[21.04] RoFormer

Rotary Position Embedding
RoFormer: Enhanced Transformer with Rotary Position Embedding
Compared to the name RoFormer, RoPE (Rotary Position Embedding) is more widely known. RoPE is the core concept of RoFormer, introducing a new method of positional encoding.
Problem Definition
Unlike RNNs or CNNs, Transformers lack an inductive bias towards position. Thus, we must provide additional positional information so the model can understand the order within a sequence. Typically, positional encoding involves converting positional information into vector form and then "adding" it to the input token embeddings.
Absolute Position: Sinusoidal
In the first Transformer paper, a sinusoidal function was used:
This function considers both the sequence length and feature dimensions, providing a fixed positional encoding for each position. Due to its fixed generation pattern, sinusoidal encoding has some extrapolation ability.
What is the significance of the 10000 in the formula?
The 10000 in the positional encoding formula can be explained as the scale of the encoding. We constrain the scale within a suitable range to effectively capture the relationships between different positions, avoiding adverse effects from excessively high or low frequencies. Changing the 10000 to 100, for example, would increase the frequency of the sine and cosine functions, causing the positional encodings to repeat over shorter distances, potentially impairing the model's ability to sense relationships between distant positions.
Absolute Position: Learned
In models like BERT and GPT, positional encodings are learned. Assuming a maximum sequence length of and a model dimension , the positional encoding matrix is . This design is straightforward and requires no additional thought, but it lacks the ability to generalize to longer sequences and requires retraining if the sequence length changes.
Extrapolation might not be a significant drawback of absolute positional encoding. Readers can refer to Su Jianlin's article:
Relative Position: XL Style
In this paper, the self-attention mechanism's is expanded:
This results in:
Then, is replaced with relative positional vector , and is replaced with learnable vectors and :
Since and are learnable parameters, they can be merged into one, resulting in:
Considering the encoding space of differs from the original , is replaced with :
Finally, the paper does not add positional encoding to the V matrix in QKV. Subsequent research also only adds positional encoding to the QK matrix (the attention matrix).
Relative Position: T5 Style
In T5, the authors decoupled content and positional information, placing all position-related information into :
More Methods
We are not reviewing all positional encoding methods. For more information, refer to Su Jianlin's article:
Solution
Previous research shows that absolute and relative positional encodings have their own advantages and disadvantages. This study aims to propose a method that integrates both absolute and relative positional encoding.
Model Architecture
Language modeling based on Transformers typically uses self-attention mechanisms to utilize the positional information of each token. The authors aim for the dot product to encode positional information only in a relative form:
The ultimate goal is to find an equivalent encoding mechanism to solve the functions and to satisfy the above relation. After a series of derivations (details in the paper), the proposed solution is:
Here, denotes taking the real part, denotes the complex conjugate, and is a non-zero constant.
Euler's Formula and Rotation
The core concept of Euler's formula is rotation. For a complex number , it can be viewed as a point on a plane or a vector . When we multiply the complex number by , it corresponds to rotating the vector counterclockwise by an angle .
Here's an illustrative example:
-
Initial State
y
^
|
| z = x + iy
|
+-----------------> x -
After Rotation
When we multiply the complex number by , it corresponds to rotating the vector counterclockwise by an angle :
y
^
| z' = e^{i\theta}z
| /
| /
| /
| /
| / z = x + iy
| /
| /
|/
+-----------------> x
This is because can be expanded using Euler's formula:
This formula represents a unit vector rotating counterclockwise by an angle in the complex plane.
-
Special Case
When , we get:
This means multiplying the complex number by rotates it by 180 degrees, resulting in a vector in the opposite direction. Thus, we obtain the famous identity:
This identity, known as Euler's identity, is one of the most beautiful formulas in mathematics, elegantly connecting the base of the natural logarithm , the imaginary unit , the circumference ratio , 1, and 0.
In the paper, expressions like appear, where indicates multiple rotations.
The forms and represent two vectors rotating by angles and in the complex plane.
Here, and are parameters representing different frequency components or spatial positions, capturing the behavior of two vectors at different rotation angles.
Here, indicates the difference in rotation angles between the two.
Higher-Dimensional Extension
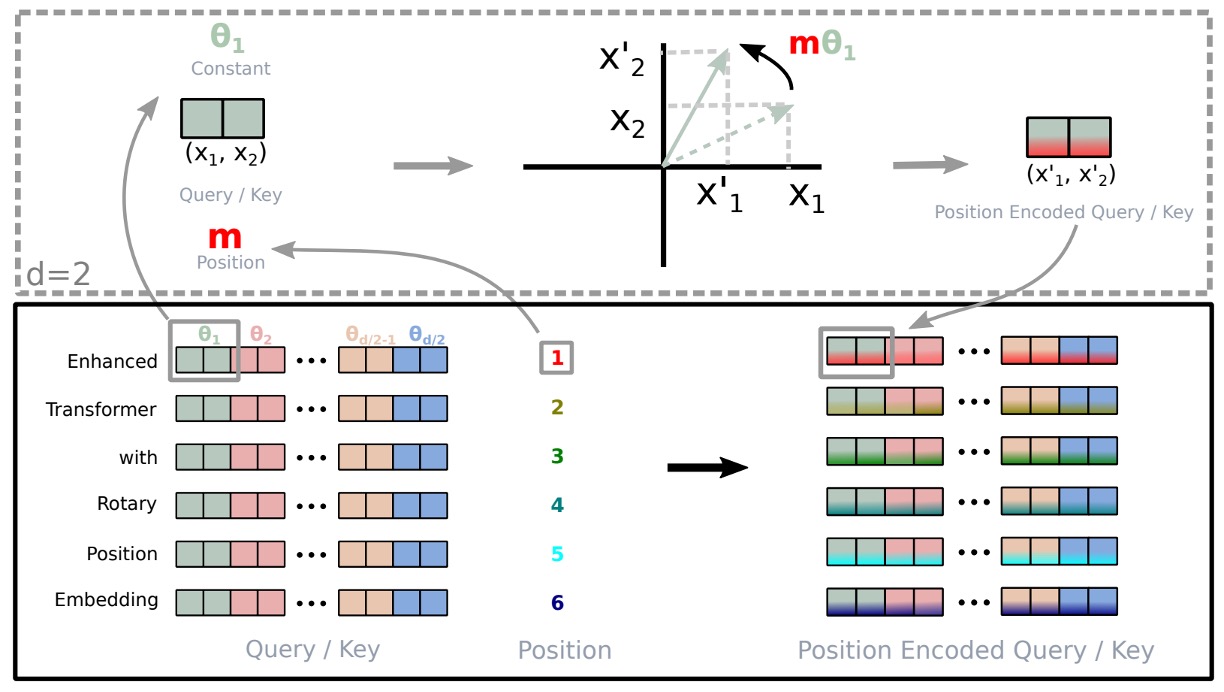
The diagram above illustrates RoPE.
To generalize the results from a 2D space to any where is even, the authors divide the -dimensional space into subspaces, converting into:
where
is the rotation matrix with predetermined parameters .
Applying RoPE to the self-attention mechanism's equation, we get:
where . Note that is an orthogonal matrix, ensuring stability in the encoding process.
Long-Range Decay
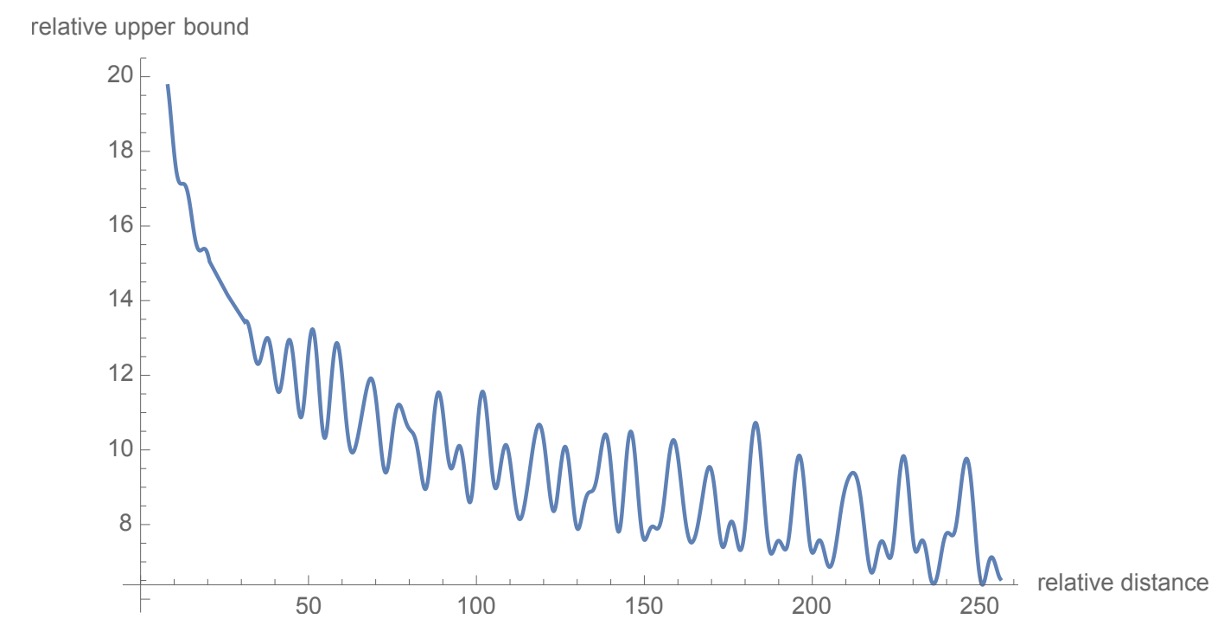
The authors follow the original Transformer's design, setting to provide a long-range decay characteristic, as shown above. This means that as the distance between two positions increases, the dot product of their positional encodings decreases, reflecting the weaker relationships expected between distant positions in a text.
Discussion
Comparison with Other Positional Encodings
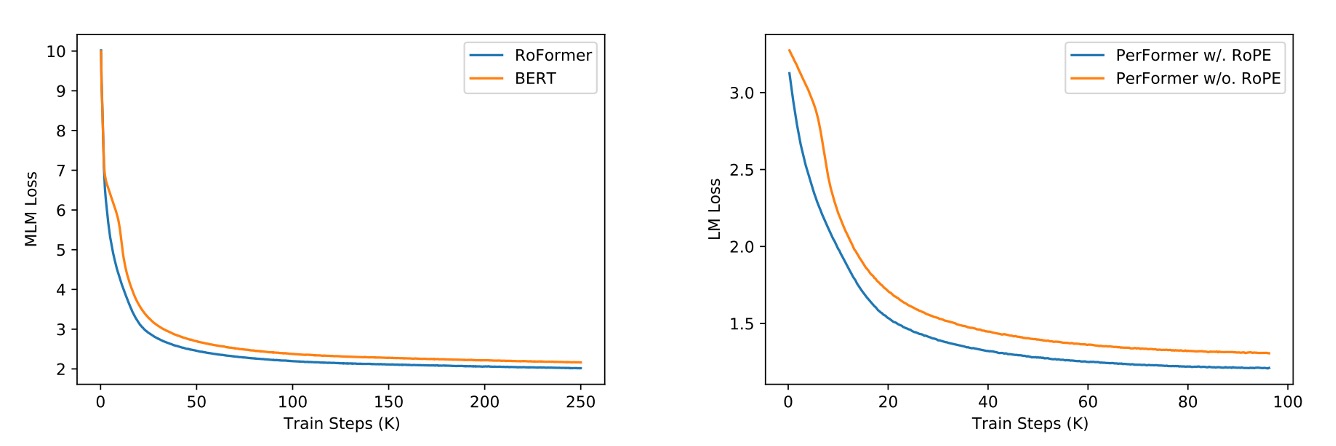
The above image compares RoPE with other positional encoding methods. On the left, compared with BERT, the model using RoPE shows better performance during training, with a faster decrease in MLM Loss. On the right, adding RoPE to PerFormer shows faster convergence and better performance at the end of training.
GLUE Benchmark

The authors fine-tuned their model using Hugging Face's Transformers library and experimented on the GLUE dataset. The results indicate that RoFormer generally outperforms BERT on the GLUE dataset, demonstrating the effectiveness of RoPE in natural language processing tasks.
Limitations
Despite strong theoretical support and encouraging experimental results, the authors acknowledge some limitations:
- The mathematical representation of relative positional relationships as rotations in 2D subspaces lacks a deep explanation for why this method results in faster convergence than baseline models with other positional encoding strategies.
- While the model exhibits beneficial long-term decay characteristics similar to existing positional encoding mechanisms and outperforms other models in long text processing, a compelling explanation for this advantage remains elusive.
Conclusion
This paper might be challenging to read, but the concept of RoPE is fascinating. We highly recommend reading the original paper. Many works (e.g., LLaMA, Mamba) have already adopted RoPE, indicating its promising applications in the field of natural language processing. Subsequent work has explored and improved upon RoPE, and we will discuss these developments as we encounter them.