[18.04] YOLOv3

多尺度検出の導入
YOLOv3: An Incremental Improvement
第三世代の YOLO は、実際には論文ではなく、著者自身が述べた通り、単なる技術報告です。
問題の定義
最近、物体検出の分野で多くの新しい研究成果が出ています。
著者はこれらの新しいアイデアを YOLO に統合し、いくつかの改善を行うべきだと考えました。
その中で、Bounding Box の予測部分は変更せず、YOLOv2 の設計をそのまま使用していますので、ここでは再度詳述しません。
解決策
著者は一連の改良を行いました。
Backbone の更新
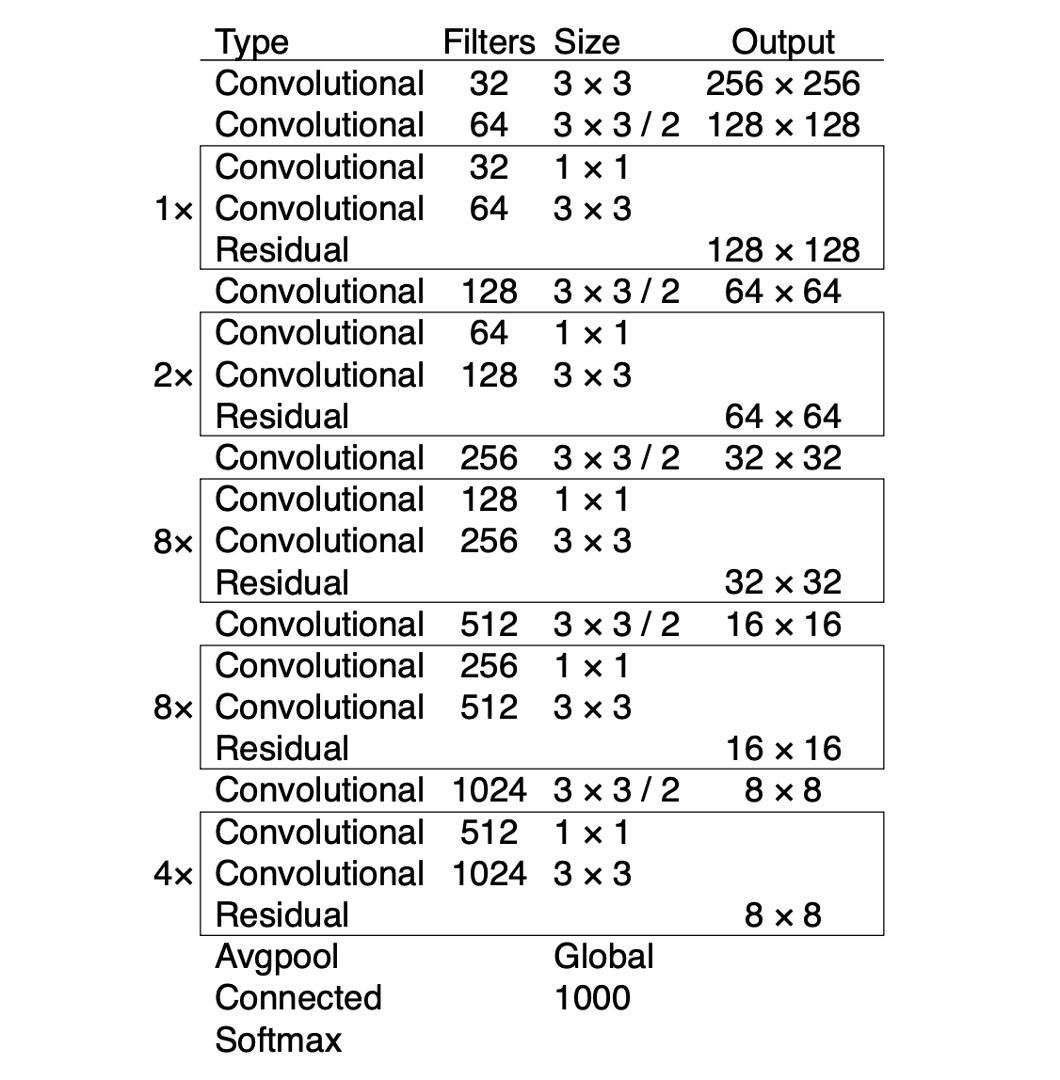
著者は Darknet-19 のネットワークアーキテクチャを Darknet-53 に変更しました。ここでも 3x3 と 1x1 の畳み込み層を連続的に使用し、いくつかの残差接続を追加しています。これはより深いネットワークで、ImageNet で訓練されました。このネットワークは 53 層の畳み込み層を持つため、著者はこれを Darknet-53 と呼んでいます。
下表は Darknet-53 の ImageNet でのパフォーマンスを示しており、top-1 精度は ResNet-101 と同等で約 77.1%ですが、推論速度は 50%向上しました。

クラス予測
ここでは softmax ではなく、ロジスティック回帰を使用して各クラスの確率を予測します。
これは、モデルがクラスに対してハードな決定を下す必要がなく、複数のクラスに対してチャンスを与えることで、未知のクラスへの拡張が容易になることを意味します。
多尺度検出
FPN や RetinaNet の概念を参考にして、著者は YOLOv3 に多尺度検出を導入しました。
アンカーポイントの部分では、引き続き K-means クラスタリングを使用して最適なアンカーを見つけますが、異なる点は、1/32、1/16、1/8 の 3 つの異なるスケールの特徴マップを使用することです。各スケールで 3 つの異なるサイズのボックスを予測するため、合計で次のような構成になります:4 つの境界ボックスオフセット、1 つの物体信頼スコア、80 個のクラス確率。
予測テンソルのサイズはです。
討論
COCO でのパフォーマンス
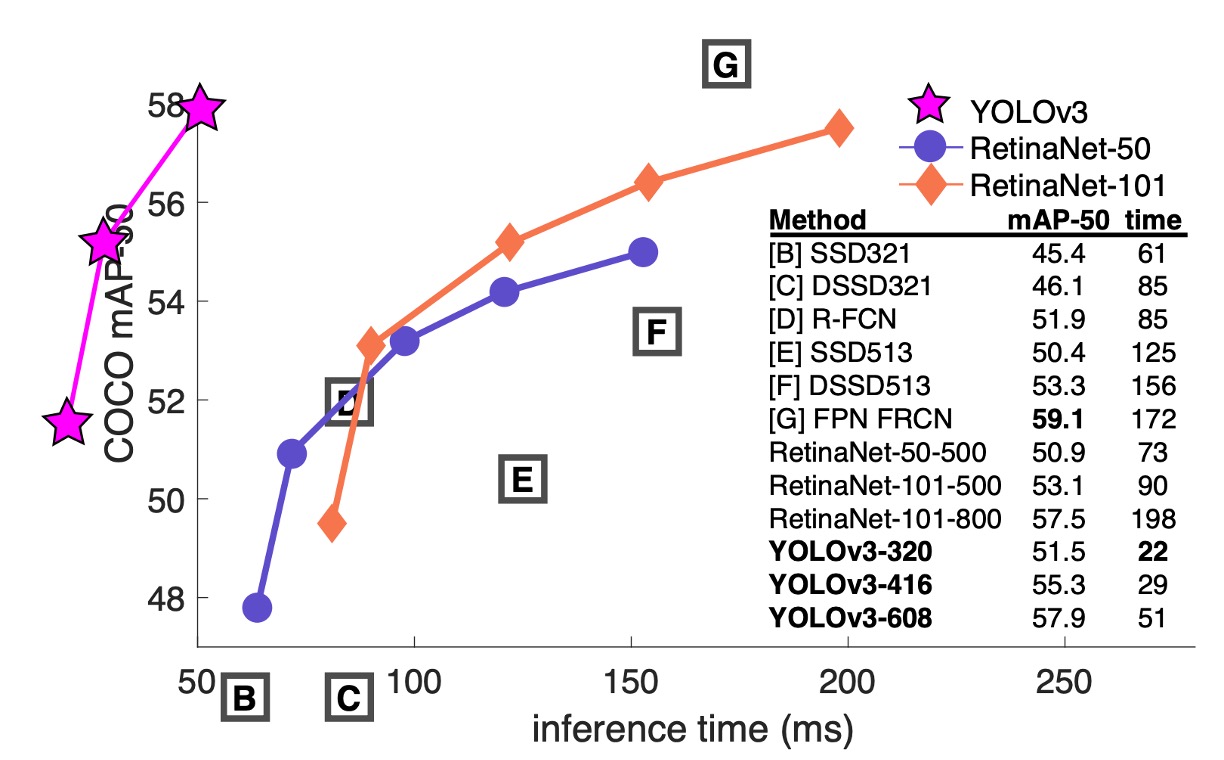
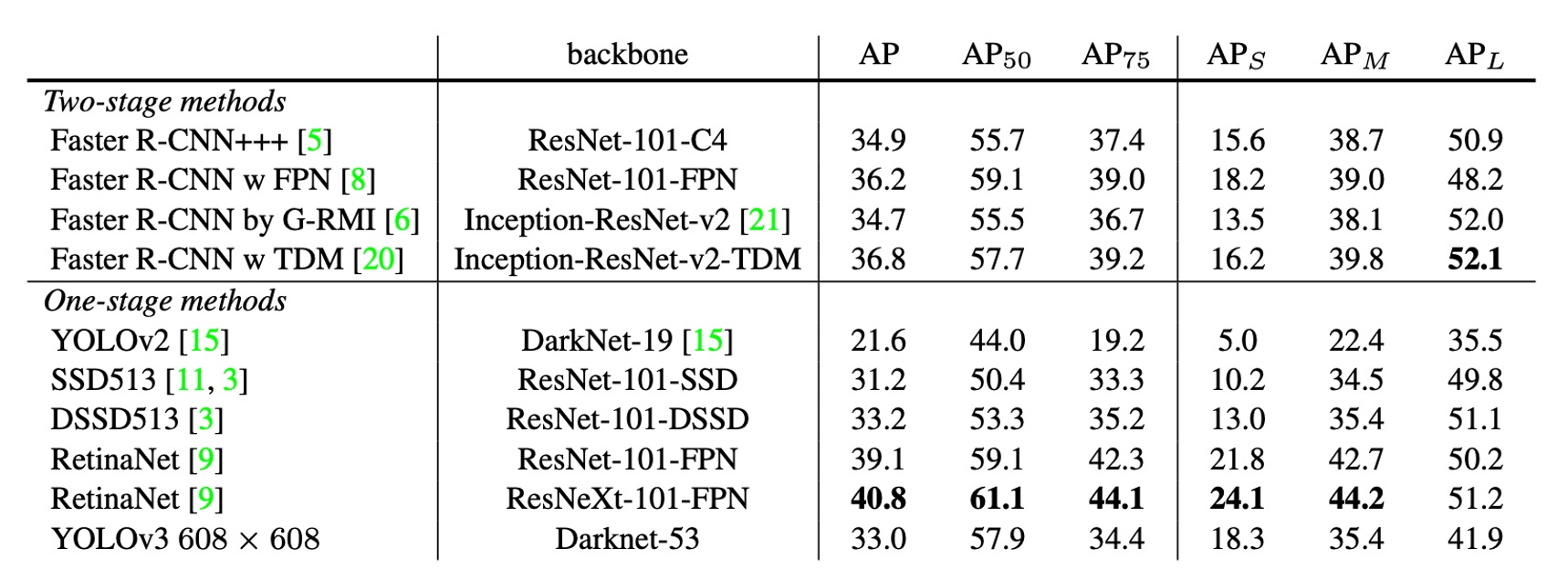
著者はまず、他のアーキテクチャモデルを再訓練するために多くの時間を費やすのを避け、RetinaNet の論文から画像と表データを「借用」し、その後 YOLOv3 の結果をその表に載せました。これにより、YOLOv3 が速度と精度の両方で優れたパフォーマンスを示していることがわかります。
上表から、YOLOv3 はで非常に優れた結果を出し、SSD アーキテクチャよりも遥かに高い精度を示しています。これは物体検出において良好なパフォーマンスを意味します。しかし、IOU の閾値が増加するにつれて、YOLOv3 のパフォーマンスは徐々に低下し、高精度な境界ボックスを生成するのが難しいことが示唆されています。
過去の YOLO アーキテクチャは小物体の検出性能が低かったですが、YOLOv3 はこれに対して改善が見られました。新しい多尺度検出により、小物体の検出において大きな向上がありましたが、中〜大規模物体の検出ではパフォーマンスが低下しました。
効果がなかった試み
著者は訓練過程でいくつかの方法を試みましたが、効果が不明であったことも述べています。
- アンカーボックス中心の x, y オフセット予測:著者は線形活性化関数を使用することを試みましたが、効果は見られませんでした。
- 線形 x, y 予測:ロジスティック関数の代わりに線形活性化関数を使用しましたが、パフォーマンスが低下しました。
- Focal Loss の使用:Focal Loss を使用してクラス不均衡の問題を解決しようとしましたが、パフォーマンスは 2%低下し、その原因は不明です。
- 二重 IOU 閾値:Faster R-CNN の手法を使用して、IOU が 0.7 より大きいものを正サンプル、0.3 未満を負サンプルとして扱い、間の部分は無視する方法を試しましたが、効果はありませんでした。
結論
過去の研究結果に基づき、人間は IOU 0.3 と 0.5 の境界ボックスを見分けるのが難しいことを考慮し、著者は、既に人間がそれらを区別するのが難しいので、モデルがこれらの検証データセットでより高いスコアを追求することには大きな意味がないと考えています。
YOLOv3 の性能は現実の多くの問題に十分に対応できると著者は見なしており、今後はモデルの安全性向上に注力し、これらの高性能なモデルが適切な場所で使用され、世界に対するリスクを減らすことが重要だと述べています。
この研究報告は非常に率直に書かれており、著者の原文を読んでみたい場合は、オリジナルを確認することをお勧めします。