[20.02] ABCNet

ベジエ曲線の挨拶
ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network
OCR はすでに数年の歴史がありますが、テキスト検出と認識のタスクは依然として挑戦的な問題です。
問題の定義
テキスト検出と認識は OCR の二大タスクです。
テキスト検出は、画像内でテキストの位置を見つけるタスクで、これは多くの方法が「物体検出」や「物体セグメンテーション」の手法から派生しています。しかし、テキストはしばしば斜め、歪んだ、または曲線的に配置されていることが多く、これらの特性によりテキスト検出はさらに困難になります。
テキスト認識は、テキストの位置が特定された後、テキストを認識可能な文字に変換するタスクです。しかし、テキスト検出の誤差に制約され、テキスト認識の精度にも影響を与えます。そこで、テキストが不規則であることを前提に、入力テキストを不規則な形状と仮定して、直接不規則なテキストを認識する方法がいくつか提案されています。その中には、STN(空間変換ネットワーク)や二次元注意メカニズムを基にした方法もあります。
過去の手法を振り返ると、以下のようになります:
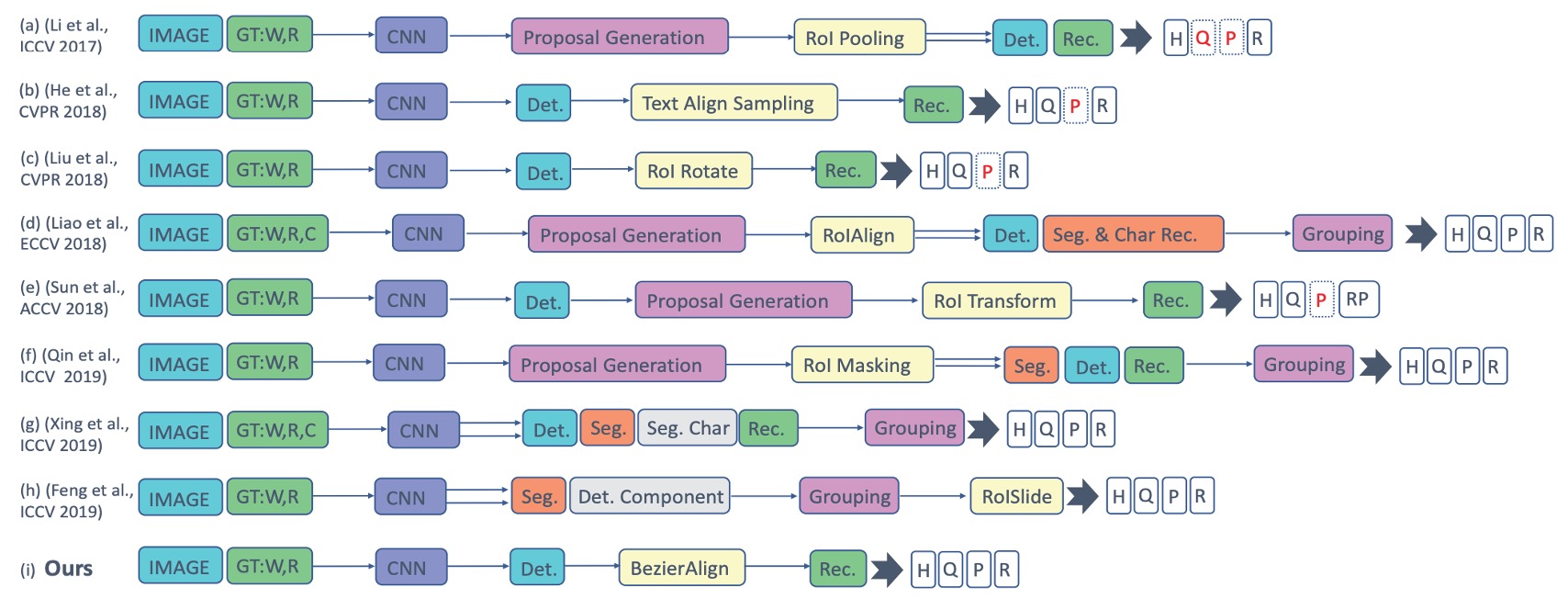
著者は、これらの複数段階の複雑な設計がシステムを複雑で遅くし、実際のアプリケーションではメンテナンスが難しく、実用的でないと考えています。そこで、テキストの変形問題を解決するために、著者は「ベジエ曲線」を導入し、テキストの形状をフィッティングすることで、テキスト検出と認識の両方を解決する「ベジエ補正ネットワーク」を提案しています。
え、ベジエ曲線?それは何ですか?
ベジエ曲線
ベジエ曲線は、滑らかな曲線の形状を記述するための数学的曲線です。これはコンピュータグラフィックス、フォント制作、アニメーション、UI デザインなどの分野で非常に一般的に使用され、さまざまな曲線効果を作成するのに役立ちます。曲線は一組の制御点によって生成されます。曲線の始点と終点は制御点の端点であり、中間の制御点が曲線の曲がり方を決定します。これらの制御点は必ずしも曲線上に存在するわけではなく、曲線の形状に影響を与えます。
ベジエ曲線は、異なるサイズでスケーリングしても滑らかさを維持するため、さまざまな形状(直線から曲線、さらには複雑な幾何学的形状)を表現するのに使用できます。
最後に、さまざまな階数のベジエ曲線とその形状を見てみましょう:
-
一次(線形)ベジエ曲線:2 つの制御点の間の直線。
-
-
二次(放物線)ベジエ曲線:3 つの制御点。
-
-
三次ベジエ曲線(最も一般的):4 つの制御点、フォント、アニメーション、UI デザインなどで使用されます。
-
-
四次ベジエ曲線:5 つの制御点。
-
-
五次ベジエ曲線:6 つの制御点。
-
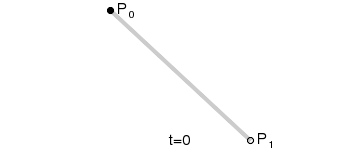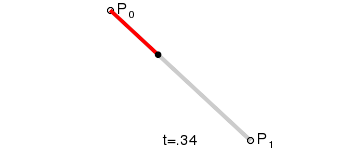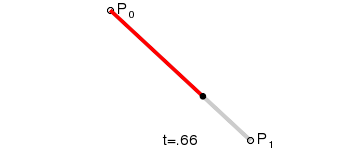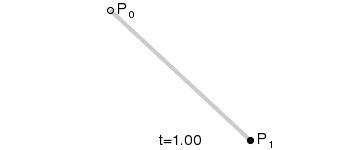
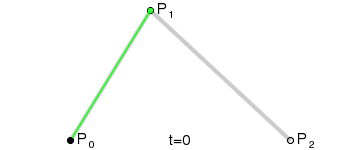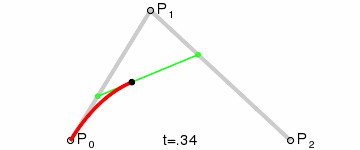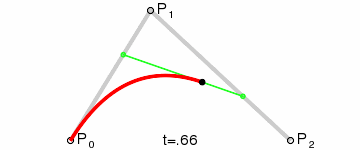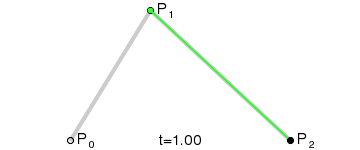
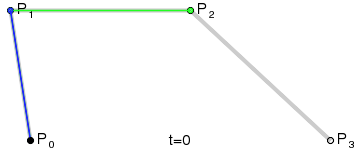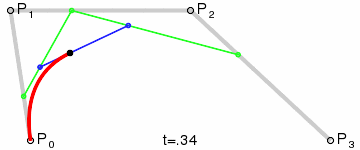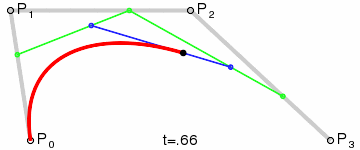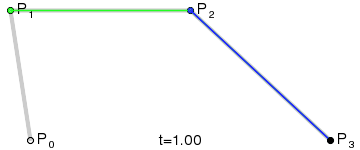
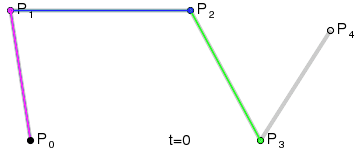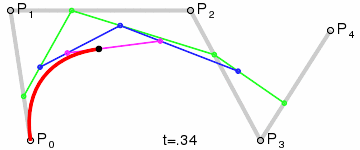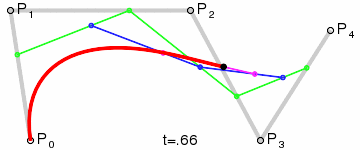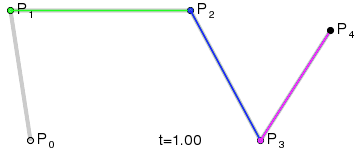
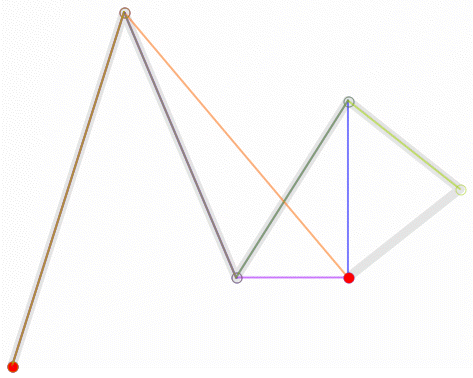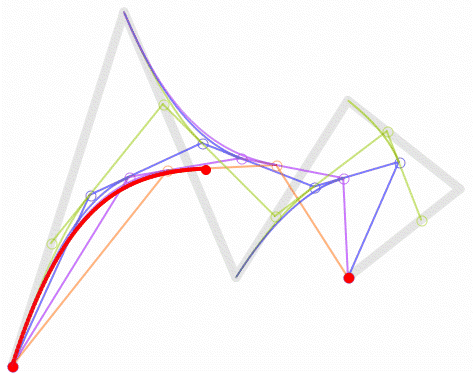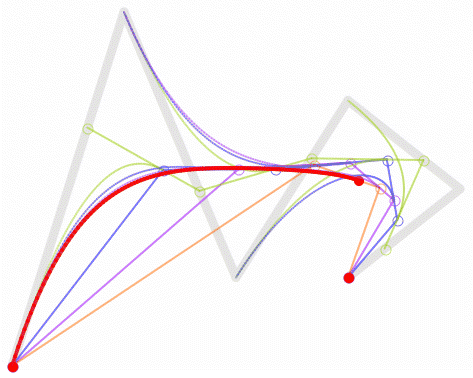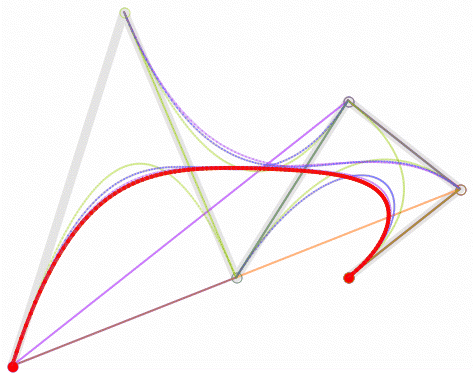
上記の GIF 画像はすべて、Wikipedia のベジエ曲線紹介ページからのものです。
問題の解決
ベジエ曲線を見た後、まるでこの論文を読み終わったかのように感じます。(実際はそうではありませんが)
モデルアーキテクチャ
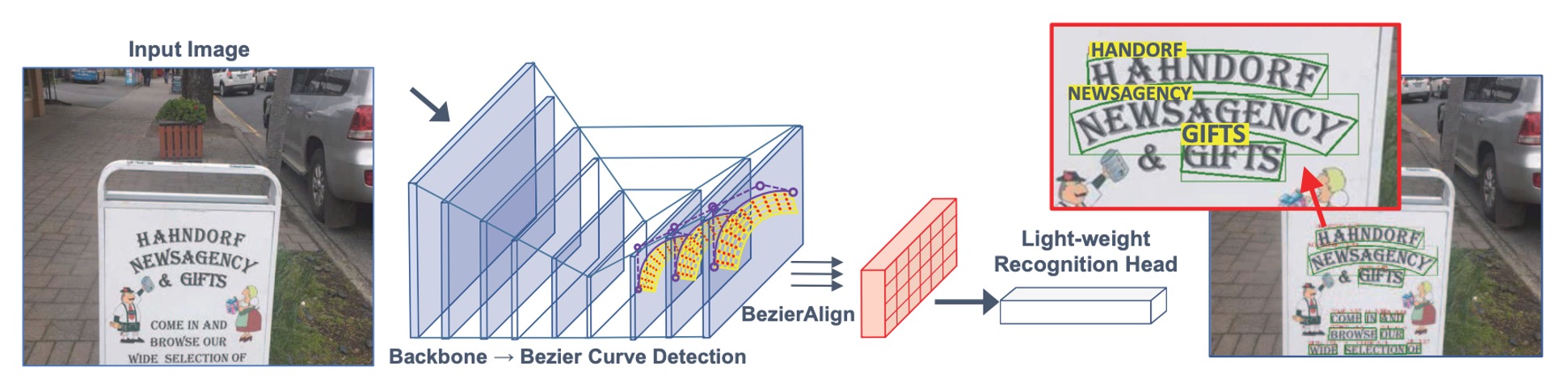
著者は過去の「アンカーボックス」や「多段階」の設計を排除し、ベジエ曲線を使ってテキストの形状を記述し、任意の形状のテキストを検出するためのエンドツーエンドの訓練フレームワークを提案しています。
ベジエ曲線については上記で説明しましたが、著者の分析により、三次ベジエ曲線がほとんどの曲がったテキスト形状を効果的に表現できると考えています。したがって、8 つの制御点を使って、境界ボックス内のテキスト形状を記述しています。
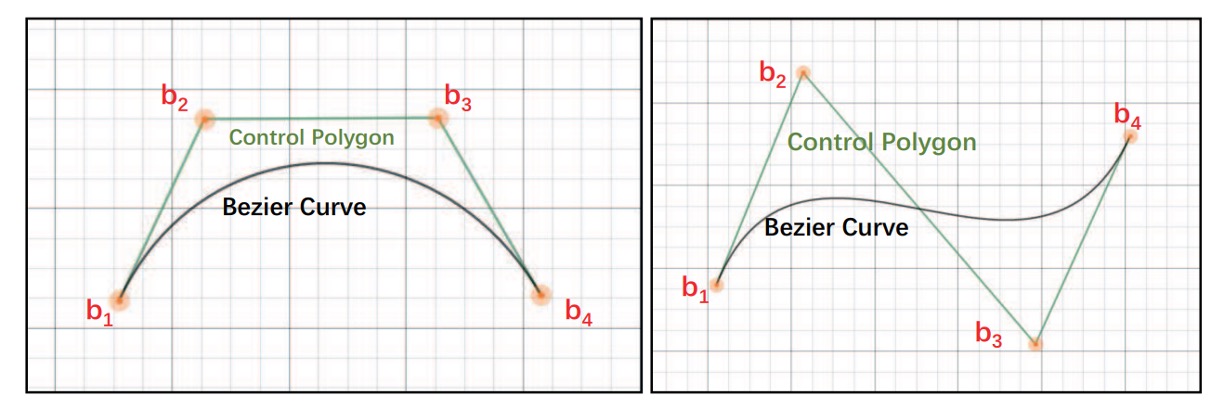
制御点の回帰学習は相対距離によって行われ、これによりモデル設計が簡素化され、精度も向上します。数学的には次のように表されます:
ここで、 と は四つの頂点の最小の と 値です。
予測ヘッドは 1 層の畳み込み層のみで、出力は 16 チャンネルで と を学習します。これにより計算コストが非常に低く、結果は正確です。
テキスト領域は上層曲線と下層曲線に分けて、テキスト領域を囲むため、1 つの三次ベジエ曲線には 4 つの制御点が必要です。2 つの曲線で合計 8 つの制御点が必要になります。
各点の座標は であり、8 つの制御点には 16 の座標があります。
ベジエ曲線のデータ生成
現在の訓練データセットには、ベジエ曲線のアノテーションデータは存在しません。
そのため、著者は既存のアノテーションデータを基に、ベジエ曲線の Ground Truth を生成する方法を提案しました。
この方法では、Total-Text や CTW1500 といったデータセットにある多角形のアノテーション点を使い、最小二乗法を通じて、三次ベジエ曲線の最適なパラメータを求めます:
ここで、 は多角形のアノテーション点の数、 は折れ線の累積長さと周囲の比率を基に計算されます。以下の図はその一例です:

訓練データ合成
エンドツーエンドのシーンテキスト検出モデルを訓練するためには、大量の合成された無料データが必要です。しかし、現在のSynTextデータセット(80 万枚の画像)は、主に直線的なテキストに四角形の境界ボックスが提供されているだけで、任意の形状のシーンテキストのニーズには対応していません。そこで、著者はデータセットを拡張し、15 万枚の多様な画像を合成して、モデルの曲線テキスト検出能力を向上させました。
新しいデータセットは次のように構成されています:
- 94,723 枚の画像:主に直線的なテキストを含む。
- 54,327 枚の画像:主に曲線的なテキストを含む。
データの出所は以下の通りです:
- VGG 合成法を用いてこれらの合成画像を生成。
- COCO-Textデータセットから4 万枚の無文字背景画像を選択。
COCO-Text から取得した背景画像には、各背景に対するセグメンテーションマスクを準備し、各背景のシーン深度情報も用意して、テキストと背景の融合効果を高めています。さらに、文字形状の多様性を増やすために、VGG 合成法を改良し、異なるスタイルのアートフォントと豊富な文字データを追加し、生成した文字には曲線変形や多様な配置を施して、さまざまなシーンにおけるテキストスタイルをシミュレートしました。各文字インスタンスには、自動的に多角形のアノテーションが生成され、外形が記述されています。
さらに、著者は多角形アノテーションを三次ベジエ曲線の Ground Truth に変換し、モデルがさまざまな曲線的なテキストの形状を正確にフィットできるようにし、検出性能を向上させました。これにより、データ生成プロセスが簡素化され、モデルが任意の形状のシーンテキストを検出できる能力が強化され、実際のシーンアプリケーションのニーズに対応しています。
合成データの結果は以下の通りです:

ベジエ補正法
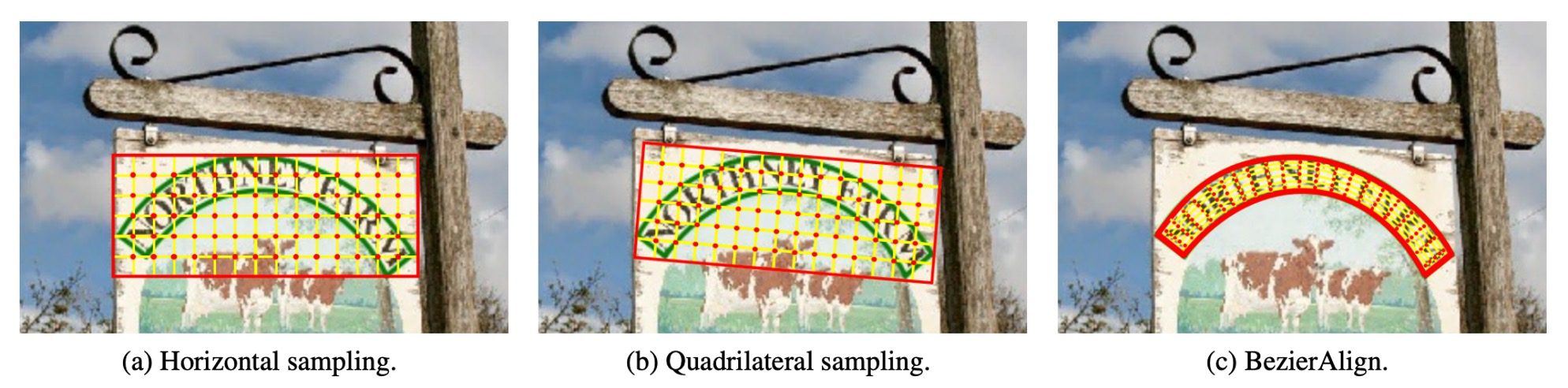
従来のサンプリング方法は以下の通りです:
BezierAlign は RoIAlign を基にした拡張ですが、RoIAlign とは異なり、非矩形のサンプリンググリッドを使用して特徴を整列させます。特徴整列グリッドの各列は、ベジエ曲線の境界と垂直に一致するため、整列精度が保証されます。サンプリングポイントは幅と高さで均等に分布し、バイリニア補間を使用してサンプリング結果を計算します。
特徴マップとベジエ曲線の制御点が与えられた場合、矩形出力特徴マップの各ピクセル位置を計算できます。
出力特徴マップのサイズを とした場合、計算プロセスは以下の通りです:
-
第 番目のピクセル の水平位置を として記録します。
-
次の式を使用してパラメータ を計算します:
-
とベジエ曲線方程式を使用して、上辺の点 と下辺の点 を計算します。
-
と を基に、次の式でサンプリング点 の位置を計算します:
-
の位置が得られたら、バイリニア補間を用いて最終結果を計算します。
BezierAlign は任意の形状のテキスト領域を処理でき、矩形グリッドの制約を受けません。特に曲線的なテキストの検出と認識に適しており、高効率でセグメンテーション処理を必要とせず、計算過程が簡素化されます。従来の方法と比較して、BezierAlign は特徴整列の精度と効率において顕著な改善を見せます。詳細な比較は以下の通りです:
テキスト予測ヘッド
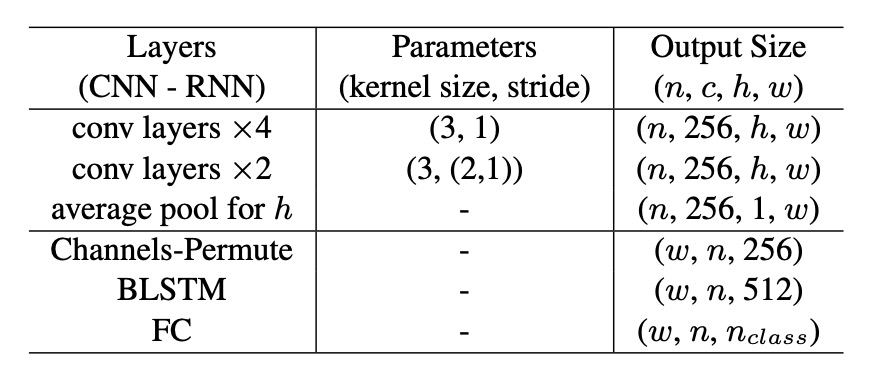
検出分岐と共有するバックボーンネットワークの特徴および BezierAlign に基づいて、著者は軽量なテキスト認識分岐を設計しました。構成は以下の通りです:
- 畳み込み層:6 層、最初の 4 層のストライドは 1、残りの 2 層は垂直ストライドが 2、水平ストライドが 1。
- 平均プーリング:高さ方向に平均プーリングを行い、出力サイズを に圧縮。
- チャンネル並べ替え:テンソルの形状を調整し、BLSTMに入力。
- BLSTM:出力サイズは で、文字の双方向シーケンス情報をキャプチャ。
- 全結合層:最終出力は で、(大文字、小文字、数字、記号、その他の特殊文字および終了符号 EOF をカバー)。
訓練段階では、認識分岐がベジエ曲線の GT から RoI 特徴を直接抽出し、検出分岐と認識分岐は相互に影響しません。テキストの整列には「CTC Loss」を使用して、出力分類結果とテキストを整列させ、モデルの訓練安定性を確保します。
推論段階では、RoI 領域は検出分岐から得られたベジエ曲線の結果で置き換えられ、テキストが曲線領域に正確に整列することを保証します。
訓練設定
- ResNet-50 と特徴金字塔ネットワーク(FPN)を使用。
- 5 つの異なる解像度の特徴マップで RoIAlign を使用:
- 特徴マップ解像度は入力画像の 。
- 3 つの異なるサイズの特徴マップで BezierAlign を適用:
- 特徴マップサイズは入力画像の 。
- 公開されている英単語レベルのデータセットを使用して事前訓練:
- 15 万枚の合成データ。
- COCO-Text データセットから選ばれた 1.5 万枚の画像。
- ICDAR-MLT データセットから 7,000 枚の画像。
- 事前訓練後、ターゲットデータセットの訓練セットでファインチューニングを行う。
データ拡張戦略は次の通りです:
- ランダムスケーリング訓練:
- 短辺のサイズは 560〜800 の範囲でランダムに選択。
- 長辺のサイズは最大 1333 に制限。
- ランダムクロップ:
- クロップ後の領域は元画像の半分以上で、文字が切れないようにする。
- 特殊な状況ではクロップを行わない。
ハードウェア環境は以下の通りです:
- 4 枚の Tesla V100 GPU を使用して訓練。
- バッチサイズは 32。
訓練パラメータは以下の通りです:
- 最大イテレーション数:150,000 回。
- 初期学習率:0.01。
- 学習率調整:
- 70,000 回目のイテレーションで 0.001 に減少。
- 120,000 回目のイテレーションで 0.0001 に再度減少。
訓練は約 3 日で完了しました。
討論
著者はTotal-Text データセットを用いて比較実験とアブレーション実験を行い、その結果は以下の通りです:
BezierAlign 効能分析
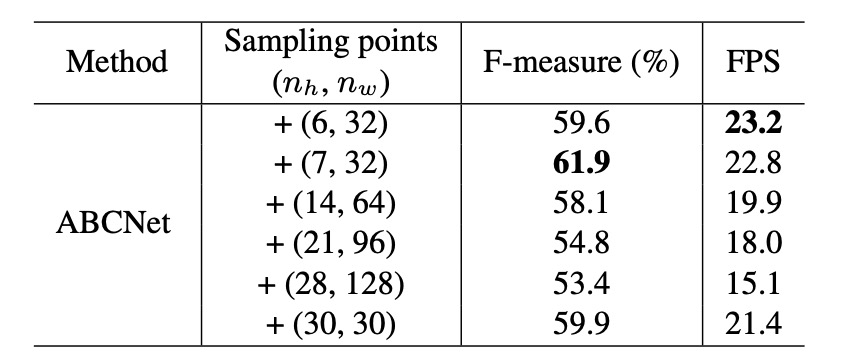
BezierAlign の効果を検証するために、著者は Total-Text でアブレーション実験を実施し、サンプリングポイント数が結果に与える影響を調査しました。実験結果は以下の通りです:
サンプリングポイント数が (7, 32) の場合、F-measure と FPS(1 秒あたりのフレーム数)のバランスが最適であることが確認され、著者はこの設定を後続の実験で使用しました。また、BezierAlign と従来のサンプリング方法を比較した結果(以下の表)、BezierAlign はエンドツーエンドの検出精度を大幅に向上させることが示されました:

ベジエ曲線効能分析

分析結果は上記の通りで、ベジエ曲線による検出は標準的な境界ボックス検出と比較して、追加の計算コストを導入していないことが確認されました。
Total-Text での実験結果
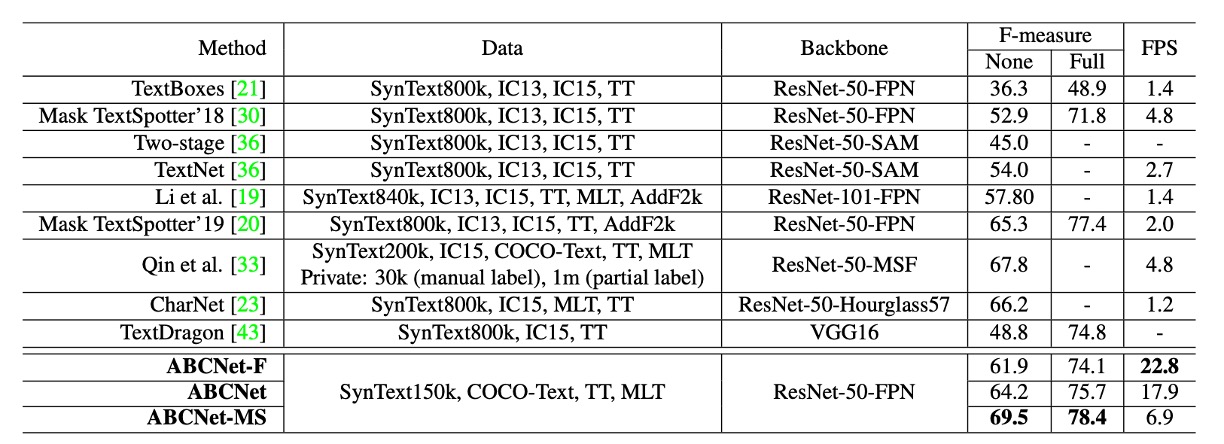
著者は ABCNet と他の方法を比較しました。その結果は以下の通りです:
- 単一スケール推論:ABCNet は高いパフォーマンスを維持しながら、ほぼリアルタイムの推論速度を実現し、速度と精度の最適なバランスを達成しました。
- 複数スケール推論:精度がさらに向上し、ABCNet は複数スケール推論下で最新技術のパフォーマンスを達成しました。特に、実行時間において他の方法を大きく上回る結果を示しました。
- ABCNet の加速バージョンは、精度が同等であるにもかかわらず、推論速度が以前の最良方法より11 倍以上速いという結果となりました。
結論
ABCNet は過去の ROI Proposal の設計を継承し、最初にベジエ曲線を導入し、さらにBezierAlign 層を提案して、特徴マップとベジエ曲線の境界を整列させ、テキスト検出と認識の精度を向上させました。また、著者は新たなデータ合成方法を提案し、さまざまなテキスト画像を生成することで、モデルの汎化能力をさらに高めました。
本論文の設計思想は、今後のテキスト検出と認識タスクに新たな視点と発展方向を提供しており、今後の研究や探討において重要な意味を持つといえます。