[21.11] METER

繽紛的儀表板
An Empirical Study of Training End-to-End Vision-and-Language Transformers
這是一篇彙整式論文。
所以你可以預期在這裡會看到實驗,還有更多的實驗。
定義問題
當前主流的 VLP 架構主要有三個組件:
- 其一:視覺編碼器,也就是我們常講的 ViT。
- 其二:文字編碼器,最常見的是 BERT。
- 最後:共編碼器,這裡就是把視覺和文字整理起來的地方。
作者首先整理了過去研究中使用架構的總表,然後把他們拆了,重新組合。

說到底,就是視覺組件的問題:
首先是效率差。
在許多 VLP 的研究中,多數模型依賴於目標檢測器(如 Faster RCNN)來提取區域特徵。這些檢測器通常在 VLP 過程中保持凍結狀態,這限制了 VLP 模型的容量。此外,提取區域特徵的過程非常耗時,這可能會影響模型的效率和實用性。
其次是探索不足,完全基於 Transformer 的 VLP 模型,仍然未得到充分的探索。有一些基於 ViT 模型在下游任務如視覺問答等方面仍然落後於最先進的性能。
最後是優化器不一致,有些研究嘗試將卷積神經網路和文字的網格特徵直接輸入到 Transformer 中,但遇到了優化器不一致的問題,通常在 CNN 和 Transformer 中使用不同的優化器。最近的研究顯示,與 ViT 相比,CNN 在精度和計算成本(FLOPs)上的表現稍差。
看到作者提到「優化器不一致」的部分,其實這就是在說 SimVLM。
解決問題
METER 模型設計
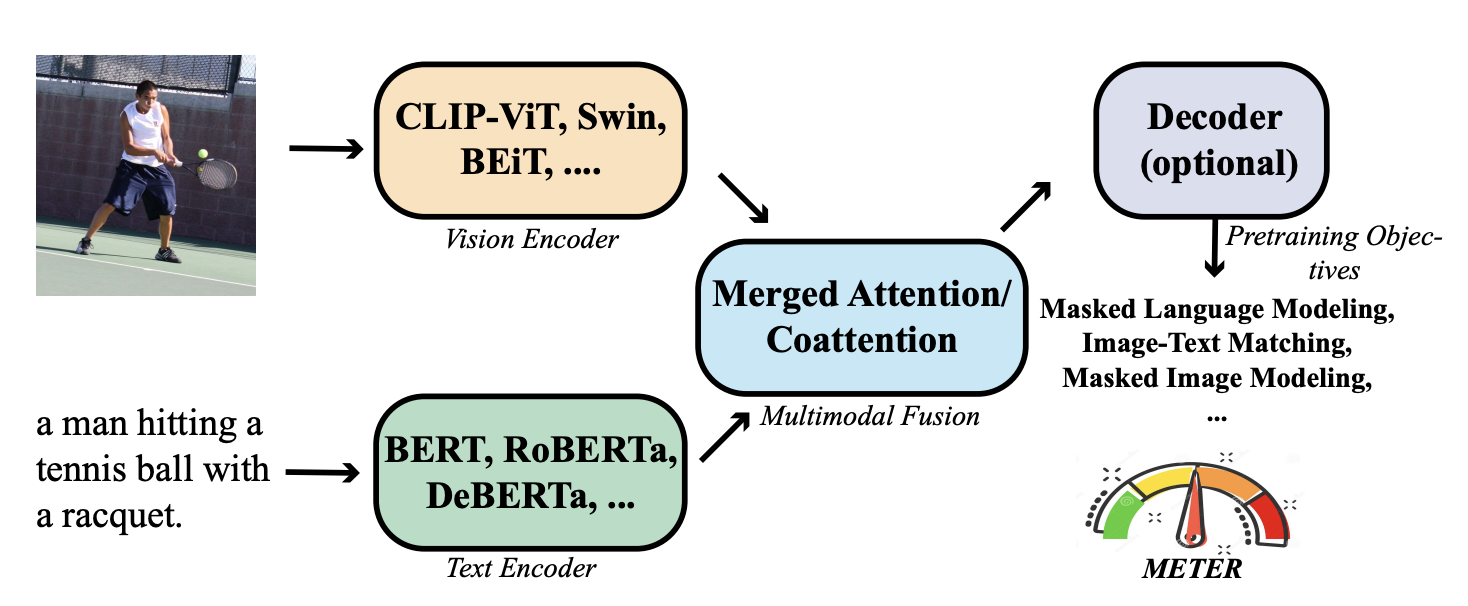
作者把測試單元拆成幾個部分:視覺編碼器、文字編碼器、多模態融合模組、架構設計和預訓練目標。
-
Vision Encoder 挑選
在 ViT 的機制中,影像首先被分割成多個 patch,然後這些 patch 被輸入到 Transformer 模型中進行處理。
作者比較了多種不同的 ViT 模型,包括下列:
- ViT (2020.10):
- DeiT (2020.12):
- CLIP (2021.03):
- Swin Transformer (2021.03):
- CaiT (2021.03):
- VOLO (2021.06):
- BEiT (2021.06):
-
Text Encoder 挑選
作者的目標是在將特徵發送到融合模組之前首先使用文字編碼器。他們探索了使用不同的語言模型,如 BERT、RoBERTa、ELECTRA、ALBERT 和 DeBERTa 進行文本編碼。除了使用不同的語言模型外,作者還嘗試使用一個簡單的字嵌入查找層,該層由 BERT 嵌入層初始化。
我們同樣把作者所選用的架構放上來:
- BERT (2018.10):
- RoBERTa (2019.07):
- ALBERT (2019.09):
- ELECTRA (2020.03):
- DeBERTa (2020.06):
-
Multimodal 架構
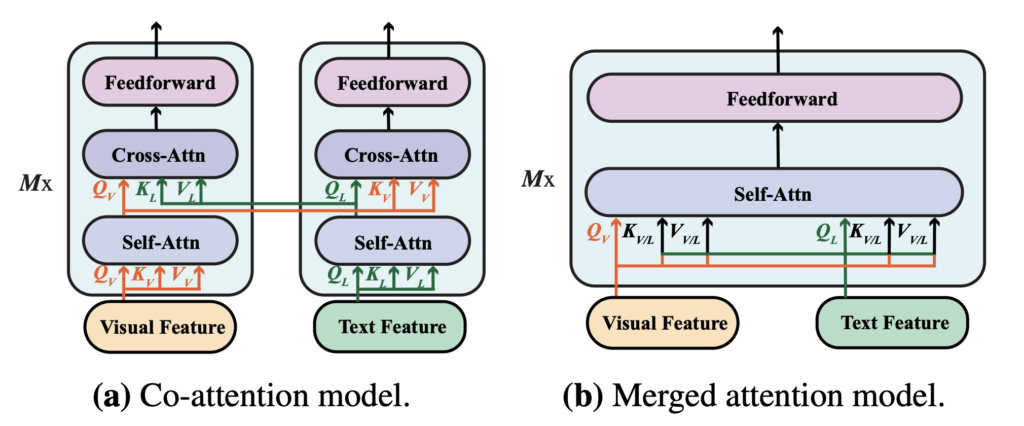
VLP 模型越來越流行,作者在新環境中重新評估了這兩種融合模組的影響,要驗證哪種融合策略更有效。
- 合併注意力模組:在此模組中,文字和視覺特徵被簡單地連接在一起,然後一起輸入到單一的 Transformer 模組中。這種方法允許在同一個 Transformer 模組中同時處理文本和視覺信息。
- 共同注意力模組:共同注意力模組將文字和視覺特徵獨立地輸入到不同的 Transformer 模組中。這個模組使用交叉注意力技術來實現跨模式的互動,即在視覺和文本特徵之間實現互動。
Encoder-Only vs. Encoder-Decoder
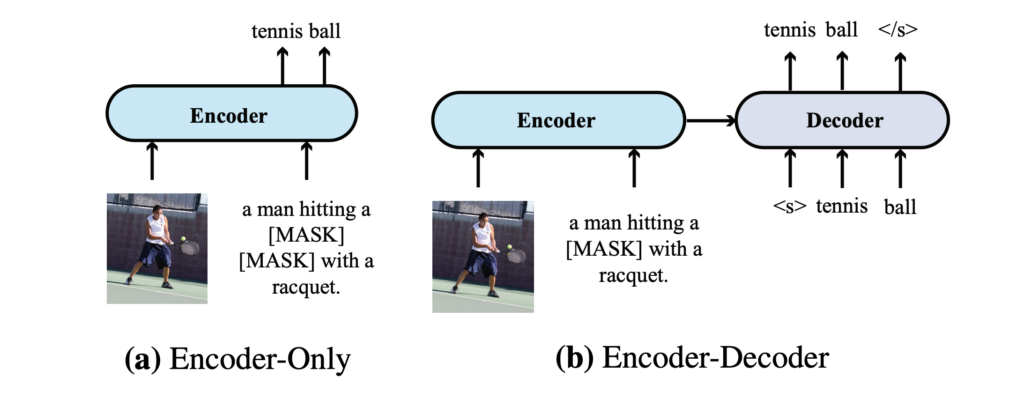
作者比較了兩種不同的模型架構:僅「編碼器」架構和「編碼器-解碼器」架構,並探討了它們在 VLP 模型中的應用:
- 僅編碼器架構:在這種架構中,跨模態表示(例如視覺和文本特徵的結合)直接輸入到輸出層以產生最終輸出。VisualBERT 是採用僅編碼器架構的 VLP 模型的一個例子。
- 編碼器-解碼器架構:有名的工作像是 VL-T5 和 SimVLM,提倡使用編碼器-解碼器架構。在這種架構中,跨模態表示首先輸入到解碼器,然後再輸入到輸出層。解碼器在此過程中同時關注編碼器的表示和先前產生的標記,以自回歸的方式產生輸出。
兩種架構差異如上圖,在 VQA 這個任務上的時候,編碼器-解碼器模型將文字輸入到編碼器,將分類標記輸入到解碼器;如果是編碼器模型,則直接將跨模態表示輸入到輸出層。
預訓練策略
作者挑出了在 VLP 模型中的三種主要預訓練任務,包括:掩蔽語言建模(MLM)、圖像文字匹配(ITM)和掩蔽影像建模(MIM):
-
掩蔽語言建模(MLM)
初始於純語言預訓練,後於 VLP 中延伸應用,目的是在給定圖像標題對時,隨機屏蔽一些輸入標記,並訓練模型以重建這些屏蔽的標記。
-
圖像-文字匹配(ITM)
模型需要辨識哪些圖像和標題相互匹配,通常作為二元分類問題。模型學習全域跨模態表示,並利用分類器預測是否匹配。
-
掩蔽影像建模(MIM)
這是一種在視覺預訓練模型中應用的技術,其靈感主要來自於掩蔽語言建模(MLM)。在 MIM 中,模型的目的是在某些視覺特徵被屏蔽或隱藏的情況下,嘗試重建或預測這些被屏蔽的視覺特徵。
這裡沒有提到剛剛獲得成功 PrefixLM,我們認為主要的原因可能是作者認為 PrefixLM 並不是主流的方法,而且 SimVLM 的成功主要原因可能是他們的資料集規模龐大,因此沒有特別拿出 PrefixLM 進行討論。
資料集
模型在四個常用資料集上預先訓練,包括 COCO、Conceptual Captions、SBU Captions 和 Visual Genome,依循著先前的研究,組合訓練資料共包含約 4M 張圖片。
技術細節
- 除非另有說明,隱藏層大小設定為 768, Head 設定為 12。
- 視覺分支和語言分支之間沒有解碼器,也沒有參數共享。
- 除特殊情況外,模型僅使用 MLM 和 ITM 進行預訓練。
- 使用 AdamW 預先訓練模型 100,000 步,底層和頂層的學習率分別設定為 1e-5 和 5e-5。
- 預熱比率為 10%,學習率在總訓練步數的 10% 後線性衰減到 0。
- 每個影像的大小調整為 224×224 或 384×384。
討論
模組分開評估
因為預訓練過程非常耗時,為了提高效率,研究首先透過比較不同的文字和視覺編碼器而不進行 VLP 來進行:
- 使用特定的預訓練視覺和文字編碼器來初始化模型的底層,而頂層則進行隨機初始化。
- 預設選擇的編碼器為 CLIP-ViT-224/32 和 RoBERTa,其中 ViT-N/M 中的 N 和 M 分別代表影像解析度和區塊大小。
-
Text Encoder 評比
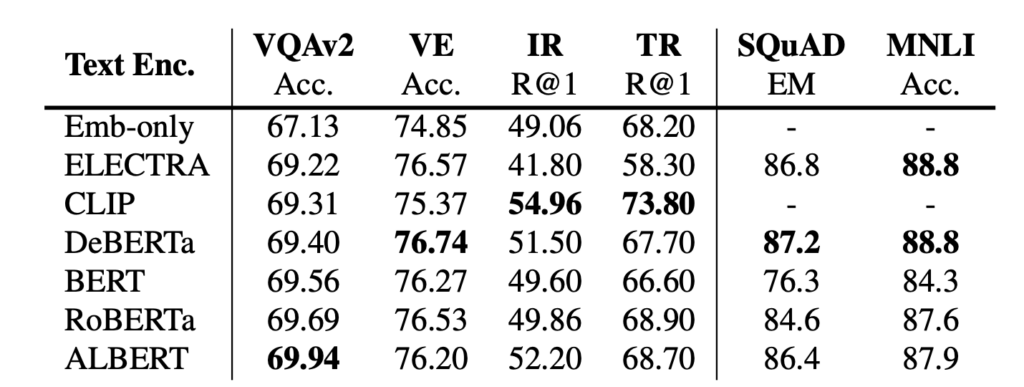
不同文字編碼器的模型表現並沒有顯著差異。RoBERTa 似乎在此設定中實現了最強的性能。此外,從 Emb-only 結果可以看出,有必要有一個預先訓練的編碼器,否則下游任務表現將會下降。
-
Vision Encoder 評比
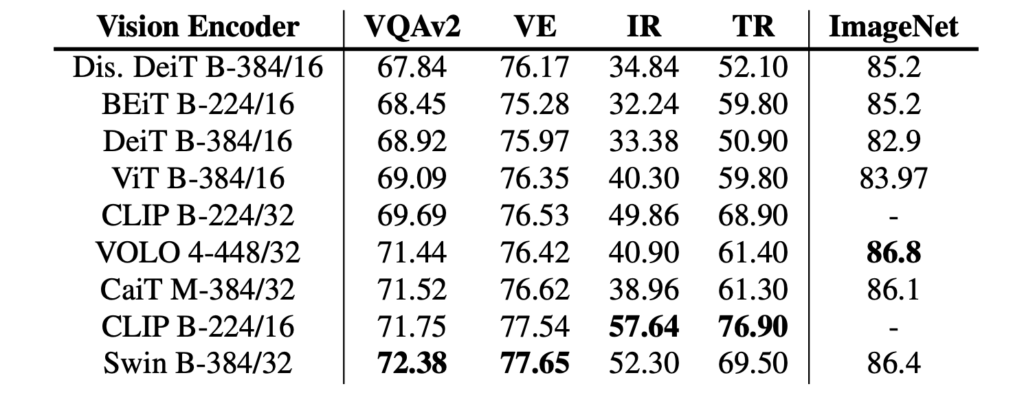
CLIP-ViT-224/16 和 Swin Transformer 在此設定下均可達到不錯的效能。但 Swin Transformer 在沒有任何 VLP 的測試訓練集上可以達到 72.38 的 VQA 分數,這在預訓練後已經可以與一些 VLP 模型相媲美。
V+L 綜合評估
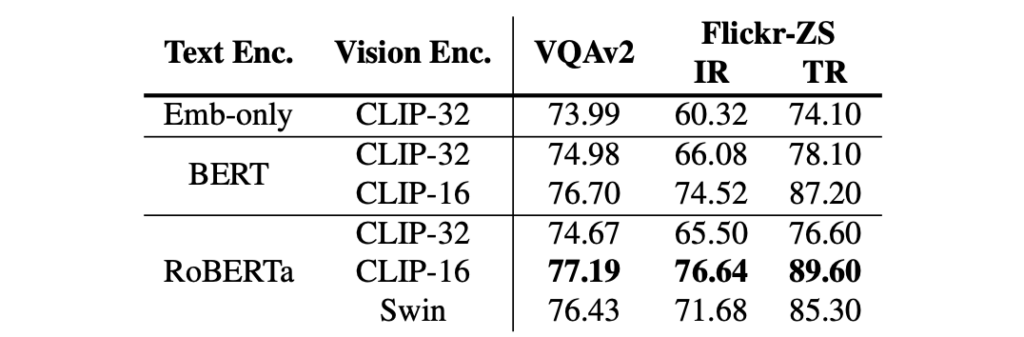
兩者搭配,成為 VLP 架構之後,BERT 和 RoBERTa 之間的差異似乎縮小了,但在底部有一個預先訓練的文本編碼器仍然很重要(Embed-only 與 RoBERTa)。
對於視覺編碼器,CLIP-ViT-224/16 和 Swin Transformer 都可以達到相當不錯的性能。特別是 CLIP-ViT-224/16 在 test-dev/test-std 集合上分別可以達到 77.19/77.20 的 VQA 分數,優於先前的 VinVL 模型。
來自論文作者的友情提示:
作者有提供一個有趣的技巧,用來提升模型表現:相較於使用預訓練模型初始化的參數,對於隨機初始化的參數使用更大的學習率是更好的。
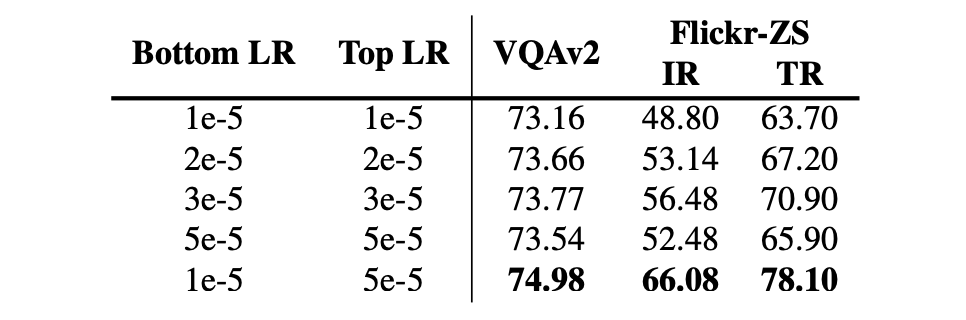
如果對模型的所有部分使用相同的學習率,會使得模型效能下降。這可能是因為預訓練的參數已經包含了一些視覺和語言方面的知識,而過於積極的微調可能會損失這些有價值的資訊。
特徵融合探討

作者設計了合併注意力模型和共同注意力模型並比較了它們的表現。
實驗結果表示:共同注意力模型的表現優於合併注意力模型,這表示保持兩種模式具有不同參數集是重要的。不過,這個結果與先前基於區域的 VLP 模型的研究結果有所矛盾,作者認為這可能是因為:
- 基於區域的 VLP 模型的研究結果不一定能直接應用於基於 ViT 的 VLP 模型。
- 大部分的基於區域的 VLP 模型只使用預先訓練的視覺編碼器,而不包含預先訓練的文字編碼器,這使得像共同注意模型這樣的對稱架構在這些情況下可能不太適用。
另一方面,在實驗 Encoder 對比 Encoder-Decoder 架構的部分,實驗根據文獻採用了 T5 風格的語言建模目標,屏蔽了 15% 的輸入文字標記,使用哨兵標記替換了連續的文字範圍,並訓練解碼器來重建被屏蔽的標記。對於圖像文字匹配任務,向解碼器提供了特殊的類別標記以生成二進位輸出。
結果顯示,僅編碼器模型在兩個判別任務上的表現優於編碼器-解碼器模型,這與文獻的發現一致。但編碼器-解碼器架構更為靈活,能夠執行如影像字幕等任務,這對僅應用編碼器的模型來說可能較為困難。
擴大資料集規模

作者通過使用更多的圖像和更大的視覺主幹來進行模型的預訓練,來驗證這個框架的可擴展性。具體的預訓練資料包括 COCO、CC、CC12M、SBU 和 VG 這五個資料集,它們總共提供了大約 1400 萬張圖像和 2000 萬張圖像標題對,為模型的預訓練提供了豐富的資料。
在視覺主幹的選擇上,採用了 CoSwin-Huge 作為視覺主幹,它有能力處理大量的視覺資料。文字主幹方面,選擇了 RoBERTa-base 來進行文字的處理,這個選擇保證了文字資訊能夠被有效地編碼。
通過擴展後的設定,模型在 VQAv2 上表現出最先進的性能,超越了之前使用了 18 億張圖像訓練的 SimVLM,這個結果證明了 METER 框架具有很好的可擴展性,可以通過增加資料和調整模型結構來達到更好的效果。
結論
這篇論文透過系統地研究如何以端到端的方式訓練一個 full-transformer VLP 模型。實驗表明,我們只需 400 萬張圖像進行預訓練,就可以透過最先進的模型獲得具有競爭力的性能。當進一步擴大規模時,METER 在 VQA 上達到了新的最先進水平。
作者組合 V+L 的模型 時,統一採用了相同的邏輯,而沒有針對不同的架構進行最優調整。這種「一刀切」的方法可能未能充分發揮每種架構的獨特優勢,同時也可能掩蓋了某些潛在問題的發現。
-
RoBERTa 有別於 BERT 採用了新的動態 MASK 機制,但在本論文中卻都一致地使用 MLM 策略?Vision Encoder 的部分也同樣沒有看到什麼細緻的操作,就只是拿個效果比較好的架構,然後把它湊成 V+L 的模型?
-
SimVLM 所採用的 PrefixLM 如果用在作者所提出來的架構上,效果會如何呢?當不同的文字和圖像主幹結合時,是否該搭配不同的參數設定和優化技巧,以確保各種架構的最佳表現?以及嘗試了多種多模態融合策略,以驗證模型的泛化能力和穩定性?