[22.02] DBNet++

自適應特徵融合
Real-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion
在撰寫 DBNet 系列的筆記時,我們一直在想 DBNet 的名字到底是 DB 還是 DBNet?
在第一版本的論文中,完全沒有提到 DBNet 這個名字,因此在其他文獻的引用中,全部都稱之為 DB。後來在這篇論文中,終於看到作者對於自己模型的稱呼叫做 DBNet,因此我們尊重作者的命名,將這個系列的論文稱之為 DBNet。
定義問題
延續上一篇論文 DBNet,作者覺得模型還有進步的空間,於是在原有的架構上,優化了特徵融合的方式,提出了 DBNet++。
如果你沒看過上一篇論文,我們建議你回去看一下,因為這裡我們會省略多數重複的細節。
解決問題
模型架構
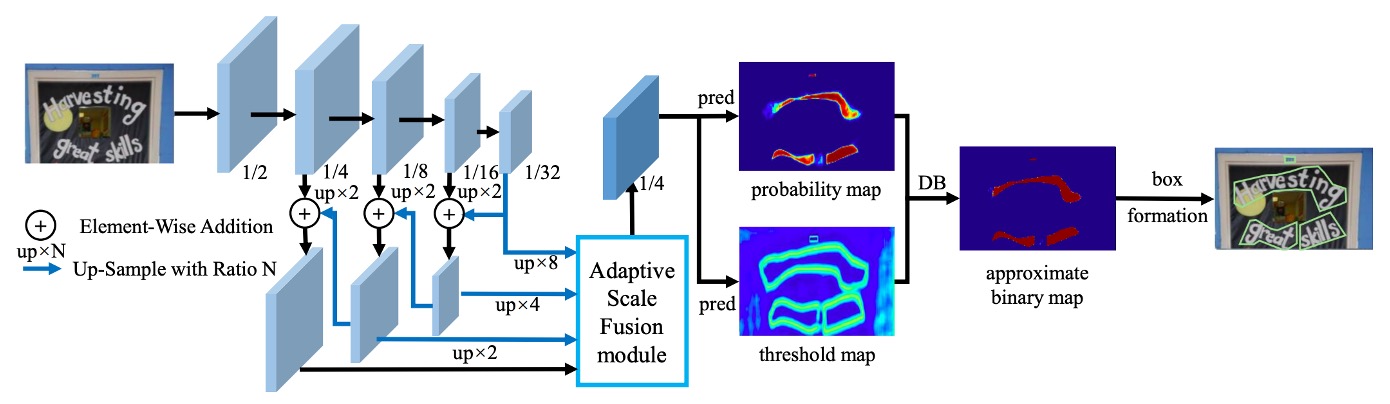
首先是跟第一版論文幾乎一樣的架構,我們直接略過。
請直接看到這次改動的地方,也就是上圖中:Adaptive Scale Fusion Module 的部分。
自適應尺度融合
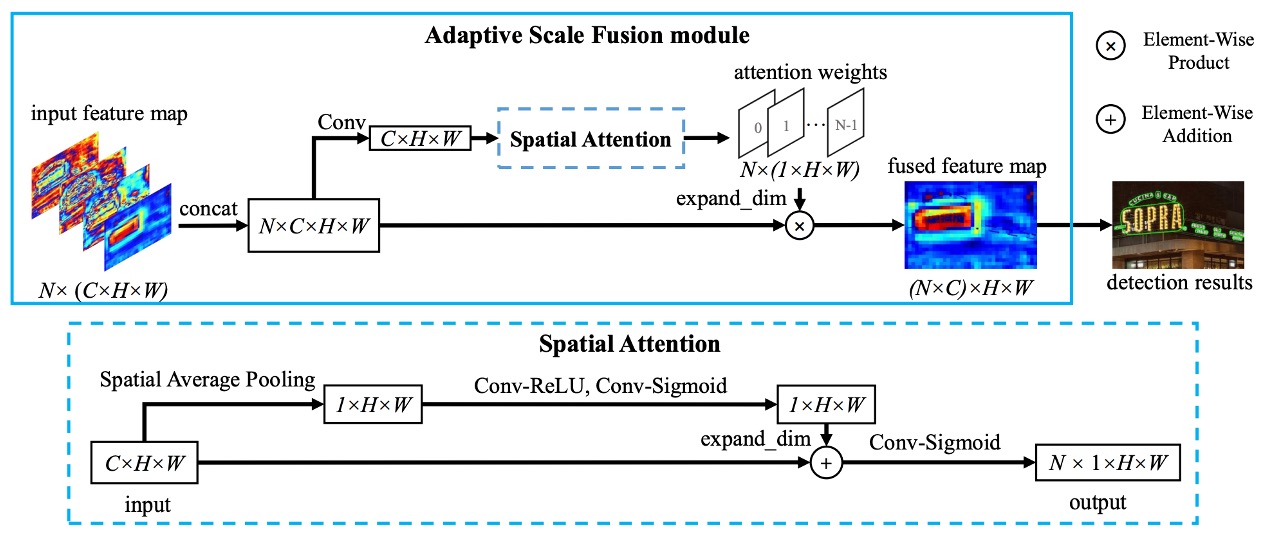
自適應尺度融合,論文中稱為 Adaptive Scale Fusion(ASF),是作者在 DBNet 的基礎上提出的一個新模組。
在原本的設計中,只是單純地把不同尺度的特徵圖拼接再一起,然後送入卷積層進行特徵融合,就直接接後面的預測分支。
而作者認為這裡顯然可以做得更細緻,因為不同尺度的特徵可能有不同的重要性,因此在融合階段,應該計算出圖片中每個位置的重要性,然後根據這個重要性來決定不同尺度特徵的融合程度。
如上圖,我們跟著作者的思路一起走一次:
- 輸入特徵圖,尺寸:
C x H x W - 以下開始進入
Spatial Attention的部分:- 進行空間平均池化,得到
1 x H x W的特徵圖,意思是對每個通道進行平均,得到每個位置的重要性 - 經過一個卷積層和
Sigmoid,增加1 x H x W特徵圖的非線性表達能力,拓展回C個通道,尺寸為C x H x W - 將這個特徵圖「加上」原本的特徵圖,得到加權後的特徵圖,再次經過
Conv和Sigmiod,轉成0~1之間的值,並壓縮通道數,輸出尺寸為1 x H x W
- 進行空間平均池化,得到
- 回到
Adaptive Scale Fusion的部分:- 將上一步驟的輸出拓展通道數,尺寸為
C x H x W - 進行加權融合,將這些特徵圖「乘上」剛剛的加權特徵圖,得到最終的融合特徵圖
- 將上一步驟的輸出拓展通道數,尺寸為
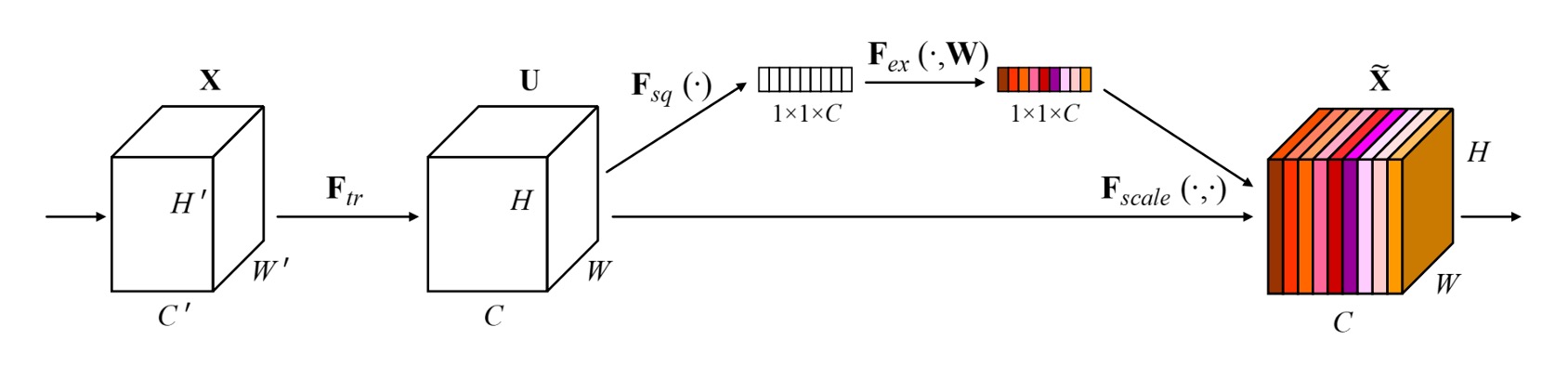
這個概念非常像我們之前看過的 SENet,差別在於 SENet 是對通道進行加權,而這裡是對空間進行加權。
討論
和原始 DBNet 的比較
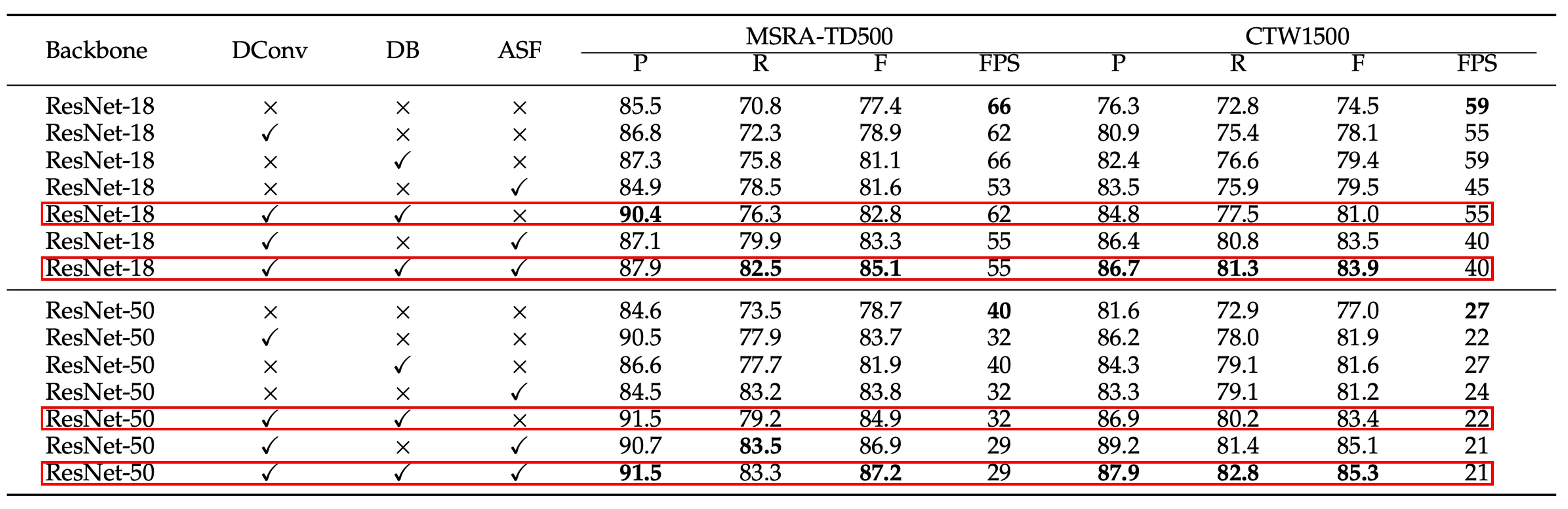
作者在 MSRA-TD500 和 CTW1500 數據集上進行了消融實驗,這些模組包括可微分二值化(Differentiable Binarization, DB)、可變形卷積(Deformable Convolution)和自適應尺度融合(Adaptive Scale Fusion)。
我們挑重點看,紅色框起來的部分,就是增加了 ASF 模組後的效果。
其實增加這個模組之後 Precision 和 Recall 大多有所提升,但大多是 Recall 提升更多。意思是這個模組會有更多誤報,但是可以找到更多正確的文字區域。
整體而言,F-measure 有所提升,在 MSRA-TD500 數據集和 CTW1500 數據集上分別提高了 2.3% 和 1.9%,這樣的結果證明了 ASF 模組的有效性。
可視化

結論
這篇論文中大部分的內容都和先前的 DBNet 一樣,我們就不再鉅細靡遺地介紹了。
自適應尺度融合模組讓模型能夠基於輸入,自動調整不同尺度特徵的融合程度,這樣的設計在實驗中證明了有效性。雖然在推論中會降低一點推論速度,但是整體而言,提升了大約 2% 的模型的性能。
算起來,也是個很不錯的投資!