[16.03] RARE

Automatic Rectification
Robust Scene Text Recognition with Automatic Rectification
After the introduction of CRNN, many issues were resolved, but it still struggled with recognizing irregular text.
Defining the Problem
Recognizing text in natural scenes is much harder than recognizing printed text. During recognition, text can often appear distorted, warped, occluded, or blurred.
In this paper, the authors focus on addressing the problems of deformation and distortion. Remember that famous STN model from a while back?
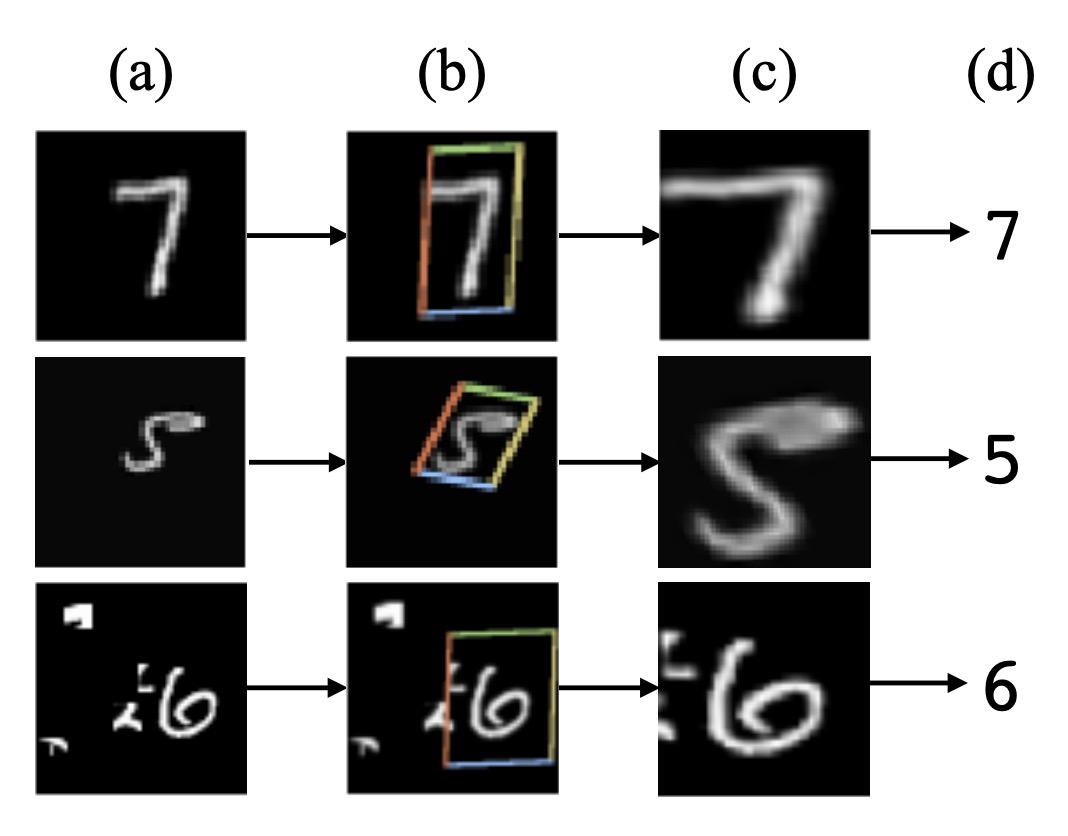
Maybe we could design a model with automatic rectification functionality?
Solving the Problem
Spatial Transformer Network
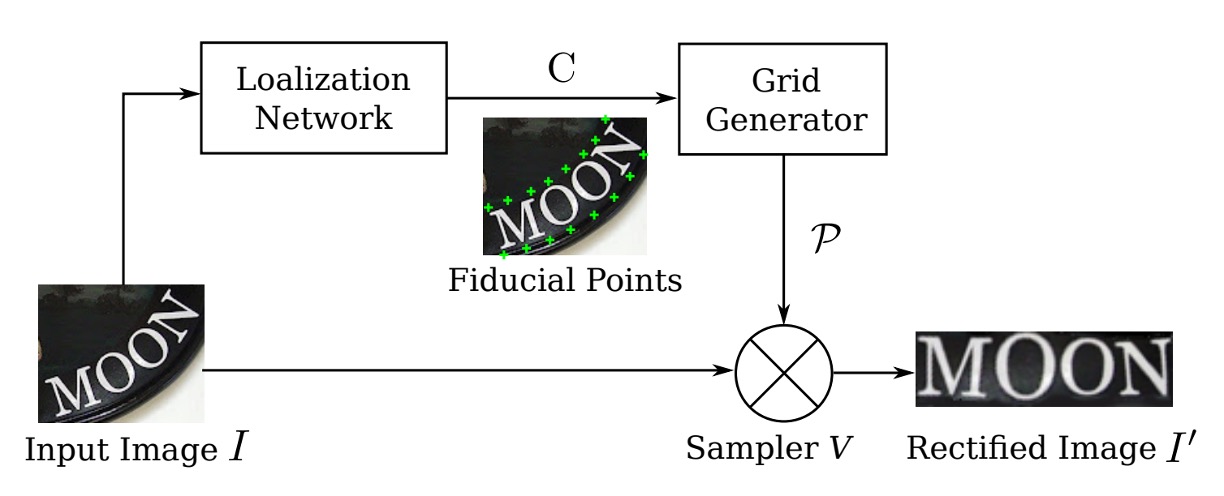
To alleviate the issue of recognizing irregular text, the automatic rectification functionality should be placed before the recognition module.
Here, the authors introduce a Spatial Transformer Network (STN) to rectify the input image.
The primary goal of the STN is to transform the input image into a rectified image using a predicted Thin Plate Spline (TPS) transformation. This network predicts a set of control points through a localization network, calculates TPS transformation parameters from these points, and generates a sampling grid that is used to produce the rectified image from the input image.
Localization Network
The localization network is responsible for locating control points. Its output is the coordinates of these control points in and , denoted as:
The coordinate system’s center is set at the center of the image, and the coordinate values range from .
The network uses a convolutional neural network to regress the control points’ positions. The output layer consists of nodes, using the tanh activation function to ensure the output values fall within the range.
The network is fully supervised by backpropagated gradients from the other parts of the STN, so no manual labeling of control point coordinates is required.
Grid Generator
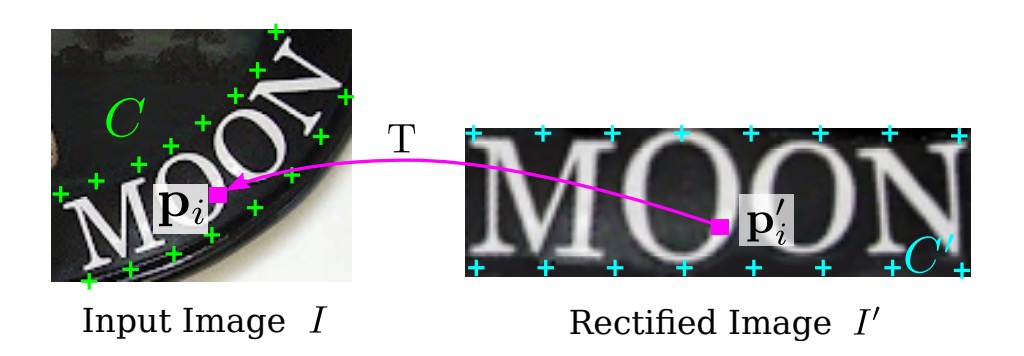
The authors define a set of "base" control points (as shown in the above image), which are then adjusted by the control points predicted by the localization network to obtain new control points .
The grid generator estimates the TPS transformation parameters and produces the sampling grid. The TPS transformation parameters are represented by a matrix , calculated as:
Here, is a matrix determined by the control points , thus being a constant matrix.
The specific form of is:
Where the element in the matrix is defined as:
Here, represents the Euclidean distance between the and control points and .
The pixel grid on the rectified image is denoted as , where is the and coordinates of the pixel, and is the number of pixels in the image.
For each pixel in , its corresponding pixel in the input image is determined by the following transformation:
-
First, calculate the distance between and the control points:
Where is the Euclidean distance between and the control point .
-
Next, construct the augmented vector :
-
Finally, use the matrix operation below to map it to the point on the input image:
By applying the above steps to all the pixels in the rectified image , a pixel grid on the input image is generated.
Since the matrix calculation and the transformation of points are differentiable, the grid generator can backpropagate gradients for model training.
If you find the above explanation too technical, let’s simplify it:
Imagine we have a distorted image (perhaps due to the camera angle or other factors). We want to "flatten" or "correct" it, making its content orderly so that recognition becomes easier.
First, we select some "control points" on the image. These points can be important reference locations in the image, like corners or edges. We then calculate the relationships between these control points, using Euclidean distances. Based on these distances, we can determine how each pixel in the image should move or adjust to make the image flat.
The "flattening" process doesn’t move each pixel randomly but follows a set of rules and calculations to ensure the rectified image remains consistent and natural.
That’s what the matrix and those distance formulas are doing.
Sampler
The sampler uses bilinear interpolation to generate the rectified image from the input image based on pixel values.
For each pixel in the rectified image , its value is calculated through bilinear interpolation of the nearby pixels in the input image .
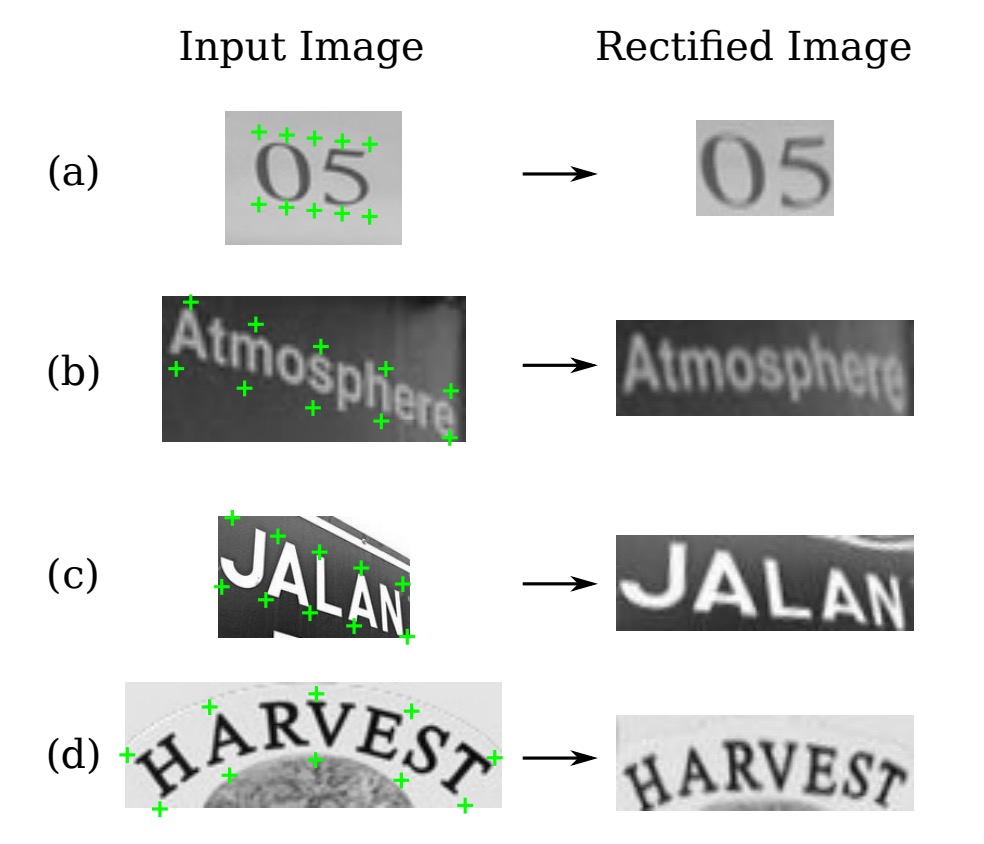
This process is also differentiable, allowing the entire model to backpropagate errors. The sampled result looks like the following image:
Encoder-Decoder
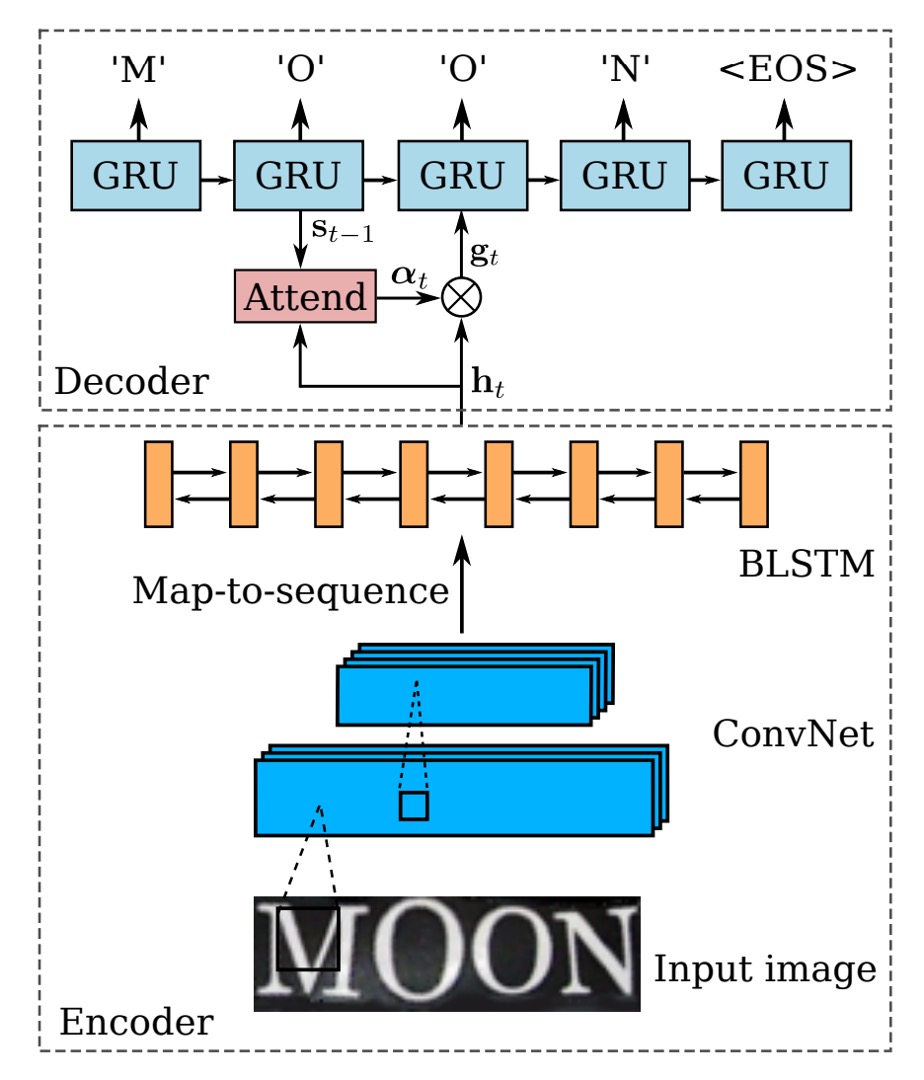
After completing the automatic correction of the image, we return to the familiar recognition process.
First, we have the encoder, where a CRNN model is used. This model uses a backbone network to convert the input image into a sequence of features, which are then fed into a BiLSTM network for sequence modeling.
Next comes the decoder. In the original CRNN model, the CTC algorithm was used for text decoding, but in this paper, the authors opted for a simpler method: using a GRU (Gated Recurrent Unit) for decoding.
GRU and LSTM are similar architectures, but GRU has fewer parameters, which leads to faster training times.
For the decoding part, the authors integrated an attention mechanism. At each time step , the decoder calculates an attention weight vector , where is the length of the input sequence.
The formula for calculating the attention weights is as follows:
Where:
- is the hidden state of the GRU unit from the previous time step.
- is the attention weight vector from the previous time step.
- is the encoder’s representation of the input sequence.
The Attend function calculates the current attention weight vector based on the previous hidden state and the previous attention weights . Each element of this vector is non-negative, and the sum of all elements equals 1, representing the importance of each element in the input sequence for the current decoding step.
Once is computed, the model generates a vector called the glimpse vector , which is the weighted sum of the encoded representation of the input sequence.
The formula for the glimpse vector is:
Where:
- is the -th element of the attention weight vector .
- is the encoded representation of the -th element of the input sequence.
The glimpse vector represents the weighted sum of the parts of the input sequence that the model is currently focusing on.
Since is a probability distribution (with all elements being non-negative and summing to 1), the glimpse vector is a weighted combination of the input sequence’s features. This allows the decoder to focus on different parts of the input sequence depending on the current decoding step.
After computing the glimpse vector , the decoder uses the GRU’s recursive formula to update the hidden state :
Where:
- is the label from the previous time step.
- During training, this is the actual label.
- During testing, this is the predicted label from the previous time step .
- is the glimpse vector calculated using the attention mechanism, representing the part of the input the model is focusing on.
- is the hidden state of the GRU from the previous time step.
The GRU unit updates the current hidden state based on the previous label , the current glimpse vector , and the previous hidden state , encoding the relationship between the current step’s output and the input information.
At each time step, the decoder predicts the next output character based on the updated hidden state . The output is a probability distribution over all possible characters, including a special "End of Sequence" (EOS) symbol. Once the model predicts EOS, the sequence generation process is complete.
Dictionary-Assisted Recognition
The final output might still contain some errors. The authors use a dictionary to aid recognition. They compare the results with and without the dictionary.
When testing images with an associated dictionary, the model selects the word with the highest conditional posterior probability:
When the dictionary is very large (e.g., a Hunspell dictionary containing over 50k words), checking each word’s probability can be computationally expensive. Therefore, the authors adopt a prefix tree for efficient approximate search, as shown below:
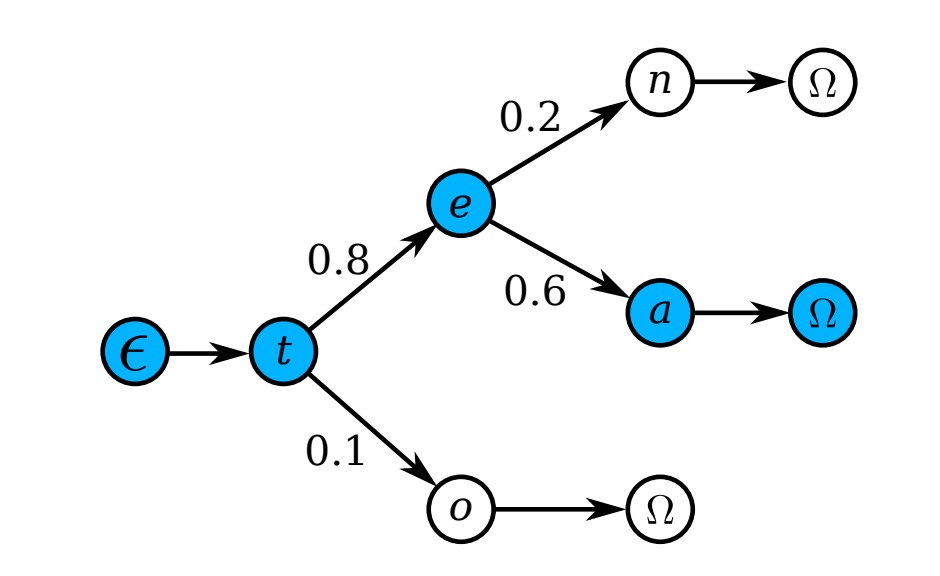
Each node represents a character, and the path from the root to the leaf represents a word.
During testing, starting from the root node, the highest posterior probability sub-node is selected at each step based on the model’s output distribution, continuing until reaching a leaf node. The corresponding path is the predicted word.
Since the tree's depth is the length of the longest word in the dictionary, this method is much more efficient than searching each word individually.
Model Training
The authors used a synthetic dataset released by Jaderberg et al. as training data for scene text recognition:
- Text Recognition Data: This dataset contains 8 million training images with corresponding annotated text. These images are generated by a synthetic engine and are highly realistic.
No additional data was used.
The batch size during training was set to 64, and the image size was adjusted to during both training and testing. The STN's output size was also . The model processes approximately 160 samples per second and converged after 3 epochs, which took about 2 days.
Evaluation Metrics
The authors evaluated the model's performance using four common scene text recognition benchmark datasets:
-
ICDAR 2003 (IC03)
- The test set contains 251 scene images with labeled text bounding boxes.
- For fair comparison with previous works, text images containing non-alphanumeric characters or less than three characters are usually ignored. After filtering, 860 cropped text images remain for testing.
- Each test image is accompanied by a 50-word lexicon (dictionary). Additionally, a full lexicon is provided, which merges the lexicons of all images for evaluation.
-
ICDAR 2013 (IC13)
- The test set inherits and corrects part of the IC03 data, resulting in 1,015 cropped text images with accurate annotations.
- Unlike IC03, IC13 does not provide a lexicon, so evaluations are done without dictionary assistance (i.e., in a no-dictionary setting).
-
IIIT 5K-Word (IIIT5k)
- The test set contains 3,000 cropped text images collected from the web, covering a wider range of fonts and languages.
- Each image comes with two lexicons: a small dictionary containing 50 words and a large dictionary containing 1,000 words for dictionary-assisted evaluation.
-
Street View Text (SVT)
- The test set comprises 249 scene images from Google Street View, cropped into 647 text images.
- Each text image is accompanied by a 50-word lexicon for dictionary-assisted evaluation.
Discussion
Comparison with Other Methods
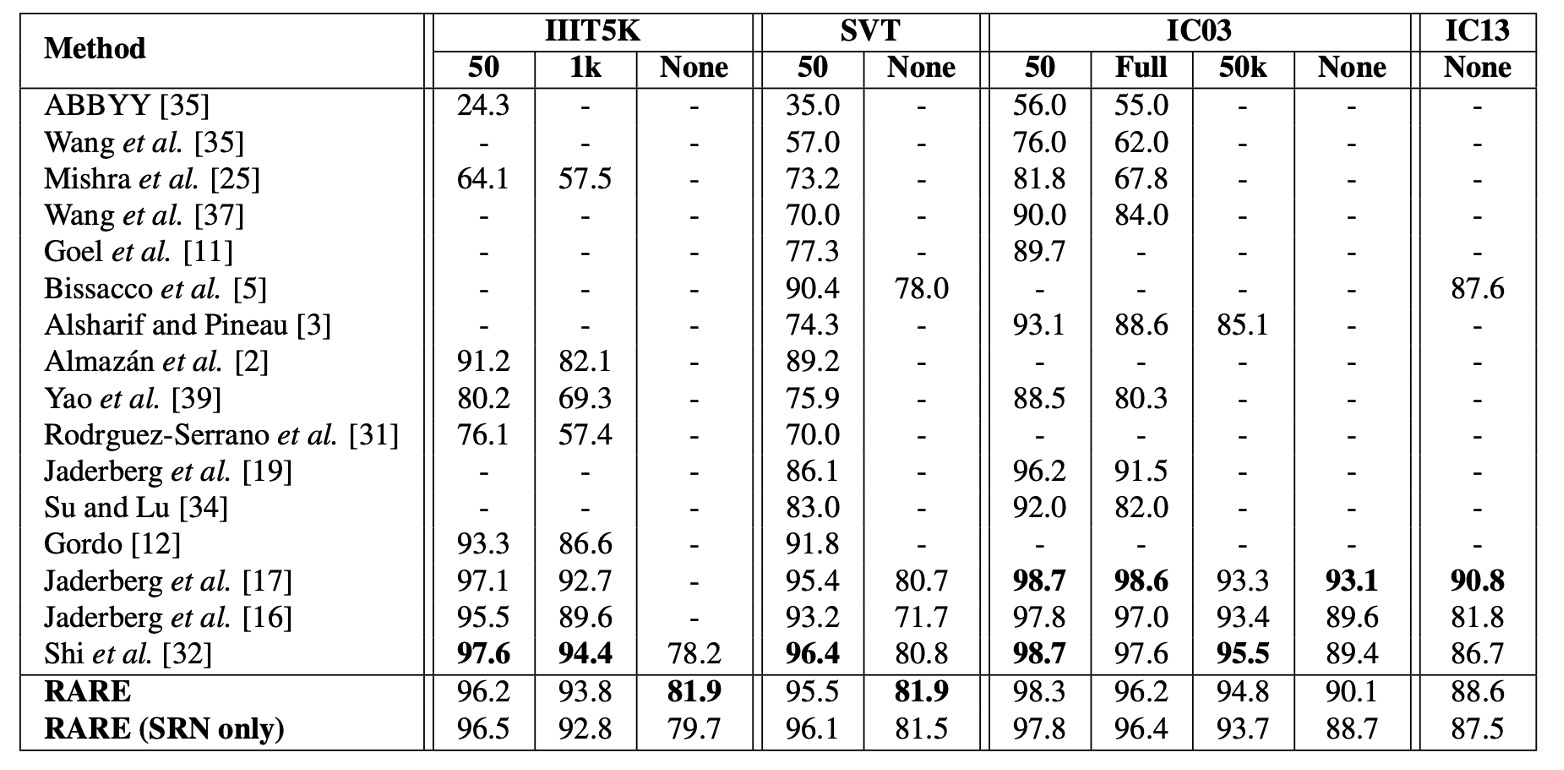
The table above shows the results of the model on the benchmark datasets, compared to other methods. In the "without dictionary assistance" task, the model outperforms all compared methods.
On the IIIT5K dataset, RARE improves performance by nearly 4 percentage points compared to CRNN【32】, showing a significant performance boost. This is because IIIT5K contains a large number of irregular texts, especially curved text, where RARE has an advantage in handling irregularities.
Although the model falls behind the method in【17】on some datasets, RARE is able to recognize random strings (such as phone numbers), while the model in【17】is limited to recognizing words within its 90k-word dictionary.
In the dictionary-assisted recognition task, RARE achieves comparable accuracy to【17】on IIIT5K, SVT, and IC03, and only slightly falls behind CRNN, demonstrating strong competitive performance even with dictionary assistance.
At that time, it wasn't common to name your theoretical approach or method. Hence, we often see naming conventions based on the author's name, such as method 【17】 in the table, which refers to Jaderberg et al.'s paper:
Conclusion
This paper primarily addresses the problem of recognizing irregular text by introducing a differentiable Spatial Transformer Network (STN) module to automatically rectify irregular text and achieve end-to-end training, achieving good performance on several benchmark datasets.
The authors also pointed out that the model performs poorly on "extremely curved" text, possibly due to the lack of corresponding data types in the training set, which presents an opportunity for future improvements.

Around 2020, we attempted to deploy this model, but encountered difficulties when converting it to ONNX format, mainly because ONNX did not support grid_sample or affine_grid_generator at that time.
We stopped paying attention to the model after that, but if you have successfully deployed it, feel free to share your experience with us.