[24.05] DeepSeek-V2

開源節流
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
之前的論文正說著要來試試看 MoE 的效果,這沒隔三個月就來了一篇論文。
這篇論文有 52 頁,其中有大量的實驗數據和技術細節,所以老樣子,我們挑重點看。
數學警告:本篇論文的重點在於模型模組的優化,其中內含大量數學,請謹慎閱讀。
定義問題
近年來,隨著大型語言模型的快速發展,參數數量的增加確實帶來了模型能力的顯著提升,甚至展現出一些「突現能力」,讓我們看到了向通用人工智慧邁進的希望。
然而,這種提升往往伴隨著巨大的計算資源消耗,不僅訓練成本極高,而且在推理時也會因為計算和記憶體瓶頸而導致效率降低,從而影響了這些模型在實際應用中的普及和部署。
因此,DeepSeek 研究團隊圍繞著計算瓶頸和效率問題展開,提出了 DeepSeek-V2 模型,旨在在保持強大性能的同時,提高計算效率,降低訓練和推理成本。
解決問題
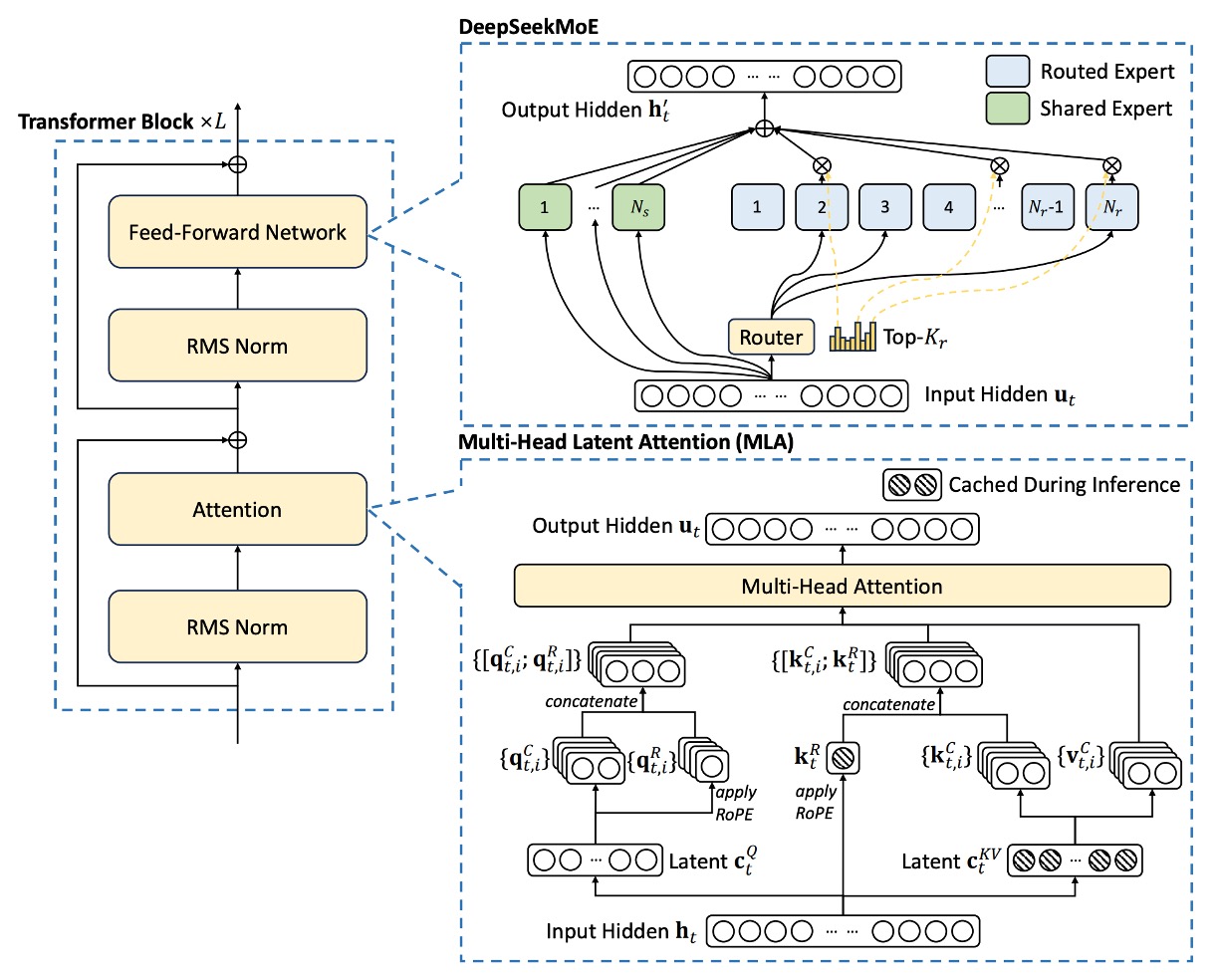
DeepSeek‑V2 仍採用標準 Transformer 結構,每個 Transformer block 包含一個注意力模組和一個前饋網路(FFN)。
- 注意力模組:研究團隊提出 MLA,利用低秩鍵值聯合壓縮來解決傳統 MHA 在生成時所面臨的 KV 快取瓶頸問題。
- 前饋網路:採用了 DeepSeekMoE 架構,這是一種高效能的 Mixture-of-Experts 模型,使得在成本有限的情況下訓練出強大的模型。
其餘細節(如 Layer Normalization 與激活函數)則沿用 DeepSeek 67B 的設置,整體架構設計如下圖所示:
Multi-head Latent Attention
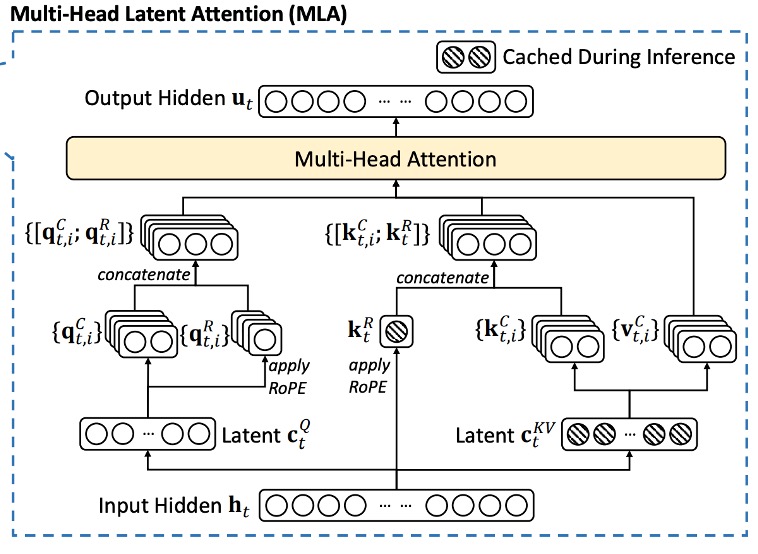
在標準多頭注意力機制(MHA)中,假設:
- :嵌入維度
- :注意力頭數
- :每個頭的維度
- :第 個 token 的輸入表示
透過三個投影矩陣 、 與 ,其尺寸皆為 ,分別計算查詢(query)、鍵(key)與值(value):
接著,這些向量會被切分成 個頭,記作:
並對每個頭進行注意力計算:
最終透過輸出投影矩陣 組合各頭的輸出:
到這裡,大家都很熟,就是標準的 MHA 運算流程。
但問題在於:在推理階段,為了加速計算,需要將所有的 keys 與 values 快取起來,這導致每個 token 都要存儲 個元素,當序列長度較大時,記憶體開銷呈平方級上升,成為嚴重瓶頸。
因此,MLA 的核心在於利用「低秩壓縮」方法減少 KV 快取。
具體步驟如下:
-
鍵值壓縮: 對於每個 token,我們先計算其壓縮後的潛在表示:
其中 ,,而 為下投影矩陣。
-
上投影恢復鍵與值: 從壓縮表示中恢復鍵與值
其中 與 分別為鍵和值的上投影矩陣,其尺寸為 。
在推理時,只需要快取 ,即每個 token 僅存儲 個元素,即可大大降低了記憶體開銷。
此外,因為 可與 吸收合併, 則可與 吸收合併,從而在實際注意力計算中不需要額外顯式計算鍵與值。
最後,為了降低訓練時的激活記憶體,研究團隊在實作中也對查詢向量也進行了類似的低秩壓縮:
其中 為查詢的壓縮表示,且 。
解耦旋轉位置編碼
Rotary Position Embedding(RoPE)是一種在 Transformer 中引入位置資訊的方法,但其對鍵與查詢都是位置敏感的。在低秩壓縮的情況下,如果直接對壓縮後的鍵 應用 RoPE,則會使得上投影矩陣 與位置資訊耦合,從而破壞前面所做的吸收合併優化,並迫使在推理時必須對前綴 token 重新計算鍵。
等等,怎麼這段好像看不懂?
沒關係,我們來簡化一下:假設你把十個人的名字壓縮成一個名字,
想像你原本有十個人的名字,像是「小明、阿華、小美、阿強……」這些名字本來都有各自的位置順序。為了節省空間,你決定把這十個名字合併,壓縮成一個綜合名字,比如「明華美強……」。這樣做的好處是節省了儲存空間,管理起來也比較方便。
但是,如果你在這個壓縮後的綜合名字上再額外加上每個原始名字的位置資訊(例如在合併後的名字前面標上原來的順序),那麼這個綜合名字就跟那個位置資訊緊密綁定了。
結果就是:每當你想要添加新名字或查詢之前名字的順序時,都必須先把這個綜合名字重新拆開來,再重新計算每個人的正確順序。這就破壞了最初壓縮所帶來的便利性,增加了後續處理的負擔。
在 Transformer 中,RoPE 就類似這個情況。RoPE 是用來給鍵與查詢加上位置信息的方法,但如果你對已經壓縮過(低秩壓縮)的鍵直接應用 RoPE,就好比在那個綜合名字上再加上位置資訊。這樣一來,上投影矩陣(相當於我們後續處理的工具)就會和這些位置信息糾纏在一起,導致每次推理時,如果有新的 token 進來,都必須重新計算前面所有 token 的鍵。這不但降低了效率,也破壞了先前那個壓縮的好處。
研究團隊在這裡提出了解耦 RoPE 策略,具體方法是:
增加額外的多頭查詢 與共享的鍵 用以攜帶 RoPE 的位置資訊。
再分別計算:
其中 與 是用於產生解耦查詢與鍵的矩陣。
最終,將壓縮部分與解耦部分連接:
並進行注意力計算:
最後利用 組合各頭的輸出:
這樣的設計使得 RoPE 的位置資訊與低秩壓縮部分解耦,從而保留了位置編碼的優勢,又不影響前面吸收矩陣的優化,使得推理過程中不必對前綴 token 重新計算鍵。
DeepSeekMoE
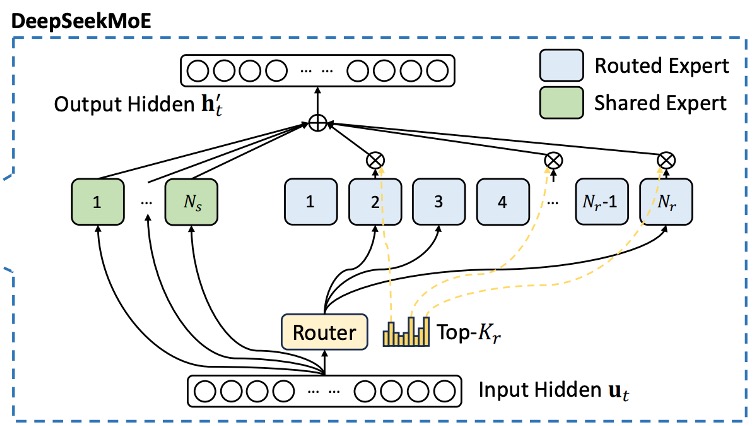
有別於傳統的 MoE 模型,DeepSeekMoE 對專家進行更細緻的切分:將 FFN 模組拆分成兩部分:
- 共享專家(Shared Experts):固定數量的專家,每個 token 都會利用這部分的知識。
- 路由專家(Routed Experts):動態選擇部分專家參與運算。
對於第 個 token,其 FFN 輸入為 ,最終的 FFN 輸出 定義為:
其中:
- 為共享專家的數量,
- 為路由專家的數量,
- 與 分別代表第 個共享專家與路由專家的前饋運算。
路由專家的選擇依賴於一個門控機制,具體定義如下:
其中 為激活的路由專家數量, 是 token 與第 個路由專家間的親和分數,計算方式為:
這裡 表示第 個路由專家的「質心」,用以代表該專家的特徵中心。
在 MoE 模型中,當專家分佈於多個設備上時,每個 token 的路由決策可能涉及跨設備通訊。若激活的專家數量較多,這將帶來額外的通信成本。為了控制這一成本,DeepSeekMoE 採用了裝置限制式路由機制:
- 對於每個 token,首先在所有設備中選擇 個擁有最高親和分數的設備。
- 然後僅在這 個設備內進行 Top-K 的專家選擇。
實驗觀察結果是當 時,這種限制不僅能大幅降低跨設備通信,且其效果與無限制的 Top-K 選擇在性能上十分接近。
這個策略的核心在於平衡模型的路由品質與設備間的通信負擔,從而在大規模分布式環境下達到較高的運算效率。
如果你對 Mixture-of-Experts(MoE) 不太熟悉,可以參考我們之前的筆記:
輔助平衡損失
由於 MoE 模型容易出現某些專家被過度激活(或甚至完全未被使用)的情況,這不僅會導致「路由崩潰」,也會降低計算效率。為此,DeepSeekMoE 設計了三種輔助損失來促進負載均衡:
-
專家層級平衡損失(Expert-Level Balance Loss)
其中,
- 為序列中 token 的總數,
- 為指示函數,
- 為超參數,用於調整損失的權重。
這部分損失旨在使各個路由專家的激活頻率和平均親和分數保持平衡。
-
裝置層級平衡損失(Device-Level Balance Loss)
將所有路由專家分成 組(每組 放置於同一設備上),定義損失為:
其中,
- 為設備層級平衡超參數。
這有助於確保不同設備之間的計算負載均衡,避免某一設備過載而成為瓶頸。
-
通信平衡損失(Communication Balance Loss)
即使採用裝置限制式路由,若某些設備接收的 token 明顯多於其他設備,也會影響通信效率,因此引入:
其中,
- 為通信平衡超參數。
這項設計鼓勵每個設備之間保持相近的通信量,從而提升跨設備的計算協調效率。
最後除了平衡損失之外,研究團隊還引入了設備級令牌丟棄策略,用以進一步減輕負載不平衡造成的計算浪費。具體方法是:
- 計算每個設備的平均計算預算,使得每個設備的容量因子相當於 1.0。
- 對每個設備上丟棄親和力分數最低的令牌,直到達到計算預算。
- 確保屬於約 10% 訓練序列的 token 永遠不會被丟棄。
這樣,就可以根據效率要求靈活決定是否在推理過程中丟棄 token,始終確保訓練和推理的一致性。
訓練策略
論文中保持了與 DeepSeek 67B 相同的數據處理流程,但在此基礎上:
- 擴大數據量: 優化清洗流程,找回之前錯誤刪除的大量數據。
- 提高數據品質: 加入更多高品質資料,尤其是中文資料(中文 token 大約比英文多 12%),同時改進了基於品質的過濾算法,確保去除大量無益資訊,同時保留有價值的內容。
- 過濾爭議內容: 這個策略旨在減少來自特定區域文化的偏見。
Tokenizer 使用與 DeepSeek 67B 相同的 Byte-level Byte-Pair Encoding(BBPE)算法,詞彙量設定為 100K,使得最終的預訓練語料包含 8.1T tokens。
模型超參數配置如下:
- Transformer 層數:60 層
- 隱藏層維度:5120
- 所有可學參數隨機初始化時標準差設定為 0.006
- MLA 相關:
- 注意力頭數 設定為 128
- 每頭維度 為 128
- KV 壓縮維度 為 512
- 查詢壓縮維度 為 1536
- 解耦查詢與鍵的每頭維度 為 64
MoE 層配置如下:除第一層外,其餘 FFN 層均替換為 MoE 層。
- 每個 MoE 層包含 2 個共享專家和 160 個路由專家
- 每個專家的中間隱藏維度為 1536
- 每個 token 激活 6 個路由專家
- 為了應對低秩壓縮和細粒度專家分割對層輸出規模的影響,論文中額外加入 RMS Norm 層以及額外的縮放因子,以確保訓練穩定性
最終,DeepSeek‑V2 總參數量達到 236B,但每個 token 僅激活 21B 參數。
訓練超參數如下:
- 優化器:AdamW,超參數 、、weight_decay = 0.1
- 學習率調度:先在前 2000 步線性增長,再依據預定比例(約 60% 與 90% token 數量)分別乘以 0.316,最大學習率 2.4×10⁻⁴
- 梯度裁剪設定為 1.0
- 批次大小採用逐步調整策略,從 2304 增至 9216,之後保持 9216
- 最大序列長度設定為 4K,並在 8.1T tokens 上進行訓練
- 其他平行化設置:
- 利用 pipeline parallelism 將不同層部署在不同設備上
- 路由專家均勻部署在 8 個設備上()
- 裝置限制式路由設定每個 token 最多傳送到 3 台設備()
- 輔助平衡損失中的超參數分別設置為 、、
- 訓練時採用 token-dropping 策略來加速,但評估時不丟棄 token
初步預訓練完成後,研究團隊中使用 YaRN 方法將模型的默認上下文窗口從 4K 擴展到 128K。
特別針對負責攜帶 RoPE 的解耦共享鍵 進行擴展,設定參數:scale 、、,目標最大上下文長度設定為 160K。
為了適應獨特的注意力機制,調整了長度縮放因子,使得 的計算公式為
以期最小化 perplexity
在長上下文擴展階段,額外訓練 1000 步,序列長度設為 32K,批次大小為 576 序列。儘管訓練時只使用 32K 長度,模型在評估時在 128K 上下文長度下依然表現強健。根據“Needle In A Haystack”(NIAH)測試,模型在各種上下文長度下均有不錯的表現。
模型對齊
為了讓模型更好地對齊人類偏好,進一步提升回答的正確性與滿意度,作者進行了強化學習調整。這裡使用的是 Group Relative Policy Optimization(GRPO)算法,其主要優勢在於節省訓練成本,因為它省去了需要與策略模型同規模的 critic 模型,並改由群組分數來估算 baseline。
強化學習的訓練策略分為兩個階段:
-
第一階段:推理對齊(Reasoning Alignment)
在這個階段,作者針對編程與數學等推理任務,訓練一個專門的獎勵模型 :
這有助於模型在這類任務上持續提升其解題能力。
-
第二階段:人類偏好對齊(Human Preference Alignment)
在此階段,採用了多獎勵框架,從三個方面獲得獎勵:
- 幫助性獎勵模型
- 安全性獎勵模型
- 規則基獎勵模型
最終,對於某個回應 ,獎勵值計算為:
其中 為相應的係數。這種多獎勵設計幫助模型在生成回應時同時考慮多方面的品質指標。
為了獲得可靠的獎勵信號,研究團隊採集了大量偏好數據:
- 編程任務的偏好數據基於編譯器反饋,
- 數學任務則基於真實標籤。
獎勵模型初始化使用 DeepSeek-V2 Chat (SFT) 的結果,並利用點對點或成對損失來進行訓練。
討論
篇幅有限,我們來看一下 AlignBench 的結果,如果你對其他實驗結果感興趣,可以參考原文。
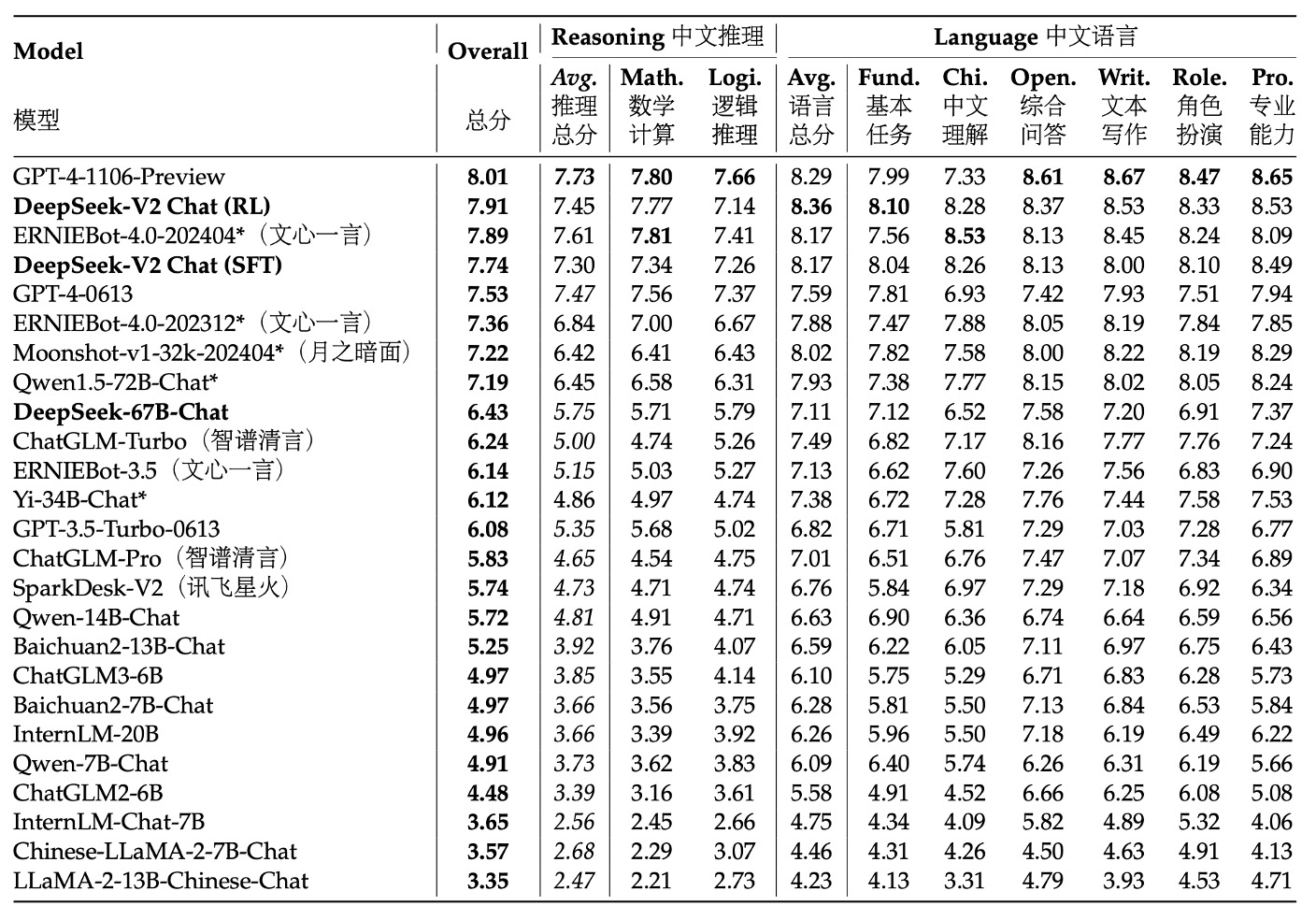
表中各模型根據它們在 AlignBench 上的整體表現得分排序,得分高的模型排名靠前,這反映了它們在中文對話生成或理解等任務上的綜合能力。評分是由 GPT-4‑0613 完成的,這意味著我們用這個強大的模型作為評判標準,來衡量各個模型生成結果的品質和上下文相關性。
實驗結果顯示在在中文生成任務中,DeepSeek‑V2 Chat (RL) 相較於 (SFT) 有輕微的優勢,且已經大幅超越了所有其他開源中文模型,尤其在中文推理與語言能力上,比第二名的 Qwen1.5 72B Chat 表現更為突出。
在中文理解能力上,DeepSeek‑V2 Chat (RL) 甚至優於 GPT‑4‑Turbo‑1106‑Preview。然而,在推理能力上,DeepSeek‑V2 Chat (RL) 仍落後於部分巨型模型,如 Erniebot‑4.0 與 GPT‑4。
這些評測結果展示了 DeepSeek‑V2 Chat 模型在不同調整策略下的優勢:透過 RL 微調,不僅能在英文對話生成上取得顯著優勢,在中文理解上也展現出極高水準,雖然在部分推理任務上還有提升空間。這表明了該模型在生成高品質、指令式對話方面具有很強的競爭力,同時也指明了未來改進的方向。
結論
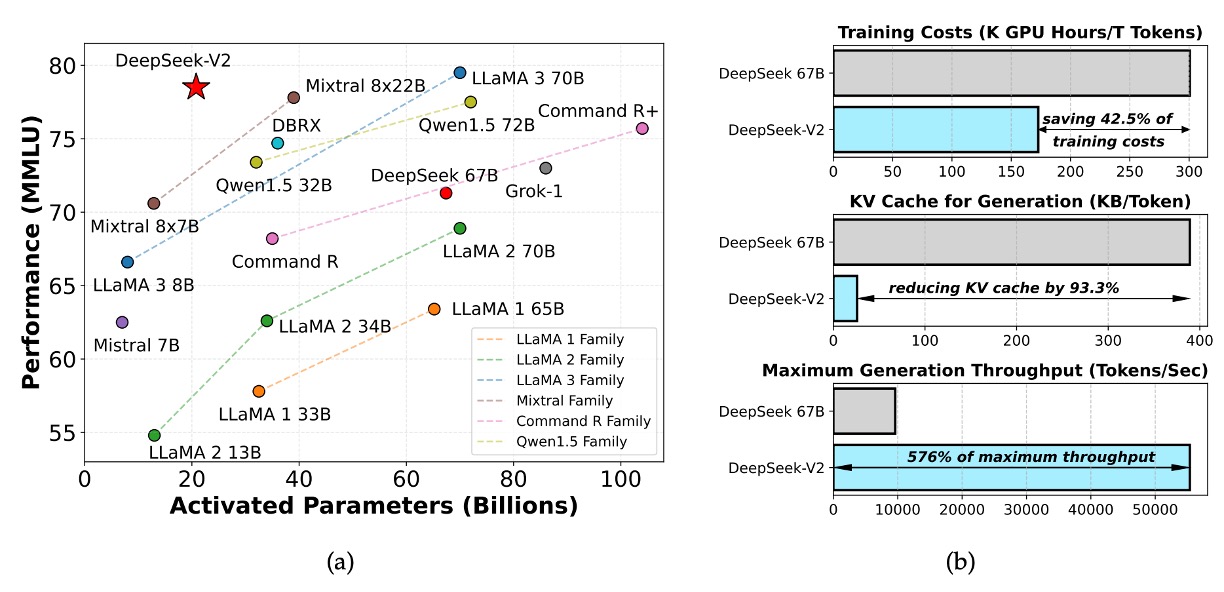
DeepSeek‑V2 是一個基於 MoE 架構的大型語言模型,並能支持長達 128K 的上下文長度。
這個模型利用了兩項創新技術:
- Multi-head Latent Attention: 通過低秩鍵值聯合壓縮,極大地減少了推理時 KV 快取的需求,從而提升了推理效率。
- DeepSeekMoE: 通過細粒度專家分割和共享專家的設計,實現了在較低成本下訓練出強大模型的目標。
與前一版本 DeepSeek LLM 67B 相比,DeepSeek‑V2 在:
- 訓練成本上降低了 42.5%;
- KV 快取減少了 93.3%;
- 生成吞吐量提高了 5.76 倍。
儘管整體參數量達到 236B,但每個 token 僅激活 21B 個參數,這使得模型在經濟性與效能間達到了很好的平衡,並成為目前開源 MoE 模型中表現最強的模型之一。