[19.05] EfficientNet

Compound Scaling
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Common methods to enhance the performance of convolutional neural networks (CNNs) include:
- Deeper Networks: Increasing network depth, such as with ResNet.
- Wider Networks: Increasing network width, like WideResNet.
- Higher Resolution: Increasing the input image resolution.
While incremental improvements from these methods can be gratifying, the authors of this paper argue for a more holistic approach.
Defining the Problem
The authors of this paper suggest a unified approach to scaling models and propose a method called Compound Scaling.
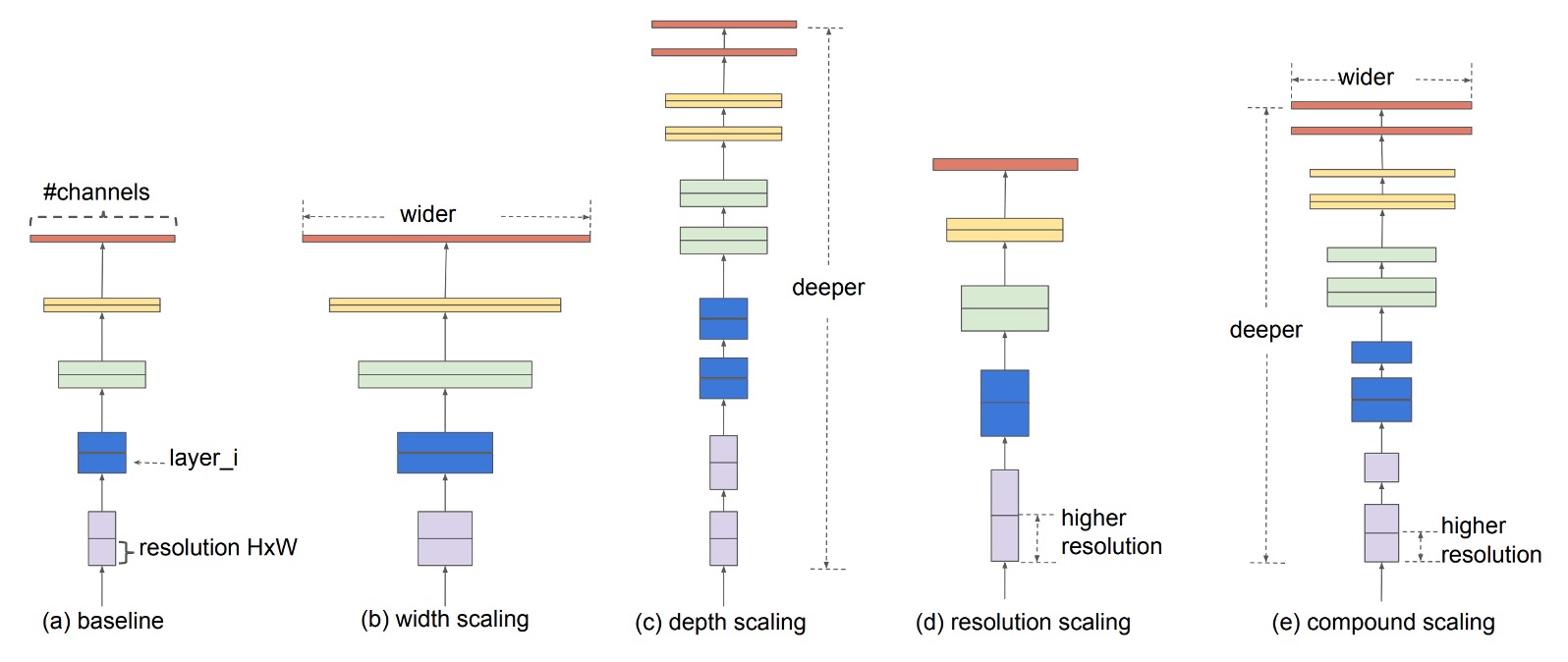
Solving the Problem
Two Key Observations
In this paper, the authors present two critical observations that form the foundation of their compound scaling method:
-
Observation 1: Any single dimension scaling improves accuracy, but the improvement saturates as the model size increases.
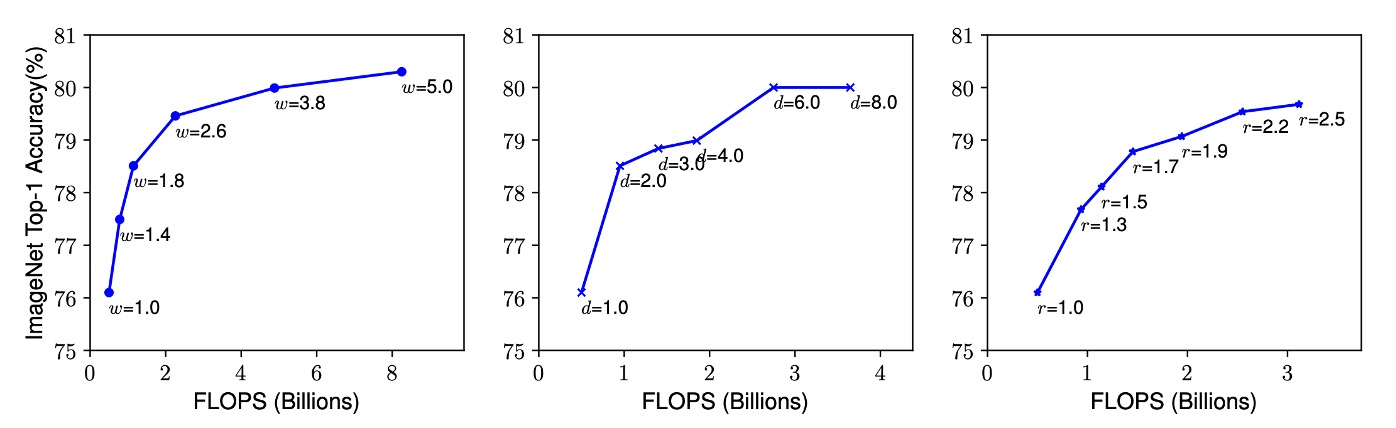
Scaling the depth, width, or resolution of a convolutional neural network (CNN) typically enhances its accuracy. However, as the network becomes extremely deep, wide, or high-resolution, the accuracy gains quickly diminish and eventually plateau. This suggests that simply increasing one dimension cannot infinitely improve model performance and will ultimately hit a bottleneck.
-
Observation 2: Balancing network width, depth, and resolution is crucial for effective model scaling.
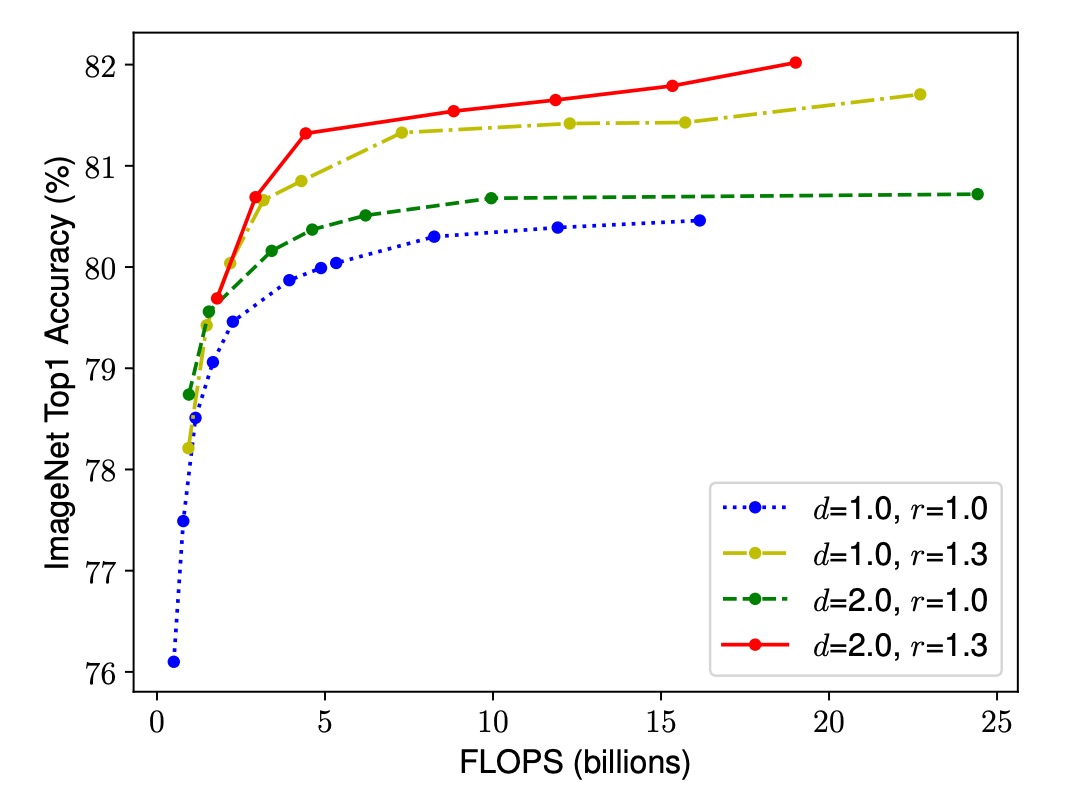
To achieve better accuracy and efficiency within given resource constraints, it is essential to balance the network's width, depth, and resolution. While individually scaling one dimension is straightforward, its impact is limited. Instead, simultaneously scaling all dimensions in a coordinated manner can utilize resources more effectively and achieve higher accuracy.
Compound Scaling
Here, the problem of model scaling is redefined:
Each layer of a CNN can be defined as a function , where is the operator, is the output tensor, and is the input tensor. The entire CNN can be represented as a combination of these layers: . Typically, the layers in a CNN are divided into stages, with all layers in a stage sharing the same architecture.
Therefore, a CNN can be defined as:
where denotes the layer being repeated times in the -th stage.
The goal of model scaling is to maximize accuracy within given resource constraints. Specifically, we aim to optimize the model by adjusting its depth (), width (), and resolution () while keeping the basic network architecture unchanged.
This can be formalized as an optimization problem:
Subject to:
The authors propose a compound scaling method using a compound coefficient to uniformly scale the network's width, depth, and resolution:
Subject to , where , , and are constants determined by a small grid search, and is a user-specified coefficient controlling the scaling resources.
This method ensures balanced scaling across all dimensions, achieving better accuracy under given resource constraints with moderate increases in computational cost (FLOPs).
Base Model Architecture
To develop an effective baseline network, the authors leveraged Multi-Objective Neural Architecture Search (NAS) to optimize both accuracy and FLOPs.
They used as the optimization objective, where and represent the accuracy and FLOPs of model , respectively. is the target FLOPs, and is a hyperparameter controlling the balance between accuracy and FLOPs.
The search yielded EfficientNet-B0, whose architecture is similar to MnasNet but slightly larger, targeting 400M FLOPs.
The table below shows the architecture of EfficientNet-B0:
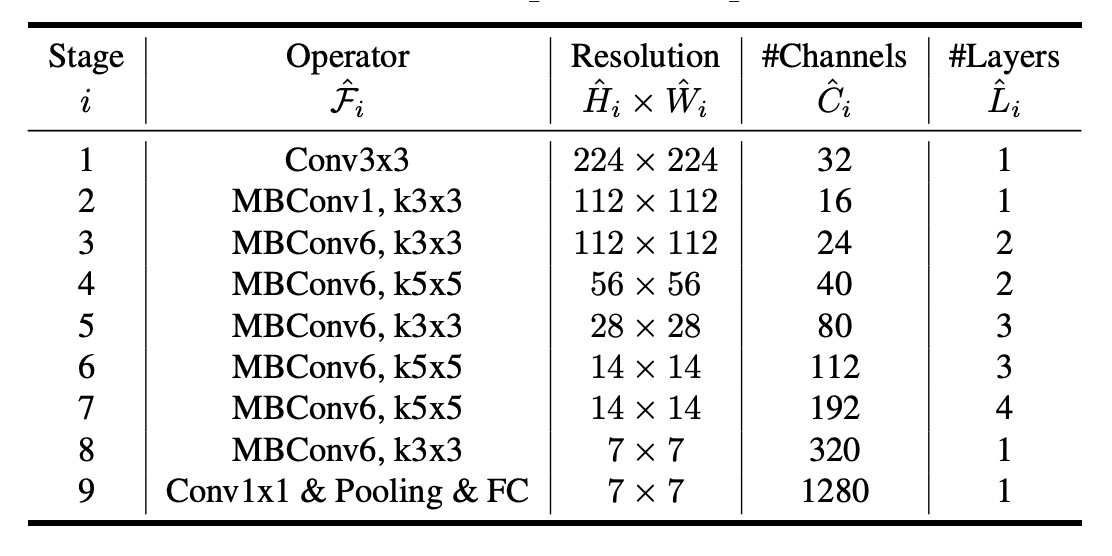
The primary building block of EfficientNet-B0 is the Mobile Inverted Bottleneck MBConv, optimized with squeeze-and-excitation.
Model Scaling Architecture
Starting from the baseline EfficientNet-B0, the authors applied the compound scaling method in two steps to scale the network:
-
Step 1: First, fix , assuming twice the resources are available, and perform a small-scale grid search based on equations 2 and 3 to determine the optimal values for , , and . For EfficientNet-B0, the optimal values were , , and , satisfying .
-
Step 2: Then, fix , , and as constants and use different values to scale the baseline network, resulting in EfficientNet-B1 to B7.
Notably, while it is possible to search for , , and directly on large models for better performance, the search cost becomes prohibitively expensive on large models. The authors' method effectively addresses this issue by performing the search once on a small baseline network (Step 1) and then scaling all other models using the same scaling coefficients (Step 2).
Discussion
Importance of Compound Scaling
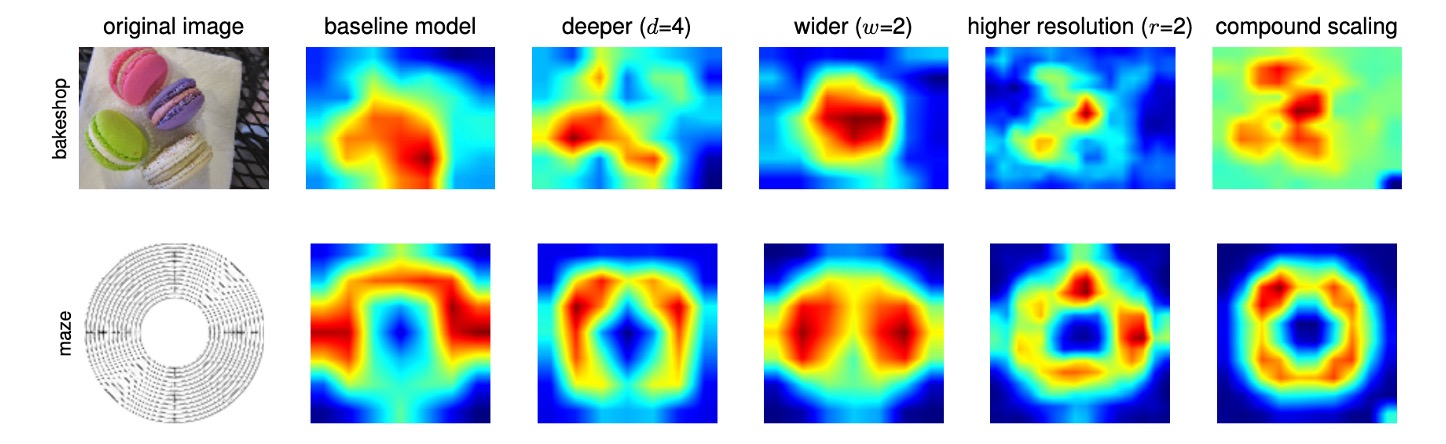
To further understand why the compound scaling method is superior to others, the authors compared class activation maps (CAM) of representative models with different scaling methods, all scaled from the same baseline (EfficientNet-B0), showing the regions of interest while processing images:
- Single-Dimension Scaling Models: Lacked focus on object details and failed to capture all objects in the image.
- Compound Scaling Models: Tended to focus on more relevant areas with richer object details, showing a more comprehensive capture of object features.
Additionally, the authors observed the performance of several scaling methods:
-
Single-Dimension Scaling Methods:
- Depth Scaling: Increasing the network depth, i.e., the number of layers.
- Width Scaling: Increasing the network width, i.e., the number of channels per layer.
- Resolution Scaling: Increasing the input image resolution.
-
Compound Scaling Method:
- Combining depth, width, and resolution growth, coordinated according to the proposed , , parameters.
The experimental results below show that although all scaling methods improve accuracy, the compound scaling method achieves significantly higher accuracy improvements, up to 2.5%. This indicates that, with the same resource increase, the compound scaling method utilizes resources more effectively, providing substantial advantages in enhancing model performance.
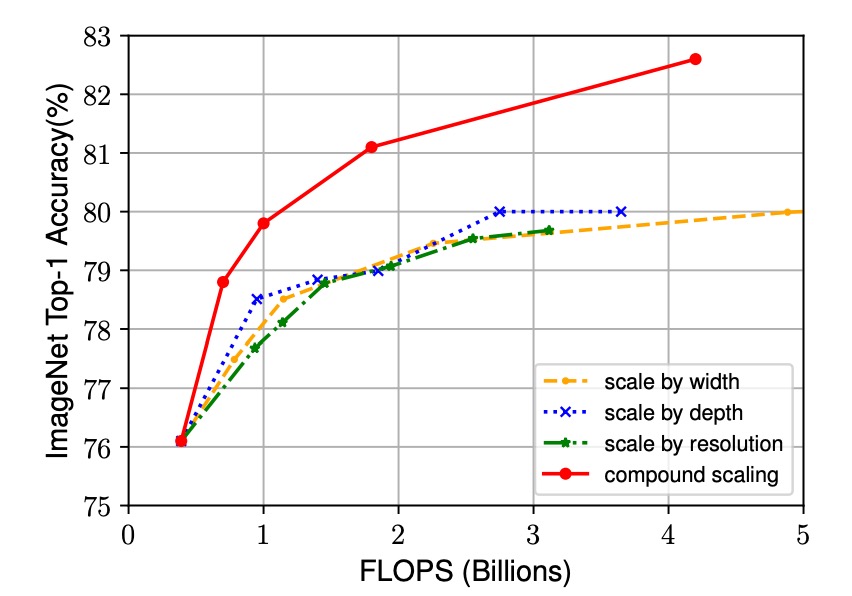
Results on ImageNet
In this paper, the authors used the following specific training configurations:
- Optimizer: RMSProp
- Weight Decay:
- Initial Learning Rate: 0.256, decaying by 0.97 every 2.4 epochs
- Activation Function: SiLU
- Data Augmentation: AutoAugment, random depth
Considering larger models require more regularization, the authors linearly increased the dropout rate from 0.2 in EfficientNet-B0 to 0.5 in EfficientNet-B7.
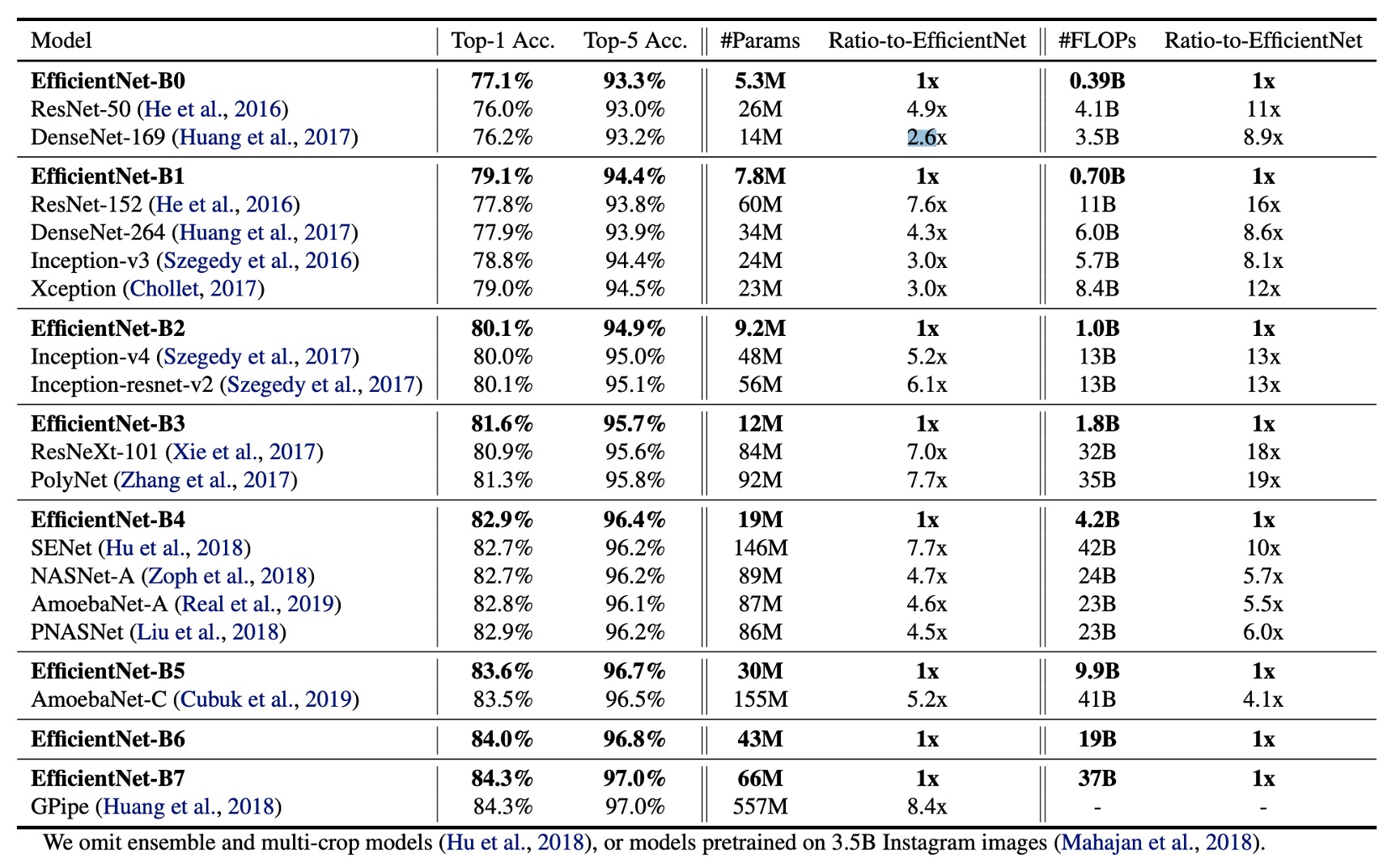
The table shows that EfficientNet models generally use an order of magnitude fewer parameters and FLOPs compared to other CNNs with similar accuracy. Specifically, EfficientNet-B7 achieves 84.3% top-1 accuracy with 66M parameters and 37B FLOPs, more accurate than the previous best GPipe, but with 8.4 times fewer parameters.
EfficientNet models are not only smaller in size but also more computationally efficient. For instance, EfficientNet-B3 uses 18 times fewer FLOPs while achieving higher accuracy than ResNeXt101.
Inference Speed
To validate latency, the authors also measured the inference latency of some representative CNNs on a real CPU.
The table below shows the average latency of 20 runs:

These results demonstrate that, compared to ResNet-152 and GPipe, EfficientNet not only excels in parameters and FLOPs but also achieves impressive inference speed on actual hardware.
Parameter-Accuracy Curve
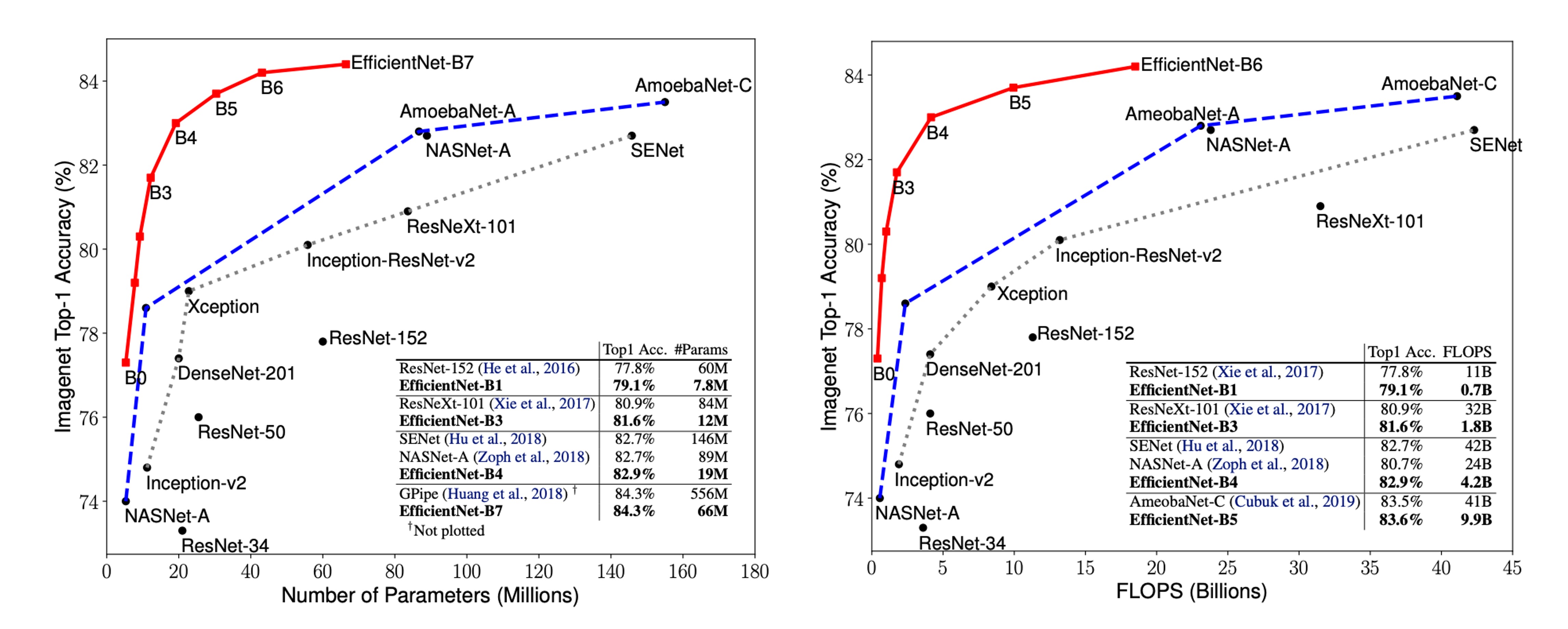
The figure above shows the parameter-accuracy and FLOPs-accuracy curves of representative CNNs, highlighting that EfficientNet models achieve higher accuracy with fewer parameters and FLOPs, underscoring their significant efficiency advantage.
Conclusion
The depth, width, and resolution of a model are crucial factors influencing the performance of convolutional neural networks.
In this paper, the authors propose a compound scaling method that balances the scaling of depth, width, and resolution to achieve better accuracy and efficiency.
Future research can further optimize the parameter selection in compound scaling methods and explore their application in other types of neural networks, advancing the efficiency and performance of deep learning models.
We read the abstract of this paper and directly adopted the model architecture. The results were indeed impressive.