使用しています:
TPS の空間変換機構は 3 つの部分に分かれています:
- 位置ネットワーク:最初に入力画像から空間変換パラメータを生成します。
- グリッド生成器:予測されたパラメータを基にサンプリンググリッドを生成し、入力画像のサンプリング位置を指定して変換後の出力を生成します。
- サンプラー:グリッドと入力画像を使用して最終的な出力画像を生成します。
TPS 設計の利点は、文字ごとのアノテーションが不要であり、さまざまなテキスト認識アーキテクチャに直接使用でき、パラメータはエンドツーエンドで学習できます。
バックボーン部分では ResNeXt-101 を使用しています。これは ResNet のバリエーションで、より優れた表現力を持っています。
最後に、テキスト認識ヘッドでは 2D 注意マップと GRU をデコーダとして使用しています。
この論文はアーキテクチャに関して新しい提案はなく、主に訓練データの重要性を論じています。
討論
実データの重要性
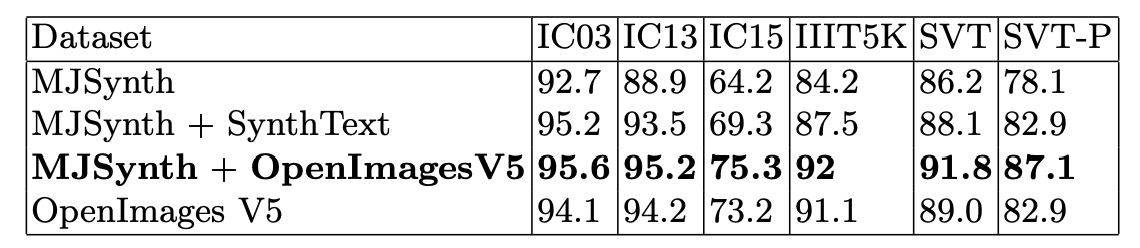
著者は合成データセットと実データセットを使用して訓練を行い、すべての実験は同じ条件下で行われました:ResNeXt-101 をバックボーンネットワークとして使用し、大文字と小文字を区別しない訓練とテストモード、そして TPS モジュールは使用しませんでした。
結果は上の表の通りで、合成データセットのみでは堅牢なテキスト認識モデルを訓練できないことが分かります。実データセットのみで訓練すると、全体的な認識精度が低下しました。著者はこれが実データセットの方が挑戦的であり、モデルがより長い訓練サイクルを必要とするためだと考えています。
最良の実験結果は MJSynth + OpenImagesV5 であり、これが著者が提案する最適な訓練データセットの組み合わせです。
ViTSTR を試してみよう
実データの重要性を確認するために、著者は ViTSTR を使用して実験を行いました。ViTSTR は Transformer ベースのテキスト認識モデルです。
この論文でも触れていますので、参考にしてください:
著者は合成データセットと実データセットを使って訓練し、結果は以下の表に示されています:

実験結果から、実データセットで訓練した ViTSTR モデルはすべての指標で顕著に改善されており、各検証データセットで約 5%の精度向上が見られました。元々の ViTSTR の論文では多くの画像強化技術を使用していましたが、実データの欠如を補うには至りませんでした。
結論
合成データと実データを組み合わせることで、テキスト認識モデルの汎化能力を向上させることができます。
このことは常識だと思うかもしれませんが、具体的にどれだけの違いがあるのかを示すことは難しいです。
今後、もし誰かが「なぜ実データを使うのか?どれだけ差があるのか?」と聞いてきたら、この論文を使ってその質問に答えることができるでしょう。