[21.04] Soft Prompts
Strings Whispering Like Secrets
The Power of Scale for Parameter-Efficient Prompt Tuning
We just recently explored Prefix-Tuning, and now it's time to look at another new method: Prompt Tuning.
If you haven’t read about Prefix-Tuning yet, you may want to check out our previous article:
Problem Definition
In the design of Prefix-Tuning, a sequence of tokens called a prefix is added at the beginning of the model’s input to guide it in generating the desired output. This prefix needs to interact with every layer of the model to ensure that the guidance influences the model at all levels.
But can we simplify this process? What if we only provide guidance at the input layer? Would that be sufficient?
The concept of "guidance" here differs from the more commonly known Prompt Engineering. In Prompt Engineering, we use natural language prompts to steer the model's output. This approach does not modify the input features, adjust parameters, or change the model architecture.
Prompt Tuning, however, involves adding a special trainable token at the input layer. During training, the model learns how to utilize this token to discover the optimal way to guide itself.
Problem Solution
Prompt Tuning
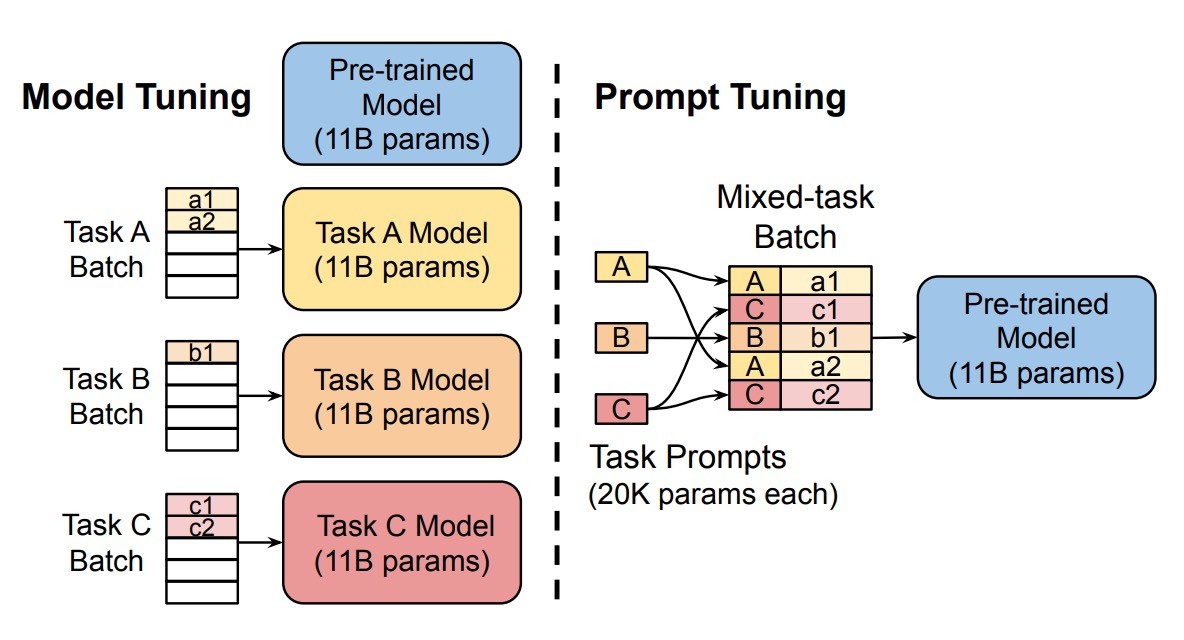
To better understand the concept of Prompt Tuning, the authors build on the text-to-text framework introduced by T5 (Raffel et al., 2020). T5 treats all tasks as text generation problems—whether it’s translation, summarization, or classification, each task is represented as generating text output from text input.
Traditional classification models rely on the probability function , mapping an input to an output class . This means that the model predicts which class the input belongs to.
However, the T5 framework focuses on conditional generation tasks, where the objective is to compute:
where:
- is the text sequence representing a class (e.g., "positive" or "negative").
- represents the parameters of the Transformer model.
The advantage of this approach is that it enables the model to generate richer text outputs, instead of merely assigning a class label.
A prompt is a piece of text added to the beginning of the input to guide the model toward generating the correct output . It provides context or instructions to help the model understand how to handle the input.
For instance, in a sentiment analysis task, a prompt might be:
"Please determine the sentiment of the following sentence:"
This prompt is concatenated with the user’s input sentence to form the final input to the model.
In models like GPT-3, the prompt is part of the model's embedding table, represented by frozen parameters . However, crafting prompts manually is labor-intensive, inconsistent, and non-differentiable.
To address these challenges, the authors propose Prompt Tuning.
Prompt Tuning introduces trainable prompt embeddings that are not limited to the original embedding table. These parameters can be automatically learned from training data.
The new conditional generation formula becomes:
where:
- denotes the concatenation of the prompt and the input .
- refers to the frozen model parameters.
- represents the trainable prompt parameters.
During training, only the prompt parameters are updated using backpropagation, while the main model parameters remain unchanged.
Implementation Steps
- Input Embedding: Embed the tokens of the input into a matrix , where is the embedding dimension.
- Prompt Embedding: The prompt embeddings form a matrix , where is the prompt length.
- Concatenation: The prompt and input embeddings are concatenated as:
- Model Computation: The concatenated embeddings are fed into the encoder-decoder model for processing.
Let’s consider an example where the task is to determine the sentiment of the sentence: "I love this movie!"
Traditional Approach:
- Manual Prompt: "Please determine the sentiment of the following sentence:"
- Model Input: "Please determine the sentiment of the following sentence: I love this movie!"
Prompt Tuning Approach:
-
Initialize the Prompt:
- Set the prompt length to , meaning five trainable prompt vectors.
- These vectors can be initialized randomly or selected from the embedding table.
-
Model Input: The prompt vectors are concatenated with the input sentence's embeddings to form the model’s input.
-
Training Process:
- Use a large amount of labeled sentiment analysis data.
- Update only the prompt parameters through backpropagation.
- The model learns to generate the correct sentiment label when it sees the learned prompt.
-
Model Output: For the input "I love this movie!", the model might generate "positive".
Discussion
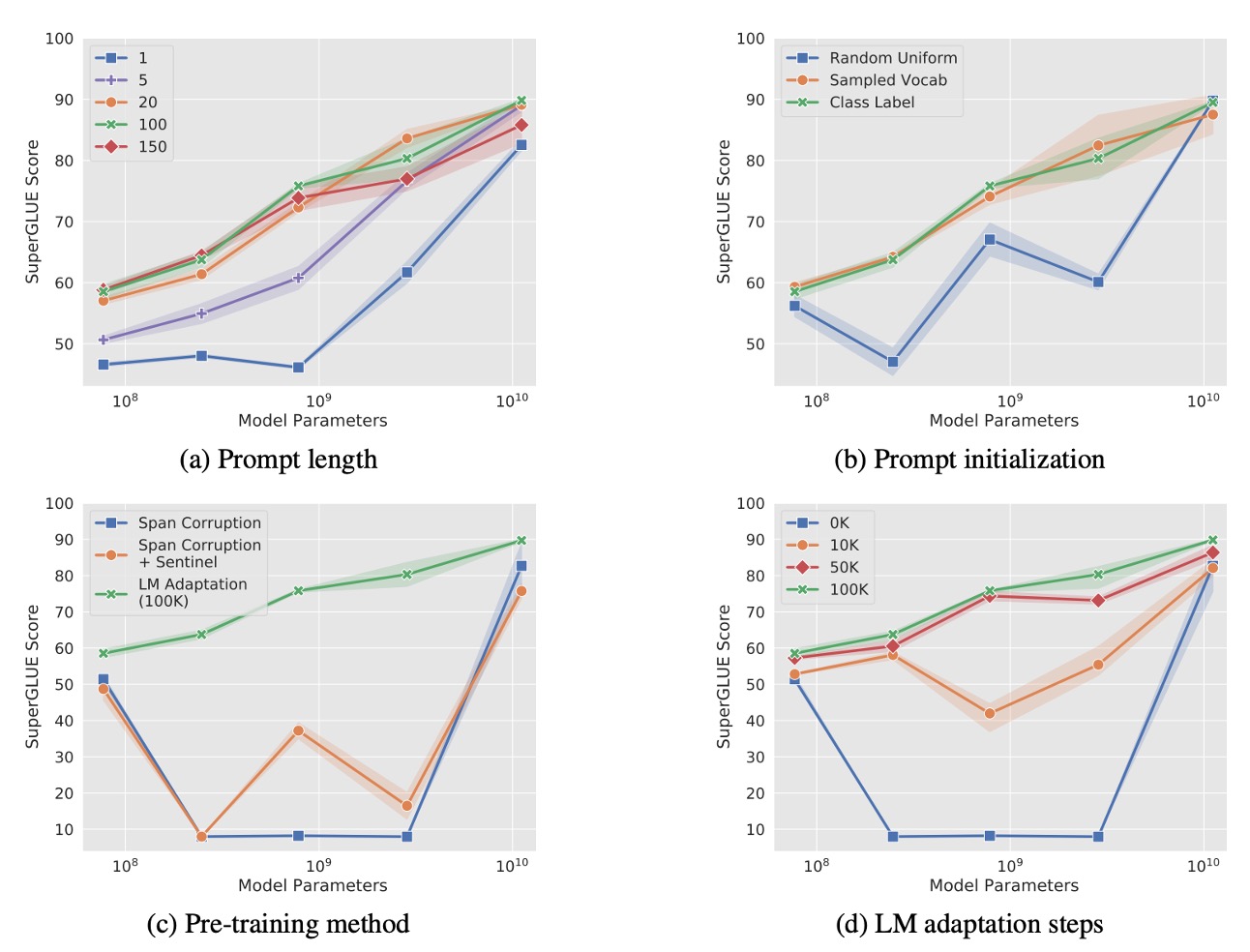
The authors conducted a series of ablation studies to investigate several key questions about Prompt Tuning:
How Long Should the Prompt Be?
As shown in Figure (a), the authors tested different prompt lengths across various model sizes (Small, Base, Large, XL, XXL).
The results indicate that for most models, using more than one token significantly improves performance. However, for the T5-XXL model, even a single-token prompt achieves decent results, suggesting that larger models require less prompting to perform well.
Performance gains plateau after 20 tokens, with only minor improvements beyond that length.
How Does the Initialization Strategy Affect Performance?
In Figure (b), the authors compared three initialization strategies:
- Random Initialization: Tokens are sampled uniformly from the range .
- Vocabulary Embedding Initialization: Tokens are initialized from embeddings of the 5,000 most frequent words in T5’s vocabulary.
- Label Embedding Initialization: For classification tasks, labels are converted into embeddings. If a label consists of multiple tokens, the embeddings are averaged. If the prompt length exceeds the number of labels, the remaining tokens are filled using embeddings from the vocabulary.
The results show that label embedding initialization yields the best performance across all model sizes, especially for smaller models, where the choice of initialization has a significant impact. On the other hand, T5-XXL is less sensitive to the initialization strategy, maintaining stable performance across different methods.
How Does the Pre-training Objective Affect Performance?
Figure (c) explores the impact of different pre-training objectives on Prompt Tuning:
- Span Corruption: Uses the standard T5 span corruption objective during pre-training.
- Span Corruption + Sentinel: Adds sentinel tokens in the target output during fine-tuning to simulate the span corruption format used in pre-training.
- LM Adaptation: Fine-tunes the T5 model for an additional 100,000 steps using a language modeling (LM) objective instead of span corruption.
The results show that models pre-trained with span corruption are not well-suited for Prompt Tuning with frozen parameters. This is because the model is accustomed to both reading and producing outputs with sentinel tokens. Even using the Span Corruption + Sentinel strategy to simulate the original pre-training format yields limited improvements.
In contrast, LM Adaptation significantly boosts performance across all model sizes, suggesting that switching to a pure language modeling objective makes the model more compatible with Prompt Tuning.
How Does the Duration of LM Adaptation Affect Performance?
Figure (d) analyzes the effect of the LM adaptation duration on Prompt Tuning performance.
The results show that extending the adaptation beyond 100,000 steps provides diminishing returns, with the optimal results appearing around that mark. Transitioning from span corruption to an LM objective is not a straightforward process—it requires substantial training resources (equivalent to 10% of the original T5 pre-training steps).
Despite the challenges, T5-XXL demonstrates high resilience across various non-optimal configurations. In contrast, smaller models sometimes outperform larger ones (Base, Large, and XL) under the span corruption setting. This inconsistency is not due to random noise, as the pattern was observed across three repeated experiments with low variance.
Compared to models pre-trained with span corruption, LM-adapted models exhibit much greater stability across all sizes, significantly reducing the risk of erratic performance. This highlights the importance of using LM adaptation for robust performance in Prompt Tuning.
Comparison with Other Methods
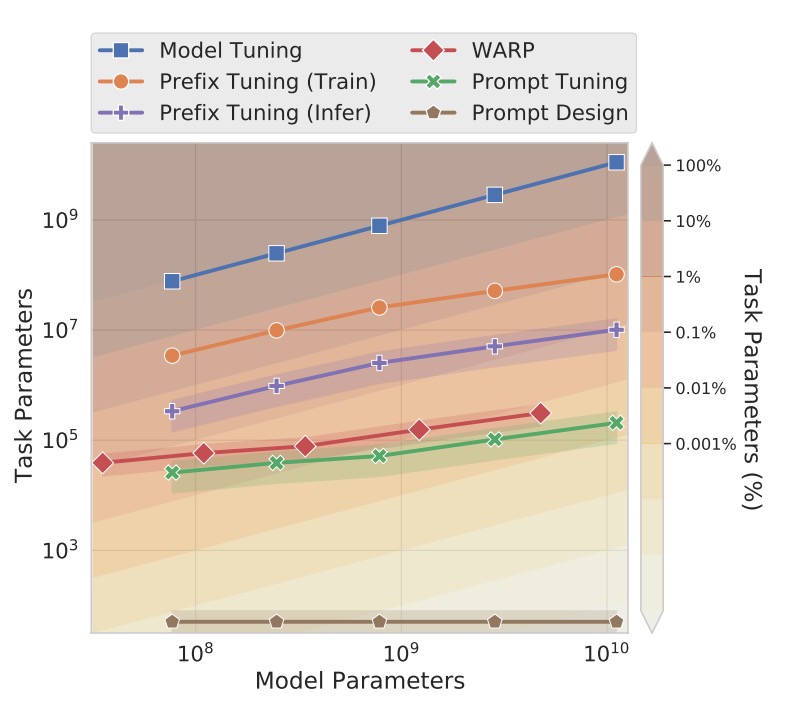
-
Prefix Tuning
Prefix Tuning involves adding trainable prefixes to every layer of the Transformer model, essentially acting as fixed activations for each layer. This method is suitable for models like GPT-2 and BART, while Prompt Tuning is designed for T5.
In BART, Prefix Tuning requires adding prefixes to both the encoder and decoder, whereas Prompt Tuning only involves adding a prompt to the encoder.
Prompt Tuning requires fewer parameters since it only introduces a single prompt token at the input layer, rather than prefixes across all layers. Moreover, Prompt Tuning enables the Transformer to update its task representation dynamically based on the input, whereas Prefix Tuning requires re-parameterization to stabilize the training process.
-
WARP (Word-level Adversarial ReProgramming)
WARP adds prompt parameters to the input layer and uses the [MASK] token along with a learnable output layer to map masked segments to class predictions. However, WARP is limited to generating a single output, making it more suitable for classification tasks only.
In contrast, Prompt Tuning does not require any specialized input design or task-specific output layers, making it more versatile for a broader range of tasks. Additionally, Prompt Tuning achieves performance closer to full model fine-tuning without complex input transformations.
-
P-Tuning
P-Tuning introduces learnable continuous prompts embedded between the input tokens and relies on human-designed patterns for arrangement. To achieve high performance on tasks like SuperGLUE, P-Tuning requires a combination of prompt tuning and model fine-tuning, meaning both the prompt and model parameters need to be updated.
In contrast, Prompt Tuning only updates the prompt parameters while keeping the language model frozen, avoiding the overhead of full model fine-tuning and reducing computational cost.
-
Soft Words
Soft Words rely on manually designed prompt templates and introduce learnable parameters (\Delta_i) at every layer of the Transformer model. As the model depth increases, the number of parameters grows, leading to larger memory requirements.
In contrast, Prompt Tuning maintains efficiency by not introducing additional parameters for each layer, keeping the parameter scale smaller and more manageable.
-
Adapters
Adapters are small bottleneck layers inserted between the frozen layers of the main model. This method reduces the number of task-specific parameters. For example, fine-tuning the Adapter layers in BERT-Large only increases the parameter count by 2–4% while maintaining near full fine-tuning performance.
While Adapters modify the model’s behavior by rewriting the activations in intermediate layers, Prompt Tuning adjusts the input representation without changing the internal computations, preserving the internal structure of the frozen model.
What Does Prompt Tuning Actually Encode?
Prompt Tuning guides a language model to generate the desired output by adjusting prompt vectors in continuous embedding space. However, since these prompts operate in the continuous space rather than the discrete word space, it is challenging to interpret how they influence the model's behavior. To better understand how Prompt Tuning works, the authors employed the following methods to analyze the effect of these prompts.
The authors calculated the cosine similarity between each prompt token and every token in the model’s vocabulary to identify the nearest-neighbor tokens. This helps reveal the semantic meaning encoded in each prompt token.
Key Findings:
-
Semantically Coherent Clusters: The nearest-neighbor words for each prompt token tend to form clusters of semantically related words, indicating that Prompt Tuning effectively learns meaningful representations similar to those of related words in the vocabulary.
-
Comparison with Random Vectors: When random vectors were used in place of trained prompt tokens, they failed to form coherent semantic clusters. This confirms that the effect of Prompt Tuning is not random—it captures and encodes the underlying semantic structure of the language model.
For longer prompt sequences, the authors observed that multiple prompt tokens often shared the same nearest-neighbor words, which raises two potential concerns:
-
Redundant Capacity: Some of the information within the prompt tokens may be repetitive or unnecessary, limiting further performance improvements.
-
Lack of Sequential Structure: The learned prompt representations do not effectively capture positional information within the sequence, making it difficult for the model to accurately locate and interpret key information.
An interesting observation is that many of the nearest-neighbor words for the prompt tokens often included class labels from the downstream tasks. This suggests that the expected output labels are implicitly stored within the prompt tokens, helping the model generate correct outputs.
Although the learned prompt sequences are difficult to interpret in natural language, they form semantically meaningful representations and enable effective internal adjustments within the model. These findings demonstrate that Prompt Tuning not only guides the model toward specific outputs but also has the potential to dynamically adjust the context within the model.
Conclusion
Prompt Tuning achieves performance comparable to traditional fine-tuning in various experiments, and the performance gap narrows further as the model size increases.
In zero-shot transfer tasks, Prompt Tuning exhibits superior generalization, suggesting that freezing the core language model parameters while limiting learning to lightweight prompt vectors can help avoid overfitting to specific domains.
Beyond its performance advantages, Prompt Tuning also offers benefits in terms of storage and serving costs. By keeping the pre-trained model frozen, it supports multi-task processing more efficiently and promotes the seamless integration of different prompts.
Looking ahead, a promising research direction could involve separating task-specific parameters from general language modeling parameters. This could lead to new ways of efficiently guiding models without the need for full fine-tuning.