[21.04] RoFormer
RoFormer: Enhanced Transformer with Rotary Position Embedding
RoFormer という名前よりも、実際には RoPE の方がよく知られているかもしれません。
RoPE は RoFormer のコア概念であり、正式名称は「Rotary Position Embedding」で、新しいタイプの位置エンコーディング方法です。
RNN や CNN とは異なり、Transformer は位置に対する帰納的バイアスを持っていません。
そのため、モデルがシーケンス内の順序を理解できるように、追加で位置情報を提供する必要があります。
一般的には、位置エンコーディングは位置情報をベクトル形式に変換し、それを入力のトークン埋め込みに「加える」ことによって行われます。
最初の Transformer 論文では、三角関数を用いた位置エンコーディングが採用されました。
PE(pos,k)={sin(pos/100002i/dmodel)cos(pos/100002i/dmodel)if k=2iif k=2i+1
この関数は、シーケンスの長さと特徴の次元を同時に考慮し、各位置に固定の位置エンコーディングを割り当てます。
三角関数は生成規則が固定されているため、外挿能力を持っています。
数式中の 10000 は何ですか?
この 10000 の物理的な意味は、位置エンコーディングのスケールとして解釈できます。位置エンコーディングのスケールを適切な範囲に制限することで、異なる位置間の関係を効果的に捉えつつ、あまり高すぎるまたは低すぎる周波数が及ぼす悪影響を避けることができます。
もし位置エンコーディングの 10000 を 100 に変更すると、正弦関数と余弦関数の周波数が増加し、各位置の位置エンコーディングはより短い距離で周期的に繰り返されることになります。これにより、モデルは遠くの位置間の関係を捉える能力が低下する可能性があります。なぜなら、それらの位置エンコーディングがより似ているものとして表示されるからです。
BERT や GPT などのモデルでは、位置エンコーディングは訓練を通じて得られます。
最大シーケンス長をNとした場合、位置エンコーディングの次元はdmodelであり、位置エンコーディングの行列はN×dmodelとなります。
この設計の利点は非常にシンプルであり、特に深く考えることなく使用できることですが、欠点としては、シーケンス長が変更されると再訓練が必要であり、長いシーケンスへの汎化が難しいことです。
実際、外挿性が絶対位置エンコーディングの明らかな欠点ではないこともあります。興味のある読者は、蘇劍林のこの記事を参照できます:
この論文では、自己注意機構におけるQKTの展開を行っています:
- Qi=(xi+posi)WQ
- Kj=(xj+posj)WK
- QiKjT=(xi+posi)WQWKT(xj+posj)T
最終的に、次の式が得られます:
- QiKjT=xiWQWKTxjT+xiWQWKTposjT+posiWQWKTxjT+posiWQWKTposjT
次に、posjを相対位置ベクトルRi−jに置き換え、posiを学習可能なベクトルu, vに置き換えた結果、次のようになります:
- QiKjT=xiWQWKTxjT+xiWQWKTRi−jT+uWQWKTxjT+vWQWKTRi−jT
その後、uWQとvWQは学習可能なパラメータであり、それらを一つにまとめることができます。これにより、次の式が得られます:
- QiKjT=xiWQWKTxjT+xiWQWKTRi−jT+uWKTxjT+vWKTRi−jT
Ri−jTのエンコーディング空間と元々のposjのエンコーディング空間が異なるため、WKTをWK,RTに置き換えて次の式が得られます:
- QiKjT=xiWQWKTxjT+xiWQWK,RTRi−jT+uWKTxjT+vWK,RTRi−jT
最後に、この論文では QKV の V 行列には位置エンコーディングが追加されていません。その後の研究でも、QK 行列(すなわち注意行列)にのみ位置エンコーディングが追加されています。
T5 では、著者はコンテンツ情報と位置情報を解耦し、位置に関連する情報をすべてβi,jに格納しました。これにより、次の式が得られます:
- QiKjT=xiWQWKTxjT+βi,j
ここではすべての位置エンコーディング方法を振り返るつもりはありません。さらに詳細な内容については、蘇劍林のウェブサイトの記事を参照してください:
過去の研究を振り返ると、絶対位置エンコーディングと相対位置エンコーディングはそれぞれに利点と欠点があります。
本研究では、絶対位置エンコーディングと相対位置エンコーディングを融合する方法を提案することを目指しています。
Transformer ベースの言語モデリングでは、通常、自己注意機構を通じて各トークンの位置情報を活用します。著者は、内積が相対的な形でのみ位置情報をエンコードすることを希望しました:
⟨fq(xm,m),fk(xn,n)⟩=g(xm,xn,m−n)
最終的な目標は、関数 fq(xm,m) と fk(xn,n) が上記の関係式を満たすような等価なエンコーディング機構を見つけることです。
一連の導出の結果(詳細は論文をご参照ください)、著者が提案する解は次の通りです:
- fq(xm,m)=(Wqxm)eimθ
- fk(xn,n)=(Wkxn)einθ
- g(xm,xn,m−n)=ℜ[(Wqxm)(Wkxn)∗ei(m−n)θ]
ここで、ℜ は実部を取る演算子、∗ は共役複素数、θ はゼロでない定数です。
オイラーの公式と回転
オイラーの公式の中心的な概念は回転です。複素数 z=x+iy に対して、これを平面上の点 (x,y) と見なすことも、ベクトル (x,y) と見なすこともできます。複素数 z に eiθ を掛けることは、ベクトル (x,y) を原点を中心に逆時計回りに θ 度回転させることと等価です。
一例として、マークダウンでざっくりした図を描いてみましょう:
これは、eiθ がオイラーの公式を使って次のように展開できるからです:
- eiθ=cos(θ)+isin(θ)
この公式は、複平面上の単位ベクトルが原点を中心に θ 度逆時計回りに回転することを示しています。
-
特殊なケース
θ=π の場合、次のようになります:
- eiπ=−1
これは、複素数 z を eiπ で掛けることが、ベクトルを 180 度回転させて反対方向のベクトルを得ることを意味します。したがって、次の有名な恒等式が得られます:
- eiπ+1=0
この公式はオイラーの恒等式として知られ、数学の中で最も美しい公式の一つであり、自然対数の底 e、虚数単位 i、円周率 π、1、0 を巧妙に結びつけています。
論文中で、inθ という形式が登場しますが、ここでの nθ は回転角度の倍率を表しています。
fq(xm,m) と fk(xn,n) の形式は、複平面上でそれぞれのベクトルが mθ と nθ の角度で回転していることを示しています。
ここでの m と n はパラメータで、異なる周波数成分や空間的位置を表しています。この形式は、異なる回転角度における 2 つのベクトルの挙動を捉えることができます。
g(xm,xn,m−n)=ℜ[(Wqxm)(Wkxn)∗ei(m−n)θ]ここで、i(m−n)θ は 2 つの回転角度の差を示しています。
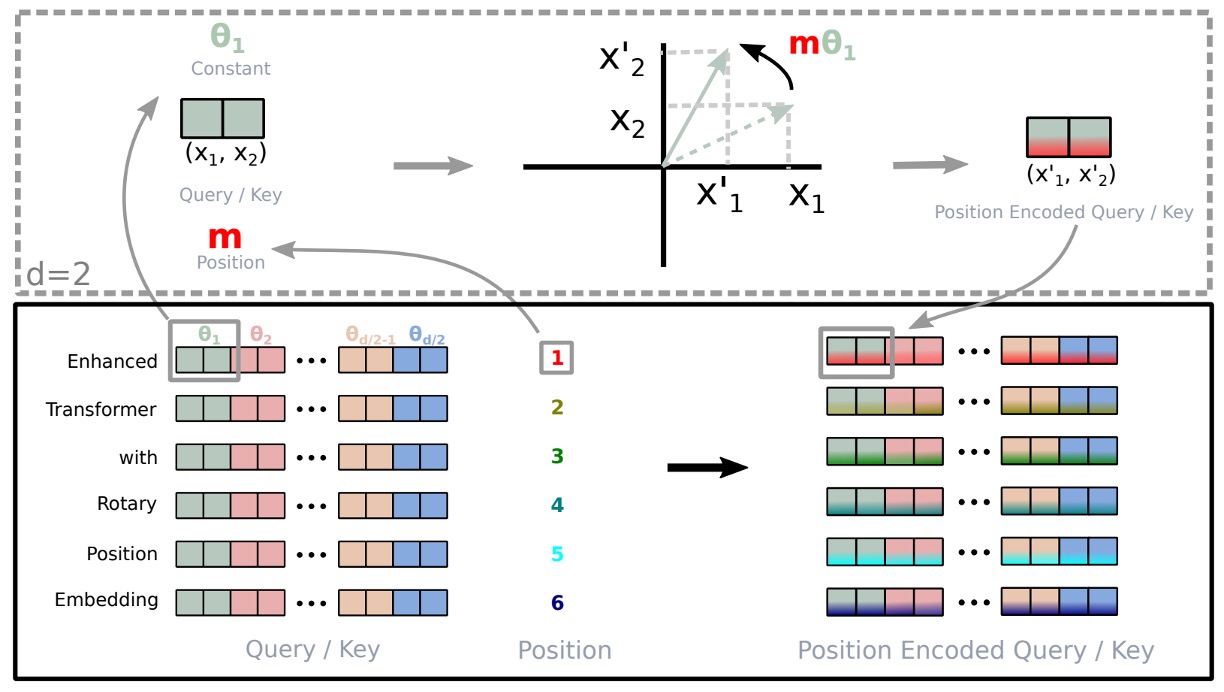
RoPE の図による説明は上の通りです。
2 次元空間での結果を任意の xi∈Rd (dが偶数の場合)に拡張するために、著者は d 次元空間を d/2 のサブ空間に分割し、内積の線形特性を利用して f{q,k} を次のように変換しました:
f{q,k}(xm,m)=RΘ,mdW{q,k}xm
ここで、
RΘd,m=cosmθ1sinmθ100⋮00−sinmθ1cosmθ100⋮0000cosmθ2sinmθ2⋮0000−sinmθ2cosmθ2⋮00⋯⋯⋯⋯⋱⋯⋯0000⋮cosmθd/2sinmθd/20000⋮−sinmθd/2cosmθd/2
は、予め設定されたパラメータ Θ={θi=10000−2(i−1)/d,i∈[1,2,...,d/2]} を持つ回転行列です。
RoPE を自己注意機構に適用した場合、次の式が得られます:
qm⊤kn=(RΘ,mdWqxm)⊤(RΘ,ndWkxn)=x⊤WqRΘ,n−mdWkxn
ここで、RΘ,n−md=(RΘ,md)⊤RΘ,nd です。注意すべき点は、RΘd が直交行列であるため、位置情報をエンコードする過程での安定性が保証されることです。
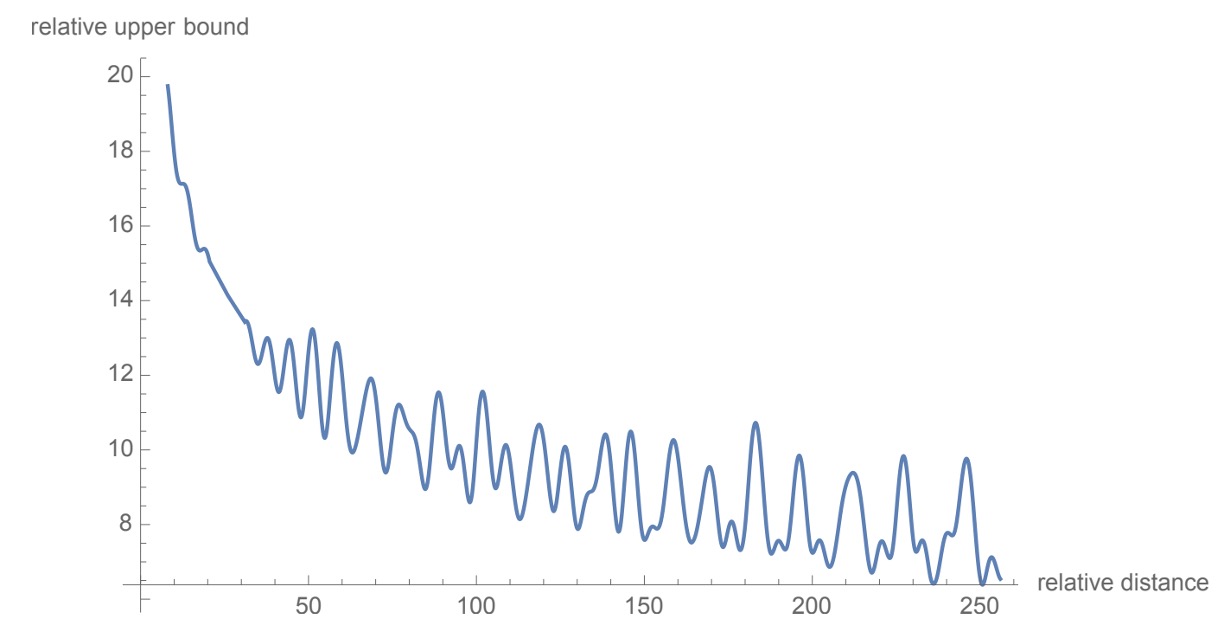
著者は元々の Transformer の設計思想を引き継ぎ、θi=10000−2i/d を設定して、位置エンコーディングの長距離減衰特性を提供しています。上の図に示されたように、2 つの位置間の距離が増加するにつれて、位置エンコーディング間の内積が減少します。これは、テキスト内のより遠くの位置間の関係が弱くなると予想されるためです。
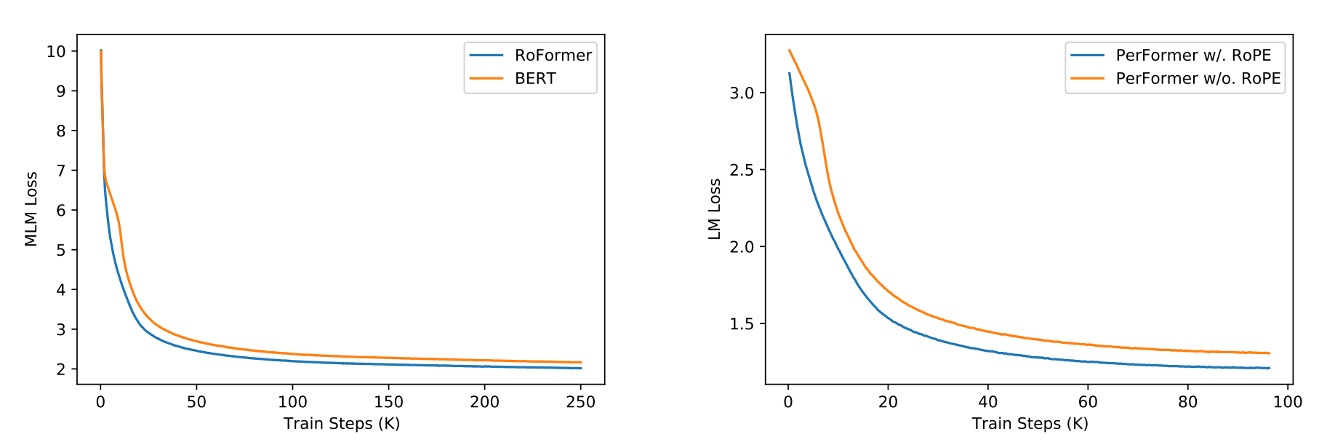
上の図は、RoPE と他の位置エンコーディング方法の比較を示しています。
左側は BERT との比較です。RoPE を使用したモデルが訓練過程でより良い性能を示し、MLM Loss が速く減少していることがわかります。右側は RoPE を PerFormer に追加した場合で、訓練過程での収束速度が速く、訓練終了時により良い性能を達成しています。

著者は Hugging Face の Transformers ライブラリを使用して微調整し、GLUE データセットで実験を行いました。
実験結果から、RoFormer は GLUE データセットで BERT を上回る性能を示し、RoPE が自然言語処理タスクで有効であることを示しています。
この研究は強力な理論的サポートと励みになる実験結果を提供していますが、著者は以下の制限が存在すると考えています:
- 数学的には相対位置関係を 2D サブ空間内で回転として表現しましたが、この方法がなぜ他の位置エンコーディング戦略を使用したベースラインモデルよりも速く収束するのかについては、まだ深い説明が不足しています。
- モデルが長距離減衰という有利な特性を持っていることは証明されていますが、これは既存の位置エンコーディング機構に似ており、長いテキストの処理において他のモデルよりも優れた性能を発揮しますが、まだ納得のいく説明が見つかっていません。
この論文は少し難解かもしれませんが、RoPE の概念は非常に興味深く、原著を読むことを強くお勧めします。
現在、すでに多くの研究(例えば LLaMA や Mamba)が RoPE を使用しており、RoPE が自然言語処理の分野で非常に広い適用範囲を持っていることを示しています。
今後、RoPE に関する多くの研究が進められ、改良が加えられることでしょう。再びこのテーマについて話すことを楽しみにしています。
