[24.05] DeepSeek-V2

開源節流
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
以前の論文では MoE の効果を試す予定が述べられており、3 ヶ月も経たないうちにこの論文が登場しました。
この論文は 52 ページに及び、大量の実験データと技術的詳細が含まれていますので、いつも通り重要なポイントを取り上げます。
数学警告:本論文の主な焦点はモデルモジュールの最適化にあり、その中には大量の数学が含まれていますので、慎重に読んでください。
問題の定義
近年、大規模な言語モデルの急速な発展に伴い、パラメータ数の増加は確かにモデルの能力を著しく向上させ、いくつかの「出現能力」を示し、汎用人工知能に向けての希望を見出しました。
しかし、この向上には膨大な計算資源の消費が伴い、トレーニングコストが非常に高く、推論時にも計算とメモリのボトルネックによって効率が低下し、これらのモデルの実際のアプリケーションへの普及と展開が影響を受けています。
そのため、DeepSeek 研究チームは計算ボトルネックと効率性の問題に焦点を当て、DeepSeek-V2 モデルを提案しました。このモデルは、強力なパフォーマンスを維持しながら、計算効率を向上させ、トレーニングと推論コストを削減することを目指しています。
問題の解決
DeepSeek-V2 は引き続き標準の Transformer 構造を採用しており、各 Transformer ブロックには注意機構と前向きネットワーク(FFN)が含まれています。
- 注意機構:研究チームは MLA(Multi-head Latent Attention)を提案し、低ランクのキー・バリュー結合圧縮を用いて、従来の MHA が生成時に直面する KV キャッシュのボトルネック問題を解決しました。
- 前向きネットワーク:DeepSeekMoE 構造を採用しており、コストを抑えつつ強力なモデルをトレーニングする高性能な Mixture-of-Experts モデルです。
その他の詳細(Layer Normalization や活性化関数など)は、DeepSeek 67B の設定を踏襲しており、全体の構造設計は以下の図の通りです:
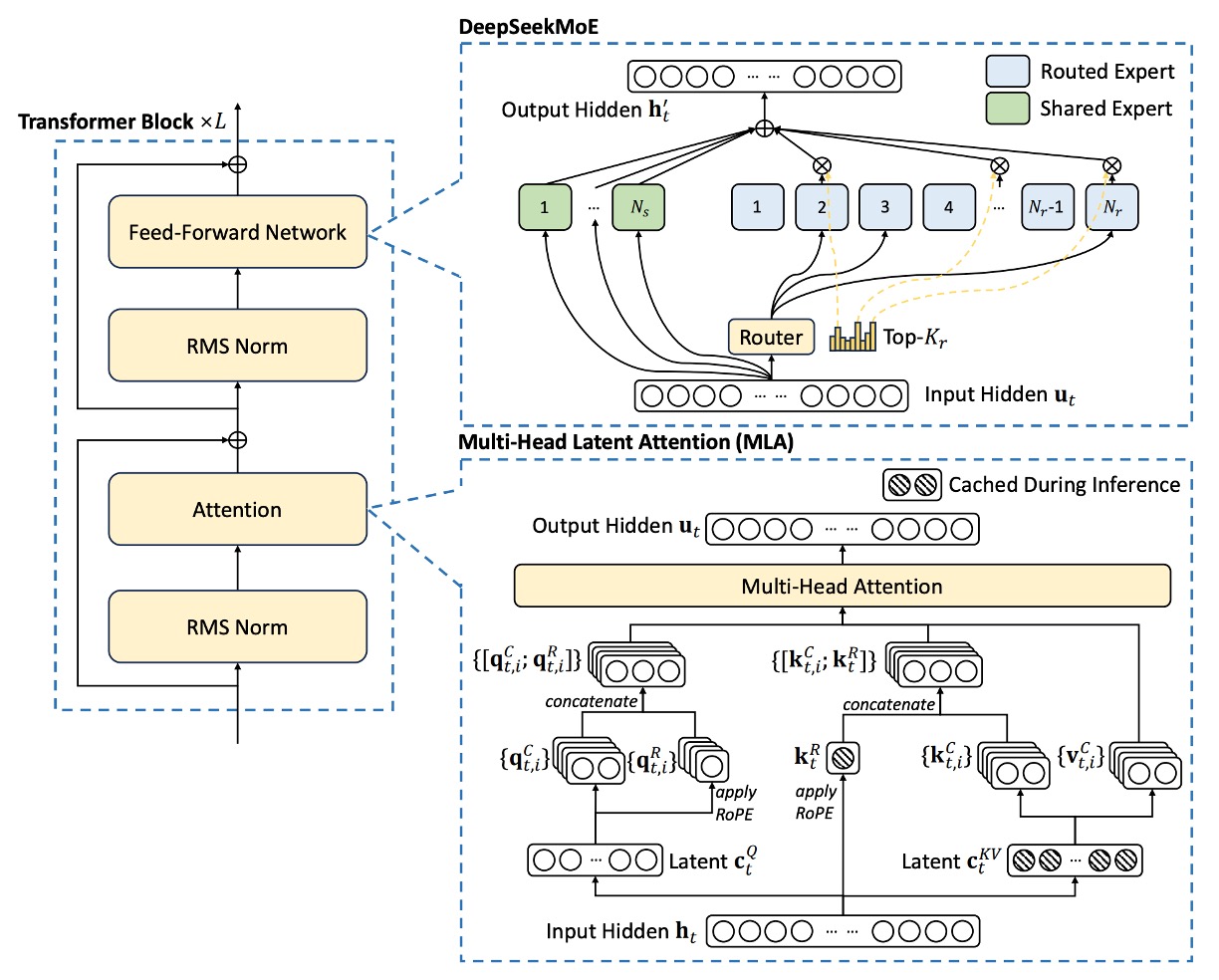
Multi-head Latent Attention
標準の多頭注意機構(MHA)では、以下のように仮定します:
- :埋め込み次元
- :注意ヘッド数
- :各ヘッドの次元
- :t 番目のトークンの入力表現
3 つの投影行列、、を使って、それぞれクエリ(query)、キー(key)、値(value)を計算します:
次に、これらのベクトルは個のヘッドに分割され、次のように表されます:
各ヘッドで注意計算を行います:
最終的に出力投影行列を使って、各ヘッドの出力を組み合わせます:
ここまでが標準的な MHA の計算プロセスです。
しかし、問題は推論段階で、計算を高速化するためにすべてのキーと値をキャッシュする必要があり、これにより各トークンは個の要素を保存しなければならなくなります。シーケンス長が大きくなると、メモリ消費が二乗的に増加し、深刻なボトルネックとなります。
したがって、MLA の核心は「低ランク圧縮」技術を利用して KV キャッシュを削減することにあります。
具体的な手順は以下の通りです:
-
キー・バリュー圧縮:各トークンについて、その圧縮後の潜在表現を計算します:
ここで、、であり、は下方向の投影行列です。
-
上方向投影によるキーと値の復元:圧縮された表現からキーと値を復元します:
ここで、とはキーと値の上方向の投影行列で、そのサイズはです。
推論時には、のみをキャッシュすればよく、各トークンは個の要素のみを保存することで、メモリ消費を大幅に削減できます。
また、はと統合して吸収でき、はと統合して吸収できるため、実際の注意計算ではキーと値を別途計算する必要はありません。
最後に、トレーニング時の活性化メモリを削減するために、研究チームはクエリベクトルにも同様の低ランク圧縮を実施しました:
ここで、はクエリの圧縮表現で、です。
解耦旋回位置埋め込み
Rotary Position Embedding(RoPE)は、Transformer に位置情報を導入する方法の一つであり、キーとクエリの両方が位置に敏感であるという特徴があります。低ランク圧縮の場合、もし圧縮後のキーに RoPE を直接適用すると、上投影行列と位置情報が結びつき、前に行った吸収合併最適化を破壊してしまいます。その結果、推論時には前のトークンに対してキーを再計算しなければならなくなります。
ちょっと、これどういう意味か分からない?
大丈夫、簡単にしましょう。例えば、10 人の名前を 1 つの名前に圧縮する場合を考えてみてください。
最初、10 人の名前(例えば「小明、阿華、小美、阿強……」)にはそれぞれ順番がありました。スペースを節約するために、これら 10 人の名前を 1 つにまとめて「明華美強……」という名前に圧縮することにしました。これをすることで、メモリの使用を減らし、管理が簡単になります。
しかし、もしこの圧縮後の名前に元々の順番の情報を付け加えると、その名前と位置情報が密接に結びついてしまいます。
結果として、もし新しい名前を追加したり、前の名前の順番を確認したりするたびに、圧縮された名前を一度分解して、元の順番を再計算しなければならなくなります。これでは、最初に圧縮したメリットが失われ、後の処理が煩雑になってしまいます。
Transformer で RoPE を使うのは、このような状況に似ています。RoPE はキーとクエリに位置情報を追加するための方法ですが、もし既に圧縮された(低ランク圧縮された)キーに RoPE を適用すると、圧縮された名前に位置情報を加えるようなものです。こうなると、上投影行列(後続処理ツール)は位置情報と絡み合ってしまい、推論時に新しいトークンが追加されるたびに、前のすべてのトークンのキーを再計算しなければならなくなります。これでは効率が低下し、最初の圧縮による利便性が損なわれます。
研究チームはここで、RoPE の位置情報を解耦する戦略を提案しています。具体的な方法は次の通りです:
RoPE の位置情報を持つために、追加の多頭クエリと共有のキーを導入します。
次に、それぞれを計算します:
ここで、 と は、解耦されたクエリとキーを生成するための行列です。
最終的に、圧縮部分と解耦部分を接続します:
そして、注意計算を行います:
最後に、を使って各ヘッドの出力を組み合わせます:
この設計により、RoPE の位置情報と低ランク圧縮部分が解耦され、位置埋め込みの利点を保持しつつ、前の吸収行列の最適化を損なうことなく、推論プロセスで前のトークンのキーを再計算する必要がなくなります。
DeepSeekMoE
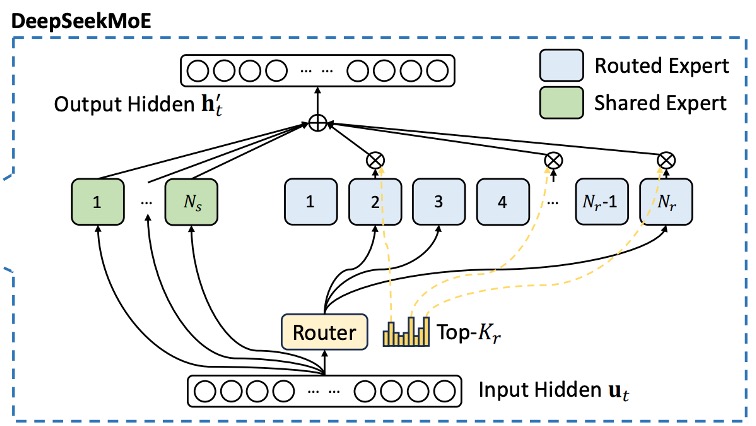
従来の MoE モデルとは異なり、DeepSeekMoE は専門家をより細かく分割します:FFN モジュールを 2 つの部分に分けます。
- 共有専門家(Shared Experts):固定数の専門家で、各トークンはこの部分の知識を利用します。
- ルーティング専門家(Routed Experts):動的に一部の専門家を選択して計算に参加させます。
番目のトークンに対して、その FFN 入力はであり、最終的な FFN 出力は以下のように定義されます:
ここで:
- は共有専門家の数、
- はルーティング専門家の数、
- とは、それぞれ第個の共有専門家とルーティング専門家の前向き計算を表します。
ルーティング専門家の選択は、以下のようなゲーティング機構に依存します:
ここでは活性化されたルーティング専門家の数、はトークンと第個のルーティング専門家との親和スコアで、計算方法は以下の通りです:
ここでは第個のルーティング専門家の「中心」ベクトルを示し、その専門家の特徴の中心を表します。
MoE モデルでは、専門家が複数のデバイスに分散されている場合、各トークンのルーティング決定にはデバイス間通信が必要になることがあります。もし活性化された専門家が多い場合、追加の通信コストが発生します。このコストを管理するために、DeepSeekMoE はデバイス制限付きルーティングメカニズムを採用しています:
- 各トークンについて、まず全てのデバイスから個の最も高い親和スコアを持つデバイスを選びます。
- 次に、その個のデバイス内で Top-K 専門家を選択します。
実験結果によると、の場合、この制限はデバイス間通信を大幅に削減し、制限なしの Top-K 選択と同等のパフォーマンスを達成できることが確認されました。
この戦略の核心は、モデルのルーティング品質とデバイス間の通信負担をバランスよく調整することで、大規模分散環境において高い計算効率を実現することにあります。
Mixture-of-Experts(MoE)にあまり馴染みがない方は、以前のノートを参考にしてください:
補助バランス損失
MoE モデルでは、特定の専門家が過剰に活性化される(または完全に使用されない)問題が発生しやすく、これが「ルーティング崩壊」を引き起こすだけでなく、計算効率も低下させます。これに対処するために、DeepSeekMoE は負荷均衡を促進するための 3 つの補助的な損失関数を設計しました:
-
専門家レベルのバランス損失(Expert-Level Balance Loss)
ここで、
- はシーケンス内のトークンの総数、
- は指示関数、
- は損失の重みを調整するためのハイパーパラメータです。
この損失関数は、各ルーティング専門家の活性化頻度と平均親和スコアがバランスを保つように設計されています。
-
デバイスレベルのバランス損失(Device-Level Balance Loss)
すべてのルーティング専門家を組(各は同じデバイス上に配置)に分け、損失を次のように定義します:
ここで、
- はデバイスレベルのバランスのためのハイパーパラメータです。
これは、異なるデバイス間で計算負荷のバランスを取るために役立ち、特定のデバイスが過負荷になりボトルネックになるのを防ぎます。
-
通信バランス損失(Communication Balance Loss)
デバイス制限付きルーティングを採用しても、特定のデバイスが他のデバイスよりも多くのトークンを受信する場合、通信効率に影響を与える可能性があるため、次の損失関数を導入します:
ここで、
- は通信バランスのためのハイパーパラメータです。
この設計は、各デバイス間の通信量が近くなるように促し、デバイス間での計算調整効率を向上させます。
最後に、バランス損失に加えて、研究チームはデバイスレベルのトークン廃棄戦略を導入し、負荷不均衡による計算浪費をさらに軽減しました。具体的な方法は次の通りです:
- 各デバイスの平均計算予算を計算し、各デバイスの容量係数が 1.0 になるようにします。
- 各デバイス上で親和スコアが最も低いトークンを廃棄し、計算予算に達するまで続けます。
- トレーニングシーケンスの約 10%に該当するトークンは、決して廃棄されないようにします。
これにより、推論過程でトークンを廃棄するかどうかを効率要件に応じて柔軟に決定でき、トレーニングと推論の一貫性を常に保つことができます。
訓練戦略
論文では、DeepSeek 67B と同じデータ処理フローが保持されていますが、以下の改善が行われました:
- データ量の拡大: データクリーンアッププロセスを最適化し、以前に誤って削除された大量のデータを復元しました。
- データ品質の向上: より多くの高品質なデータ、特に中国語のデータ(中国語のトークンは英語より約 12%多い)を追加しました。同時に、品質に基づくフィルタリングアルゴリズムも改善され、大量の無駄な情報を除去し、価値のあるコンテンツを保持しました。
- 論争的なコンテンツのフィルタリング: この戦略は、特定の地域文化からの偏見を減らすことを目的としています。
Tokenizer は DeepSeek 67B と同じ Byte-level Byte-Pair Encoding(BBPE)アルゴリズムを使用し、語彙サイズは 100K に設定され、最終的な事前学習コーパスは 8.1T トークンを含んでいます。
モデルのハイパーパラメータ設定は次の通りです:
- Transformer 層数:60 層
- 隠れ層の次元:5120
- すべての学習可能なパラメータのランダム初期化時の標準偏差は 0.006 に設定
- MLA 関連:
- 注意ヘッド数は 128 に設定
- 各ヘッドの次元は 128
- KV 圧縮次元は 512
- クエリ圧縮次元は 1536
- 解耦されたクエリとキーの各ヘッド次元は 64
MoE 層の設定は次の通りです:最初の層を除き、残りの FFN 層はすべて MoE 層に置き換えられています。
- 各 MoE 層には 2 つの共有専門家と 160 のルーティング専門家が含まれています
- 各専門家の中間隠れ次元は 1536
- 各トークンは 6 つのルーティング専門家を活性化
- 低ランク圧縮と細粒度な専門家分割が層出力に与える影響に対応するため、論文では RMS Norm 層と追加のスケーリングファクターを導入し、訓練の安定性を確保
最終的に、DeepSeek-V2 の総パラメータ数は 236B に達しますが、各トークンで活性化されるパラメータは 21B にとどまります。
訓練のハイパーパラメータは次の通りです:
- オプティマイザ:AdamW、ハイパーパラメータ、、weight_decay=0.1
- 学習率スケジューリング:最初の 2000 ステップで線形増加、その後、予め定めた割合(約 60%と 90%のトークン数)でそれぞれ 0.316 を掛ける、最大学習率 2.4×10⁻⁴
- 勾配クリッピングは 1.0 に設定
- バッチサイズは段階的に調整され、2304 から 9216 に増加、その後は 9216 を維持
- 最大シーケンス長は 4K に設定し、8.1T トークンで訓練
- その他の並列化設定:
- パイプライン並列化を利用して異なる層を異なるデバイスにデプロイ
- ルーティング専門家は 8 つのデバイスに均等にデプロイ()
- デバイス制限付きルーティングは各トークンが最大 3 台のデバイスに送信されるように設定()
- 補助バランス損失のハイパーパラメータはそれぞれ、、に設定
- 訓練中にトークン廃棄戦略を使用して加速し、評価時にはトークンを廃棄しない
初期事前学習が完了した後、研究チームは YaRN メソッドを使用して、モデルのデフォルトのコンテキストウィンドウを 4K から 128K に拡張しました。
特に、RoPE を運ぶための解耦共有キーに対して拡張を行い、パラメータを次のように設定しました:スケール、、、最大コンテキスト長は 160K に設定されました。
ユニークな注意機構に適応するため、長さスケーリングファクターを調整し、の計算式は次のように設定しました:
これにより、perplexity の最小化を目指しました。
長いコンテキストの拡張段階では、追加で 1000 ステップ訓練し、シーケンス長を 32K に設定、バッチサイズを 576 シーケンスに設定しました。訓練時は 32K の長さを使用しましたが、評価時には 128K のコンテキスト長で強力な性能を発揮しました。「Needle In A Haystack」(NIAH)テストによると、モデルはさまざまなコンテキスト長で良好なパフォーマンスを示しました。
モデルのアライメント
モデルが人間の好みにより適合し、回答の正確性と満足度を向上させるために、著者は強化学習を用いた調整を行いました。ここで使用されているのは、Group Relative Policy Optimization(GRPO)アルゴリズムであり、その主な利点はトレーニングコストの節約です。なぜなら、このアルゴリズムでは、戦略モデルと同じ規模の批評家モデルを必要とせず、代わりにグループスコアを用いてベースラインを推定します。
強化学習のトレーニング戦略は 2 つの段階に分かれています:
-
第一段階:推論アライメント(Reasoning Alignment)
この段階では、著者はプログラミングや数学などの推論タスクに特化した報酬モデル をトレーニングします:
これにより、モデルはこの種のタスクにおいて問題解決能力を向上させ続けることができます。
-
第二段階:人間の好みアライメント(Human Preference Alignment)
この段階では、複数の報酬フレームワークが使用され、3 つの側面から報酬を得ます:
- 助けとなる報酬モデル
- 安全性報酬モデル
- 規則ベース報酬モデル
最終的に、ある応答 に対する報酬値は次のように計算されます:
ここで はそれぞれの係数です。この多報酬設計により、モデルは応答を生成する際に複数の品質指標を同時に考慮することができます。
信頼性のある報酬信号を得るために、研究チームは大量の好みデータを収集しました:
- プログラミングタスクの好みデータはコンパイラのフィードバックに基づいています。
- 数学タスクのデータは実際のラベルに基づいています。
報酬モデルの初期化には、DeepSeek-V2 Chat (SFT) の結果が使用され、ペアワイズ損失またはポイントツーポイント損失を用いて訓練されました。
討論
篇幅の関係で、ここでは AlignBench の結果を見てみましょう。その他の実験結果に興味がある方は、元の論文を参照してください。
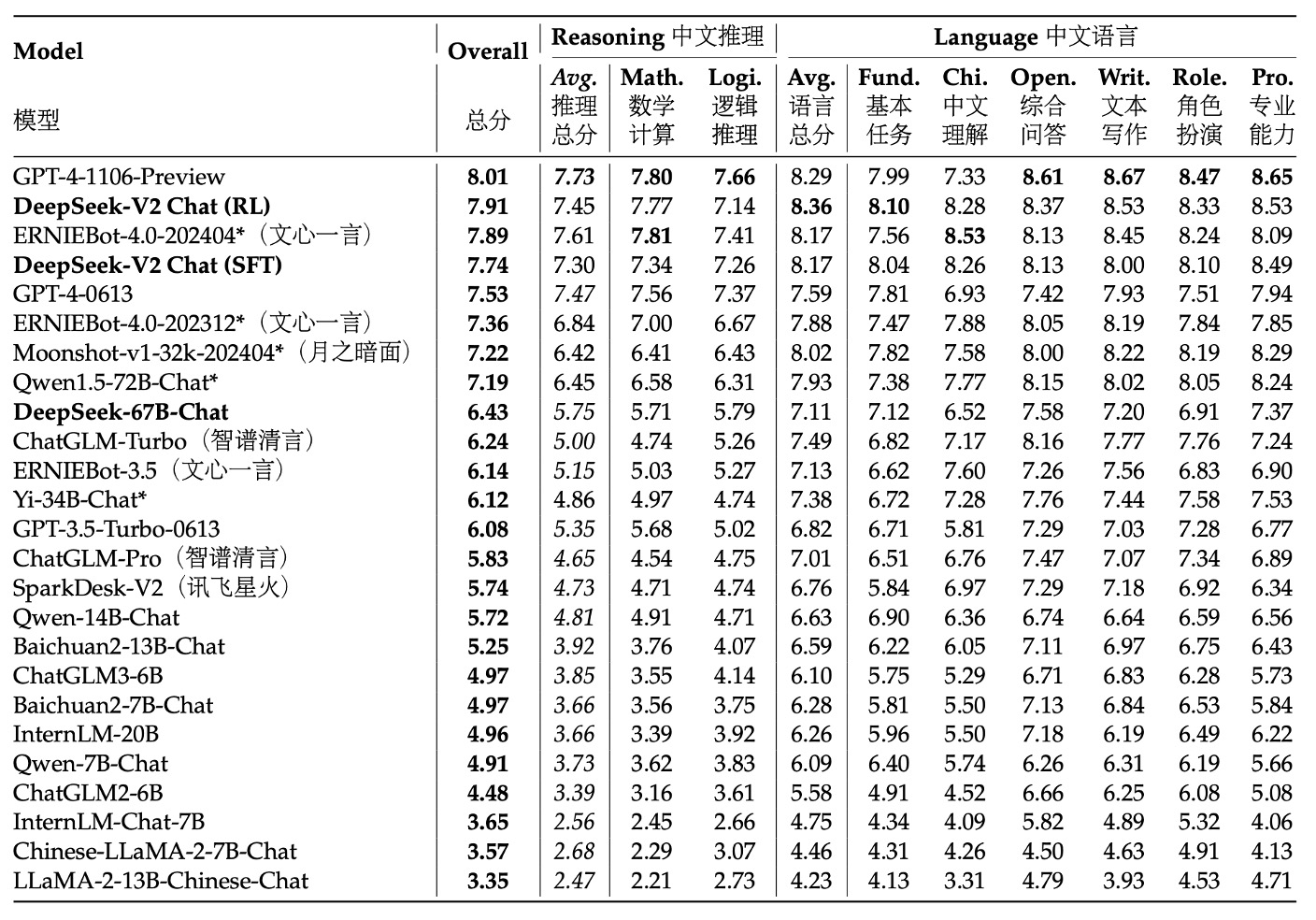
表は、AlignBench での各モデルの総合的なパフォーマンスに基づいた得点順に並べられています。得点が高いモデルほど上位にランクインしており、これが中国語での対話生成や理解などのタスクにおける総合的な能力を反映しています。評価は GPT-4‑0613 によって行われ、この強力なモデルが基準として使用され、各モデルの生成結果の品質とコンテキストの関連性が測定されました。
実験結果によると、中国語生成タスクにおいて、DeepSeek‑V2 Chat (RL)は(SFT)よりわずかに優れており、すべての他のオープンソースの中国語モデルを大きく上回っています。特に中国語の推論と語学能力においては、2 位の Qwen1.5 72B Chat を大きく凌駕しています。
中国語理解能力においては、DeepSeek‑V2 Chat (RL)は GPT‑4‑Turbo‑1106‑Preview を超える性能を発揮しています。しかし、推論能力においては、DeepSeek‑V2 Chat (RL)は一部の巨大モデル(例:Erniebot‑4.0 や GPT‑4)に対して劣っています。
これらの評価結果は、DeepSeek‑V2 Chat モデルが異なる調整戦略において優れたパフォーマンスを示すことを示しています。RL 微調整を通じて、英語対話生成において顕著な優位性を発揮し、中国語理解においても非常に高い水準を示していますが、いくつかの推論タスクにはまだ改善の余地があります。これにより、このモデルは高品質で指示的な対話生成において強い競争力を持つことが確認され、今後の改善方向も明確になりました。
結論
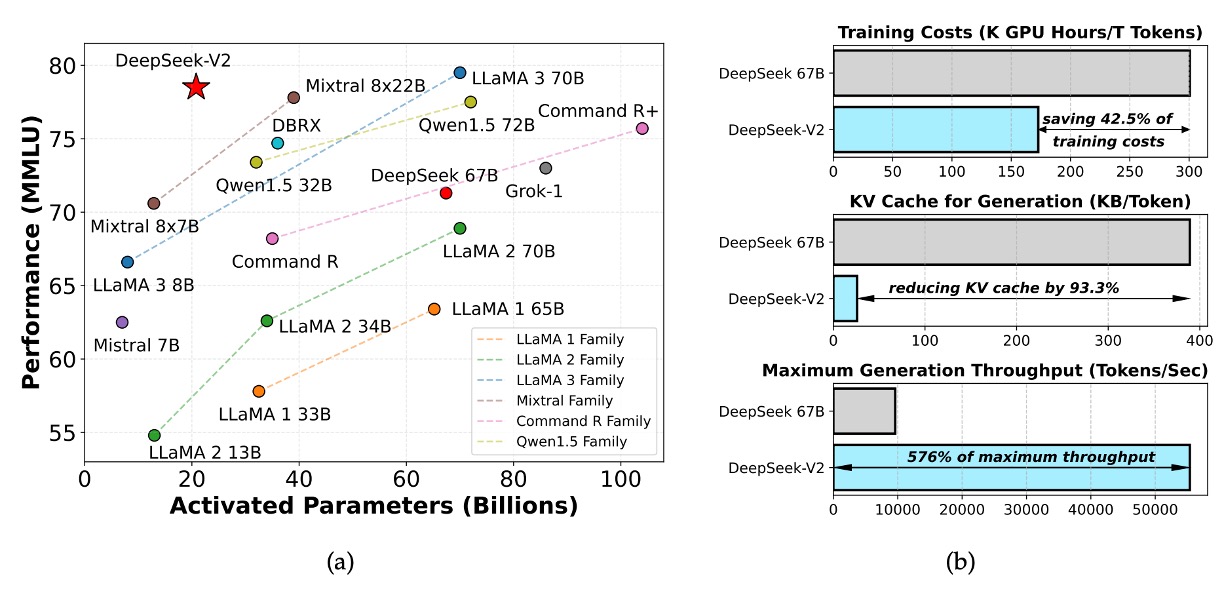
DeepSeek‑V2 は MoE アーキテクチャに基づいた大規模言語モデルで、最大 128K のコンテキスト長をサポートします。
このモデルは次の 2 つの革新的な技術を活用しています:
- Multi-head Latent Attention: 低ランクのキー・バリュー結合圧縮を通じて、推論時の KV キャッシュの要求を大幅に削減し、推論効率を向上させました。
- DeepSeekMoE: 細粒度な専門家分割と共有専門家の設計を通じて、低コストで強力なモデルを訓練する目標を達成しました。
前のバージョン DeepSeek LLM 67B と比較して、DeepSeek‑V2 は以下の点で優れています:
- トレーニングコストは 42.5%削減
- KV キャッシュは 93.3%削減
- 生成スループットは 5.76 倍向上
全体のパラメータ数は 236B に達しますが、各トークンで活性化されるパラメータは 21B にとどまり、モデルは経済性とパフォーマンスの間で優れたバランスを達成しています。これにより、現在のオープンソース MoE モデルの中で最強のパフォーマンスを持つモデルの 1 つとなっています。