[14.11] FCN

全卷積網路
Fully Convolutional Networks for Semantic Segmentation
這麼經典的論文,我們怎麼能不讀呢?
定義問題
影像分割的問題已經發展了好些年了。
隨著卷積網路的崛起,愈來愈多的應用轉向使用卷積網路來解決影像分割的問題。過去的方法通常把整個系統拆分成幾個部分,整個過程不連貫,而且需要大量的人工設計。
作者在這個時候提出了全卷積網路的概念,這個概念讓我們可以直接將卷積網路應用在影像分割的問題上,而不需要再經過其他的處理。
解決問題
模型架構
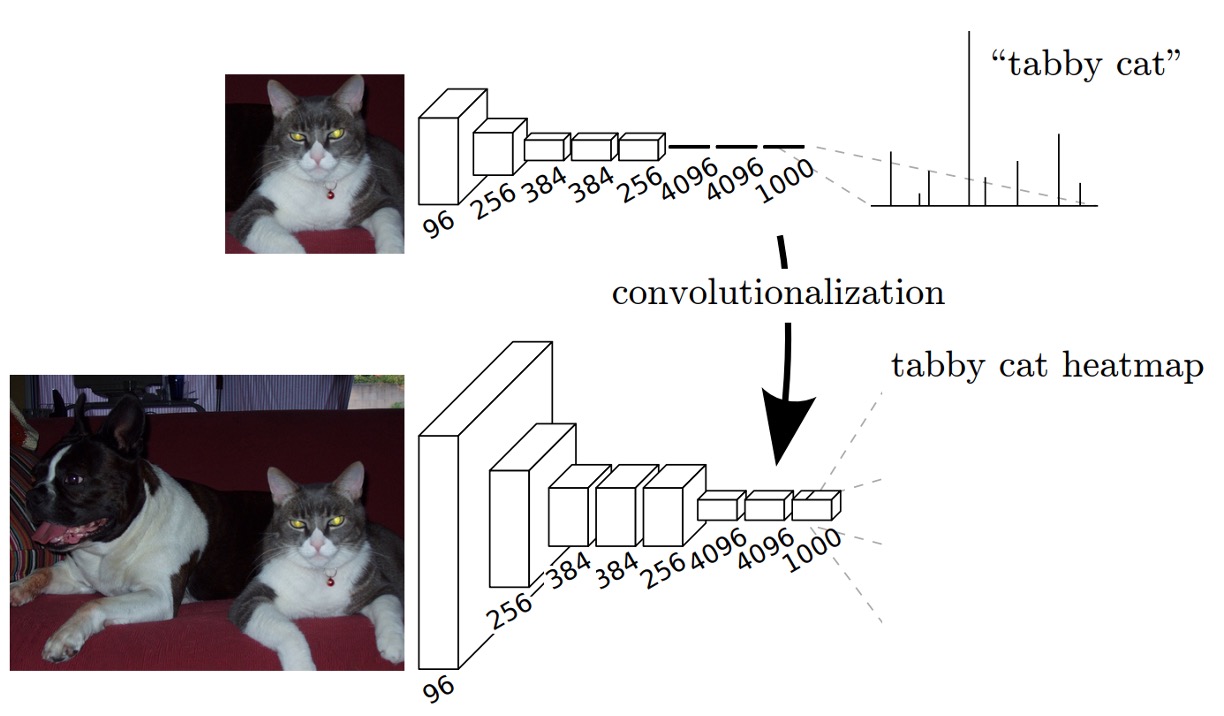
目前的幾個主流架構分別是:AlenNet、VGG16、GoogLeNet,而他們都應用在分類問題上。
為了把這些架構應用在影像分割的問題上,作者針對這些架構最後的「全連接層」的部分進行修改,將這些全連接層改成卷積層,如上圖所示。
在原本使用「全連接層」的時候,輸入影像尺寸會受到限制,因為儘管卷積層可以處理任意尺寸的影像,但是全連接層卻不能。所以作者將全連接層改成卷積層,這樣我們就可以直接將任意尺寸的影像輸入到網路中,而不需要再經過其他的處理。
處理方式很簡單:例如原本的全連接層的尺寸是 ,我們可以將這個全連接層改成 的卷積層。如果覺得 的尺寸太小,作者在論文中所使用的是 的卷積核。
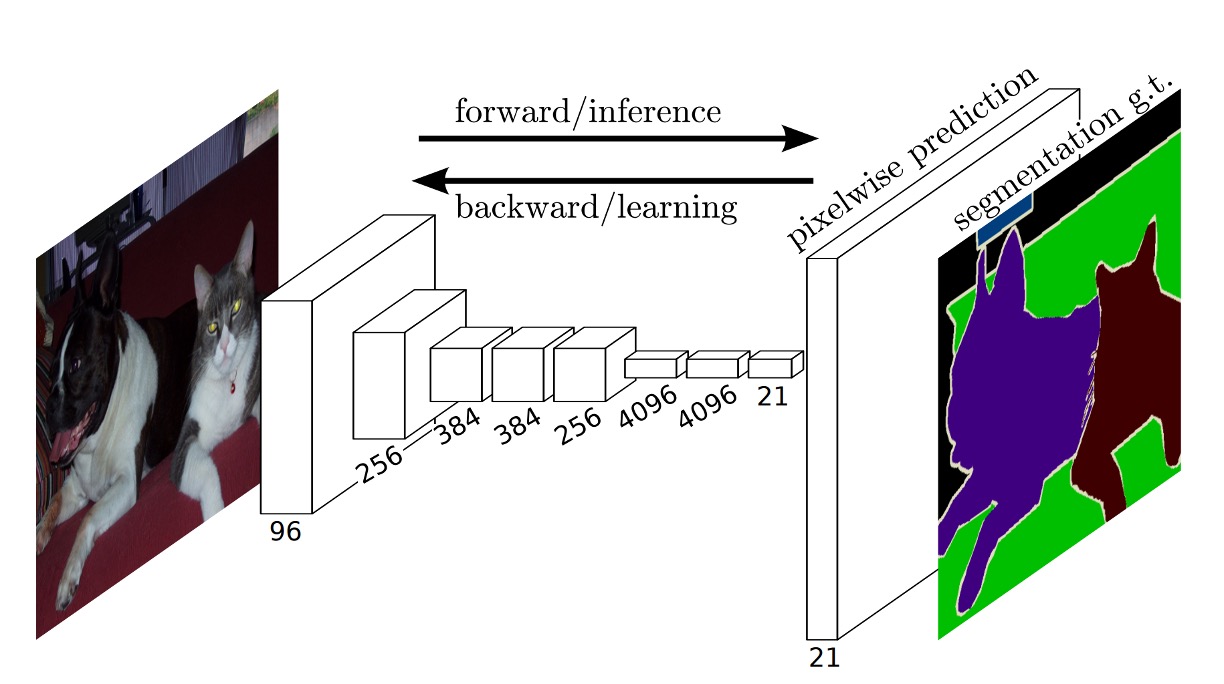
得到輸出後,為了匹配原圖的尺寸,作者使用上採樣的方式來將輸出的尺寸放大到原圖的尺寸。在放大過程中,同步調整輸出通道數。
在這篇論文中,最後的輸出通道數量是 ,這是因為作者使用的是 PASCAL VOC 2011 的資料集,這個資料集有 類加上背景,所以總共有 類。
上採樣
在論文中,作者提到 Shift-and-stitch 是一種不使用插值就能從粗糙的輸出中獲得密集預測的技巧,這個技巧最早由 OverFeat 引入。
當輸出被降採樣了 倍,則輸入會向右平移 像素、向下平移 像素,並對每一組 的值進行處理。這些 組輸入經由卷積網路運算後,將輸出交錯排放,使得預測結果對應到其接收域中心的像素位置。
雖然作者進行了 Shift-and-stitch 的初步實驗,但最終選擇了使用「反卷積」的上採樣的學習方式,因為這樣的方式更有效率,特別是結合後面會提到的 skip layer 融合技術時效果更佳。
完整的網路架構如下圖:
多尺度融合
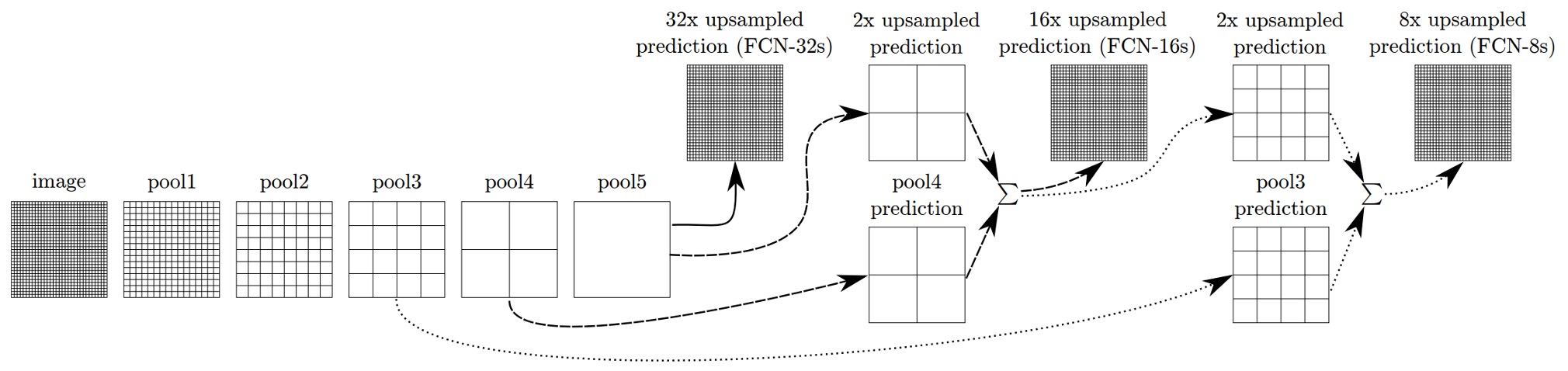
如果只是單純的使用最深層,最低解析度的特徵,那放大回原圖尺寸的結果會很粗糙。為了解決這個問題,作者提出了多尺度融合的方法。
如上圖,作者將不同解析度的特徵圖取出來,最小的特徵圖是 ,最大的特徵圖是 ,融合過程是將 的特徵圖放大到 ,然後和 的特徵圖相加,再將結果放大到 ,和 的特徵圖相加,最後再放大到原圖的尺寸。
這個技巧被作者稱為「skip layer」,透過這樣的方式,模型可以得到更好的結果,如下圖所示:
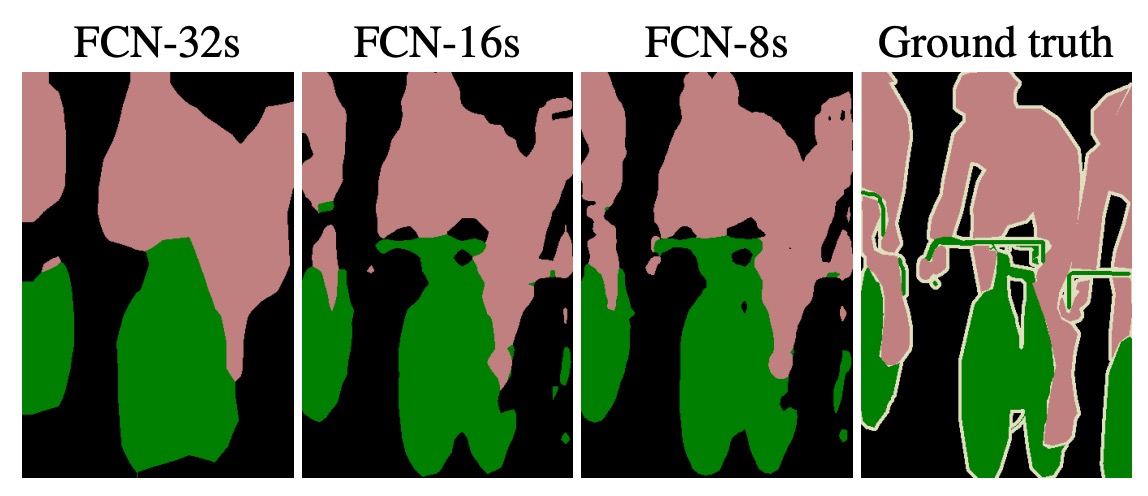
最左邊的是直接從 的特徵圖放大到原圖的結果,中間的是使用多尺度融合的結果。分別是 和 的特徵圖和原圖相加,可以看到中間的結果更加平滑和具有細節資訊。
嘿!這不就是 FPN 嗎!果然是領先時代的論文!
訓練資料集與策略
作者使用 PASCAL VOC 2011 分割挑戰來進行訓練和驗證,並以每像素多項式邏輯損失進行訓練,使用平均交並比(mean IoU)作為標準評估指標。所有模型皆使用 Caffe 框架在單一 NVIDIA Tesla K40c 上進行訓練與測試。
-
學習率:模型使用帶有動量的隨機梯度下降(SGD)進行訓練,動量設為 0.9,權重衰減設為 或 。學習率固定為 、 和 (分別對應 FCN-AlexNet、FCN-VGG16 和 FCN-GoogLeNet),這些值是通過線性搜索確定的。隨機初始化分類卷積層的參數並使用 dropout(如原分類網路中一樣),但發現隨機初始化對性能和收斂速度沒有幫助。
-
訓練數據:將每張圖像切分成規則的重疊區塊,與隨機取樣方式相比,發現取樣對收斂速度的影響不顯著,但全圖像訓練在時間上更有效率,因此選擇全圖像訓練。
-
類別平衡:在全卷積訓練中可以透過加權或取樣平衡類別,儘管標籤稍有不平衡(約 3/4 為背景),但結果顯示不需要進行類別平衡。
-
密集預測:輸出經由網路中的反卷積層進行上採樣,最終層的反卷積濾波器固定為雙線性插值,中間層的上採樣初始化為雙線性插值,隨後進行學習。沒有使用 shift-and-stitch 技巧或濾波器稀疏化的等價方法。
-
數據增強:嘗試隨機翻轉和平移圖像(最多 32 像素)的數據增強,但未發現顯著提升。
-
額外訓練數據:使用 PASCAL VOC 2011 訓練集的 1112 張圖片進行初步訓練,後來增加了 Hariharan 等人標註的 8498 張 PASCAL 圖像數據,將 FCN-VGG16 的驗證分數提升了 3.4 個點,達到 59.4 的平均 IoU。
評估指標
論文中報告了四個來自語義分割和場景解析的常見評估指標,這些指標是像素準確度和區域交並比(IoU)的變化形式。
計算公式如下:
-
像素準確度(Pixel Accuracy):
表示第 類中模型預測正確的像素數量(即,實際是類別 且預測為類別 的像素數量), 表示圖像中所有像素的總數。
像素準確度是最基本的評估指標,它直接反映模型在整張圖片中預測正確的像素比例。然而,當數據集中某些類別(如背景)佔較多像素時,這個指標可能會掩蓋小物體的預測錯誤。
-
平均準確度(Mean Accuracy):
表示實際為第 類的總像素數, 是模型正確預測為第 類的像素數。
平均準確度考慮了每個類別的預測表現,並對所有類別的準確度取均值。這樣的好處是,即使某些類別像素數很少,也能對它們的預測表現進行公平的評估。這個指標對類別不均衡問題的影響較小,更能反映模型在每個類別上的一致性表現。
-
平均交並比(Mean IoU):
分子部分 是預測正確的像素數,分母部分 則是該類別的預測與實際結果的聯合集(包含了正確預測的像素數以及預測錯誤的像素數)。
平均交並比是一個衡量分類預測效果的指標,它考慮了每個類別的預測正確與錯誤的程度。這個指標通過計算每個類別的交並比,並取所有類別的平均值來反映模型的整體表現。相比像素準確度,Mean IoU 更能平衡類別間的不均衡情況,對於小物體和大物體的預測都有一定的區分度。
-
加權交並比(Frequency Weighted IoU):
加權交並比考慮了類別的出現頻率,用每個類別的總像素數 作為權重,對每個類別的交並比進行加權平均。這個公式的分母 是所有像素的總數,而每一項 表示該類別的正確預測數量乘以其像素總數,這樣就可以強調那些像素佔比較大的類別(如背景)。
加權交並比在評估語義分割時,不僅考慮了每個類別的預測準確性,還加權了每個類別在整個數據集中所佔的比例。這對於處理類別不均衡的問題有幫助,因為它會讓佔有較多像素的類別(如背景)對最終結果有更大的影響。這個指標在處理實際應用場景時,對於常見類別的表現更為敏感。
討論
PASCAL VOC 結果

上表展示了 FCN-8s 在 PASCAL VOC 2011 和 2012 測試集上的表現,並與之前的最佳系統 SDS 和著名的 R-CNN 進行比較。
在平均交並比上,我們的結果比之前的最佳結果提高了 20%。推論時間也顯著縮短,僅計算卷積網路部分的速度快了 114 倍,總體上推論時間快了 286 倍。
NYUDv2 結果
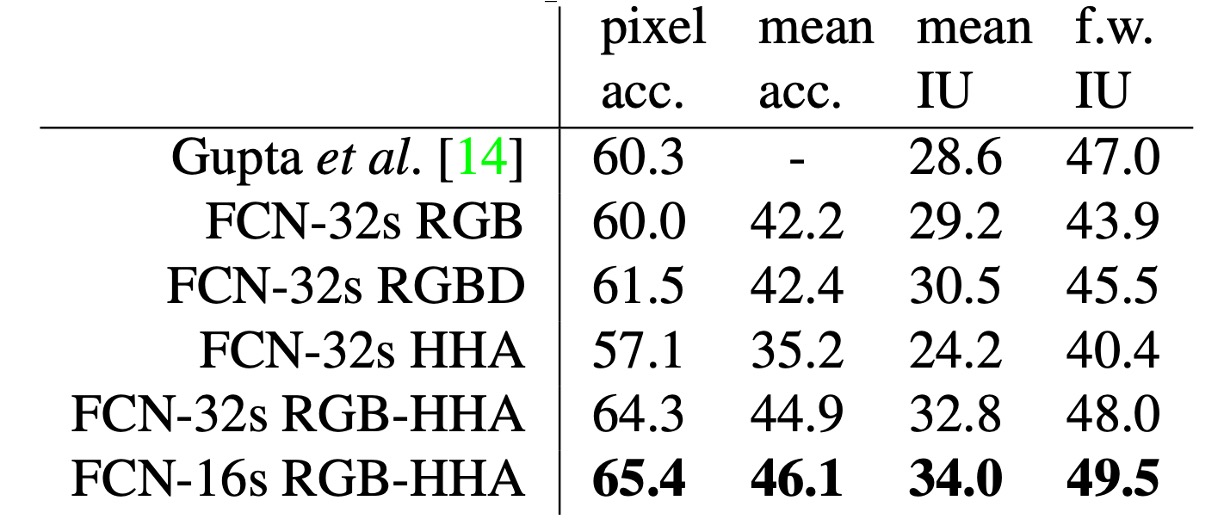
作者一開始使用 RGB 圖像訓練未修改的粗糙模型(FCN-32s),接著加入深度資訊,將模型升級為處理四通道的 RGB-D 輸入(early fusion),但改進效果有限。
根據 Gupta 等人的研究,作者使用 HHA 深度編碼,進行 RGB 和 HHA 的「晚期融合」(late fusion),最終升級為 16 步長版本。
NYUDv2 資料集包含 1449 張 RGB-D 圖像,每張圖像都有逐像素標記,已被合併成 40 個類別的語義分割任務。
SIFT Flow 結果
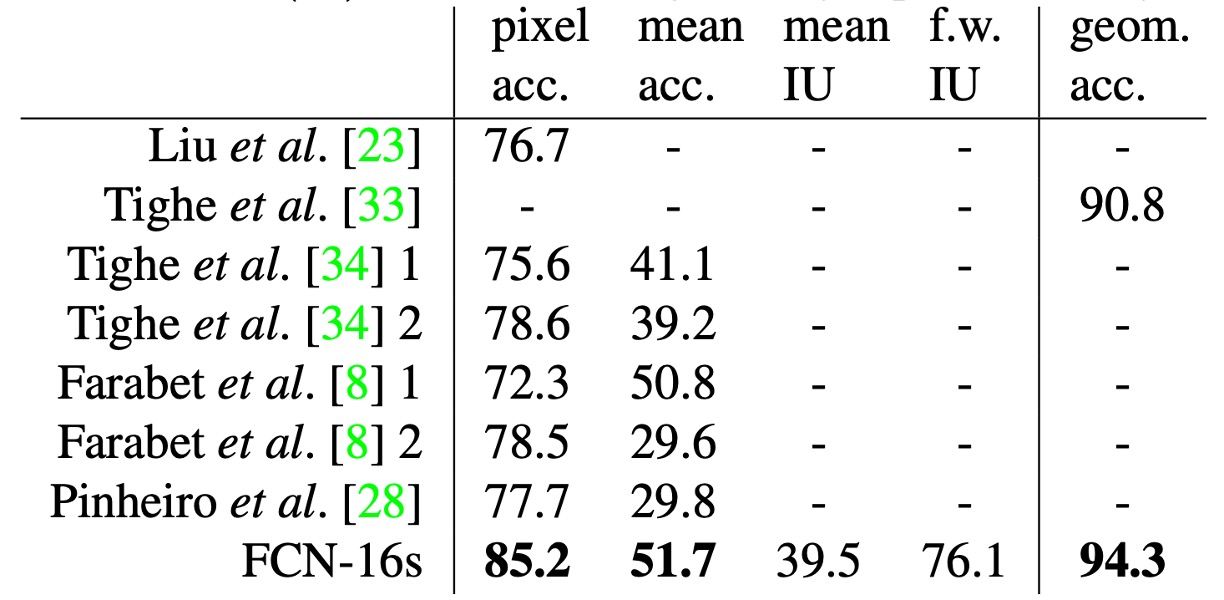
作者訓練了一個雙頭的 FCN-16s 模型,同時預測語義和幾何標籤。該模型在兩個任務上的表現與分別訓練的模型相當,但學習和推論速度幾乎與單個模型一樣快。
上表展示了標準數據分割上的結果(2488 張訓練圖像和 200 張測試圖像),顯示在這兩個任務上均達到了最新的最佳表現。
SIFT Flow 資料集包含 2,688 張帶有 33 個語義類別(如「橋」、「山」、「太陽」)的圖像,以及三個幾何類別(「水平」、「垂直」、「天空」)。
結論
FCN 的提出是一項里程碑式的貢獻,它將卷積網路的優勢充分擴展到語義分割任務,為後續許多影像分割技術奠定了基礎。其跳連結技術以及全卷積架構創新,使得語義分割成為可行的端到端任務。
儘管 FCN 在輸出精度、資源消耗以及多尺度特徵融合方面仍有改進空間,但其提出的思路和技術對於後續的影像分割研究有著重要的指導意義。