[14.09] VGG

深い、さらに深く
Very Deep Convolutional Networks for Large-Scale Image Recognition
神経ネットワークの初期において、深さに関する研究は長い間停滞していました。
その主な原因は、勾配消失問題にあり、ネットワークの深さが増すにつれて、勾配の情報が早期の層にうまく伝達されず、訓練が困難になるためです。
そのため、AlexNet の後、研究者たちはネットワークの深さを探求し、いくつかの深層ネットワーク構造が提案されました。その中でも VGG は重要な代表の 1 つです。
問題の定義
過去の研究では、畳み込みカーネルのサイズは通常 5×5 または 7×7 でしたが、VGG は複数の 3×3 の畳み込みカーネルを使うことを提案しました。著者は「多層」の小さな畳み込みカーネルを使うことが「少層」の大きな畳み込みカーネルを使うよりもいくつかの明確な利点があると考えました:
-
決定関数の識別能力を向上させる:
複数の小さな畳み込みカーネル(例えば 3×3)を積み重ね、各層に非線形活性化関数(ReLU など)を導入することで、モデルの非線形表現能力を増加させます。これにより、決定関数がより識別的になり、単一の大きな畳み込みカーネル(例えば 7×7)に比べて、データ中の複雑な特徴をより効果的に捉えることができます。
-
パラメータ数の削減:
入力と出力が C チャンネルである場合、3×3 の畳み込みを 3 層積み重ねた場合の必要なパラメータ数は次のようになります:
一方、1 層の 7×7 の畳み込みに必要なパラメータ数は:
- です。
これは、複数の小さな畳み込みカーネルを積み重ねることで、1 層の大きな畳み込みカーネルに比べて約 81%のパラメータ数を削減でき、モデルの計算とストレージのコストを減らすことができることを意味します。
-
有効受容野の増加:
複数の小さな畳み込みカーネルを積み重ねることで、有効受容野を層ごとに増加させることができます。
2 層の 3×3 畳み込みの積み重ねでは 5×5 の有効受容野が、3 層の 3×3 畳み込みの積み重ねでは 7×7 の有効受容野を持ちます。
したがって、畳み込み層の数を増加させることで、有効受容野を調整することができ、より大きな畳み込みカーネルを使用する必要はありません。
-
正則化効果:
複数の小さな畳み込みカーネルを積み重ねることは、正則化に似た効果があります。大きな畳み込みカーネルを複数の小さなカーネルに分解することによって、モデルはより細かな特徴表現を学習することを強制され、過学習を減少させることができます。
-
より多くの非線形性の導入:
1×1 の畳み込み層は本質的に線形投影ですが、非線形活性化関数と組み合わせることで、畳み込みの受容野を変更することなくモデルの非線形性を増加させることができます。
多層の小さな畳み込みカーネルは、一定の正則化効果をもたらすため、ネットワークの深さを自然に増加させることができます。これらを基にして、著者は VGG ネットワーク構造を提案し、多層小畳み込みカーネルを積み重ねて深層ネットワークを構築し、ImageNet 分類タスクで優れた性能を達成しました。
欠点もあります:
多層小畳み込みカーネルを積み重ねることでパラメータ数は削減できますが、それに伴い計算層数と計算の複雑さが増します。さらに、深層ネットワークでは、多層小畳み込みカーネルの積み重ねが勾配消失問題を悪化させる可能性があり、特に適切な初期化や正則化技術が不足していると、訓練がより困難になります。
また、層数が増えることで、各層の中間特徴マップを保存する必要があり、これが特に高解像度画像を処理する際にメモリ要求を増加させる可能性があります。
問題の解決
ネットワークアーキテクチャ
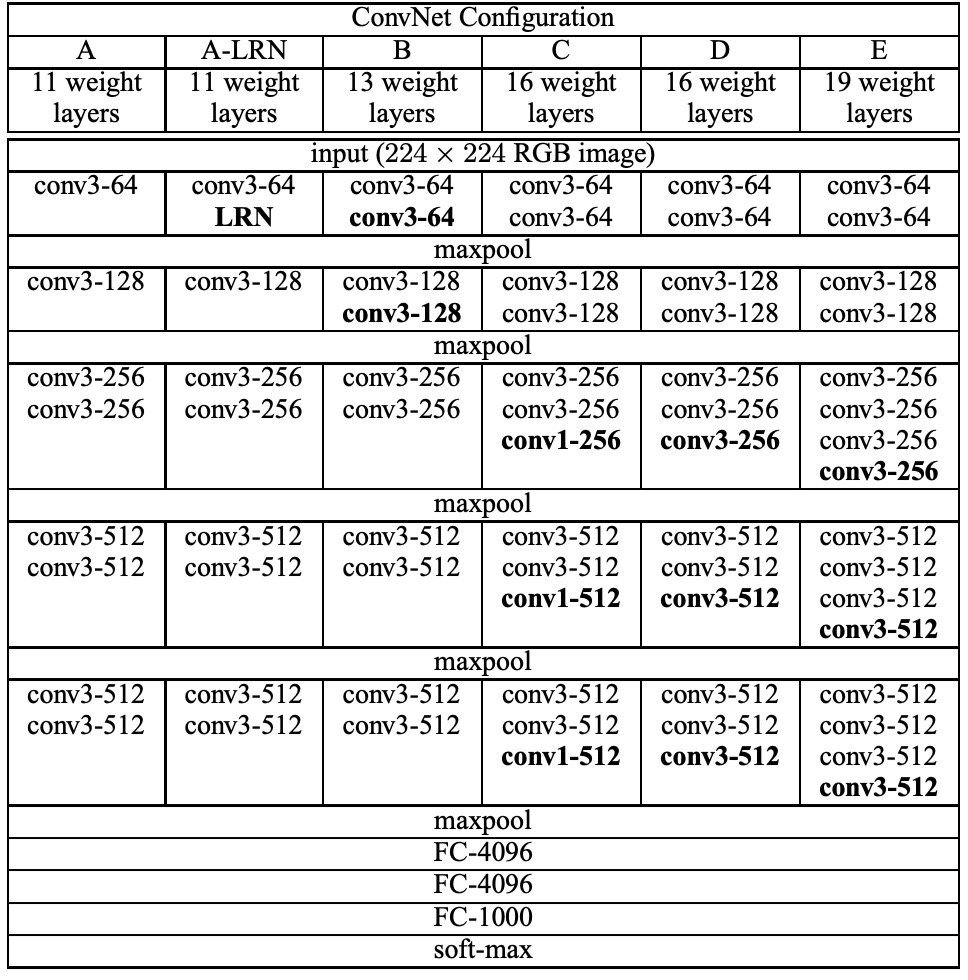
著者は 5+1 組の実験を設計し、そのうち A と A-LRN は AlexNet における LRN の効果を探るため、B、C、D、E の 4 組はネットワークの深さが分類効果に与える影響を調査するために使用されました。
訓練中、ConvNet の入力は固定サイズの 224×224 RGB 画像です。唯一の前処理は、各ピクセルから訓練セットで計算された平均 RGB 値を引くことです。
著者は非常に小さな受容野を持つフィルタを使って畳み込みを行いました:3×3(および一部の設定で 1×1)。畳み込みのストライドは 1 ピクセルに固定され、空間的なパディングが行われ、畳み込み後に空間解像度が保持されます。
空間的プーリングは 5 つの最大プーリング層によって行われ、最大プーリングは 2×2 ピクセルのウィンドウで行われ、ストライドは 2 です。
畳み込み層の後には 3 つの全結合層があります:最初の 2 つは 4096 チャンネル、最後の層は 1000 チャンネルの softmax 層です。
すべての隠れ層には ReLU が装備されていますが、1 つのネットワークを除いて、その他のネットワークには局所応答正規化(LRN)は含まれていません。
上表では、5 つの ConvNet 構成(A-E)が示されており、主に深さに違いがあります:
- ネットワークAは11の重み層(8つの畳み込み層と3つのFC層)を持っています。
- ネットワークEは19の重み層(16の畳み込み層と3つのFC層)を持っています。
- 変換層の幅は64から始まり、最大プーリング層後に2倍ずつ増加し、最終的には512になります。
- 深さが大きいネットワークの重み数は、より大きな変換層幅と受容野を持つ浅いネットワークと比べて多くはありません。
この畳み込みネットワークでは、著者は VGG の重要な特徴として 3×3 の畳み込みカーネルを使用し、より大きな受容野を持つカーネルは使用しません。
訓練の詳細
著者は訓練中、Krizhevsky らの方法(2012)を主に参考にしました:
-
訓練方法:
- モメンタム付き小規模
バッチ勾配降下法(SGD)を使用して訓練し、バッチサイズは 256、モメンタムは 0.9 に設定しました。
- L2 正則化(重み減衰係数は)を使用しました。
- Dropout 正則化(比率は 0.5)を使用しました。
-
学習率:
- 初期学習率はに設定し、検証セットの精度が向上しなくなると、学習率は段階的に減少しました。
- 最終的に 370K イテレーション(74 エポック)の後、学習は停止しました。
-
重みの初期化:
深層ネットワークにおける初期化は非常に重要です。著者は構成 A の層を使用し、深いアーキテクチャの最初の 4 つの畳み込み層と最後の 3 つの全結合層を初期化し、中間層はランダムに初期化しました。この方法により、深層ネットワークにおける勾配の不安定性による学習の停滞を回避できます。
-
訓練画像のクロッピングとデータ拡張:
固定サイズの 224×224 ConvNet 入力画像を得るため、著者はリサイズされた訓練画像からランダムにクロッピングを行いました。また、ランダムな水平方向の反転や RGB カラーのオフセットも行い、訓練セットを強化しました。
訓練画像のサイズに関して、著者は次の 2 つの方法で訓練スケールを設定しました:
- 固定 S:S = 256 および S = 384 の 2 つの固定スケールで訓練しました。最初に S = 256 で訓練し、その後、これらの事前訓練された重みで S = 384 のネットワークを初期化しました。
- 多スケール訓練:範囲[Smin, Smax]から S をランダムにサンプリングし、その範囲は Smin = 256、Smax = 512 に設定しました。この方法は、画像中の異なるサイズの物体にうまく対応できます。
この論文の実装は C++の Caffe ツールボックスに基づいており、多くの重要な変更を加えて多 GPU 訓練と評価をサポートしています。
4 つの NVIDIA Titan Black GPU を搭載したシステムで、単一のネットワークの訓練には約 2 ~ 3 週間かかります。
討論
LRN は貢献しなかった
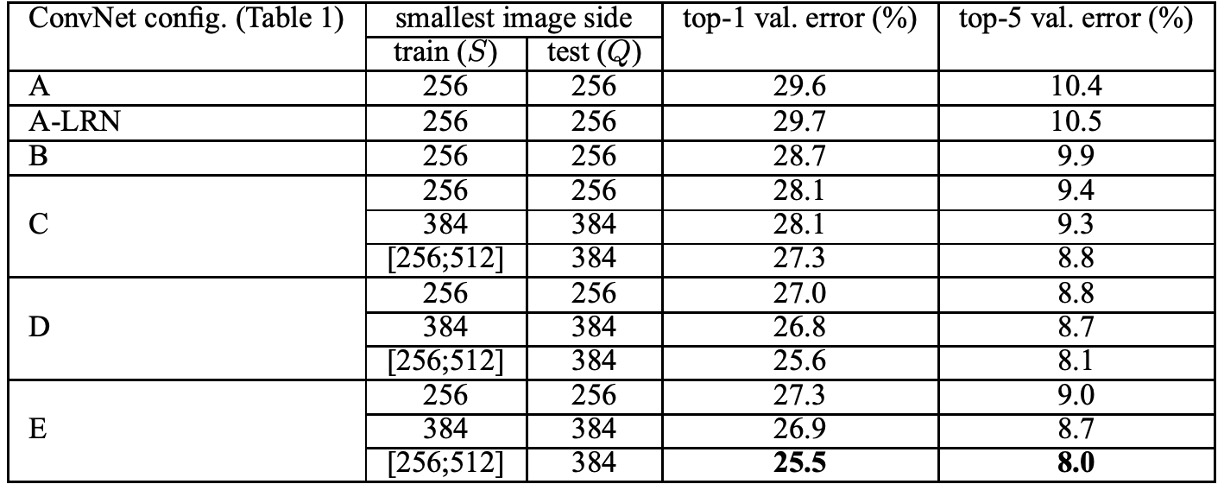
実験の結果、著者は AlexNet で提案された LRN 層がモデルにほとんど影響を与えないことを発見し、深層アーキテクチャ(B-E)ではこの標準化設計を使用しませんでした。
ネットワークの深さに関して、著者は ConvNet の深さが増すと分類誤差が減少することを発見しました。例えば、ネットワーク E の深さは 19 層に達し、ネットワーク A の 11 層と比較して分類誤差は顕著に改善されました。しかし、深さが一定のレベルに達すると分類誤差は飽和し、より深いモデルはより大規模なデータセットに有益であることが示唆されました。
ImageNet でのパフォーマンス
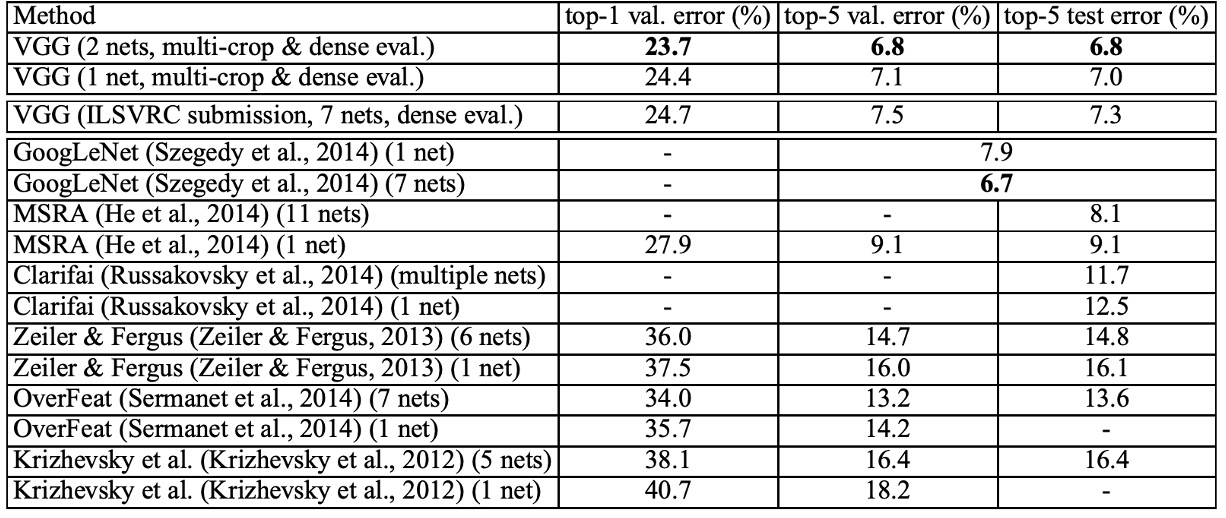
上表によると、深層畳み込みニューラルネットワーク(ConvNets)は、ILSVRC-2012 および ILSVRC-2013 の競技で最良の結果を出した前世代のモデルに比べて顕著に優れています。
VGG の結果は分類タスクにおいて GoogLeNet(誤差率 6.7%)の競争相手と同等であり、ILSVRC-2013 の最優秀提出 Clarifai(外部訓練データを使用した誤差率 11.2%、使用しない場合 11.7%)を大きく上回っています。VGG の最良の結果は、2 つのモデルを組み合わせて得られたものであり、これにより大多数の ILSVRC 提出より少ないモデル数で達成されました。単一ネットワーク性能において、VGG アーキテクチャは最良の結果を達成しました(テスト誤差率 7.0%)、単一の GoogLeNet より 0.9%優れています。
結論
VGG は深層畳み込みニューラルネットワークの分野に革命的な進展をもたらしました。その主な貢献は、ネットワークの深さが大規模画像認識精度に与える影響を探ることです。深さを段階的に増加させ、非常に小さな 3×3 の畳み込みフィルターを使用することで、VGG ネットワークは 16 ~ 19 層の重み層で精度を大幅に向上させました。
さらに、VGG ネットワークは ImageNet で優れた成績を収めただけでなく、その表現能力は他のデータセットにもよく一般化し、最先端の結果を達成しました。これは、VGG ネットワークの深層表現が異なるタスクやデータセットで非常に強い適応性と優位性を持っていることを意味します。
このアーキテクチャはシンプルで効果的であり、後続の深層学習研究に貴重な参考を提供しました。