[23.09] TIVC

Perspective on Twin Identification
Twin Identification over Viewpoint Change: A Deep Convolutional Neural Network Surpasses Humans
Identifying twins has always been a challenge in computer vision research.
This paper aims to compare the accuracy of human and Deep Convolutional Neural Networks (DCNN) in the identification of monozygotic twins, especially under varying viewpoints. Specifically, researchers aim to understand the differences in how these two systems distinguish highly similar faces and evaluate their reliability in real-world applications.
Review from Another Paper
Initially, we intended to review the following paper:
However, the PDF of this paper requires a paid download. We later found that subsequent papers cited this work extensively. Conveniently, we can now explore its content together!
Pre-DCNN Algorithms
From 2011 to 2014, numerous studies tested commercial face recognition algorithms on the task of distinguishing monozygotic twins. The consensus was that facial recognition technology of that era could not effectively distinguish identical twins. These early systems typically employed Principal Component Analysis (PCA) or manually selected features to process facial images, using a logarithmic likelihood function to reduce error rates. These studies predominantly relied on the Notre Dame Twins dataset (ND-TWINS-2009-2010).
In these early studies, for some twins, images could be acquired from both 2009 and 2010, supporting delayed recognition tests. The availability and quality of these datasets spurred multiple studies on twin face recognition. For example, in one study, participants completed an identity verification task, viewing pairs of monozygotic twins (different identity trials) and the same number of same identity image pairs, all taken under identical lighting conditions. The results showed that humans performed significantly better when given more time to make decisions, indicating the importance of time in recognizing identical twins.
Among the tested computer algorithms, only one commercial algorithm (Cognitec) approached but did not surpass human performance. Additionally, as image conditions varied, these early algorithms exhibited increased false positive rates when distinguishing identical twins.
Deep Learning Approaches
Deep learning, particularly DCNNs, has significantly advanced automatic face recognition technology. These networks' key strength lies in their ability to generalize across variations in images and appearances. Attempts to apply DCNNs to twin differentiation, though few, have yielded some initial success.
For instance, one study found that combining PCA, Histogram of Oriented Gradients (HOG), and Local Binary Patterns (LBP) outperformed object-trained CNNs on the ND-TWINS-2009 dataset. Another study created a baseline measure of facial similarity to assess the impact of "similar" identities without familial ties, revealing a significant number of potential look-alikes in large datasets.
Recent research also suggests that optimizing deep networks for twin identification is feasible. For example, some studies used large datasets for preliminary training, followed by optimization to distinguish monozygotic twins, achieving good results. However, a major limitation of these studies is the non-public availability of datasets, making it difficult to replicate and verify results.
The National Institute of Standards and Technology (NIST) conducted the Face Recognition Vendor Test (FRVT) to examine the problem of differentiating monozygotic twins. The study showed that all algorithms submitted to FRVT failed to detect twin impostors at a threshold producing a false positive rate of one in ten thousand. While these results provide valuable insights, the conclusions drawn are limited due to various factors.
In this study, researchers selected a high-accuracy DCNN and tested whether there was a relationship between human perception of highly similar images and DCNN by correlating their similarity ratings. This not only provides human benchmark tests using the same facial stimuli and viewpoint conditions as algorithm tests but also helps understand the reliability of face recognition systems for highly similar faces, including twins.
Defining the Problem
Returning to the original paper, given the challenge of identifying monozygotic twins for both humans and machine vision systems, the objective is straightforward:
- Compare the performance of humans and machines in distinguishing monozygotic twins.
Researchers aim to find ways to optimize machine vision systems by understanding the differences between human and computer vision in recognizing identical twins.
Solving the Problem
Experiment 1: Human Identification of Monozygotic Twins
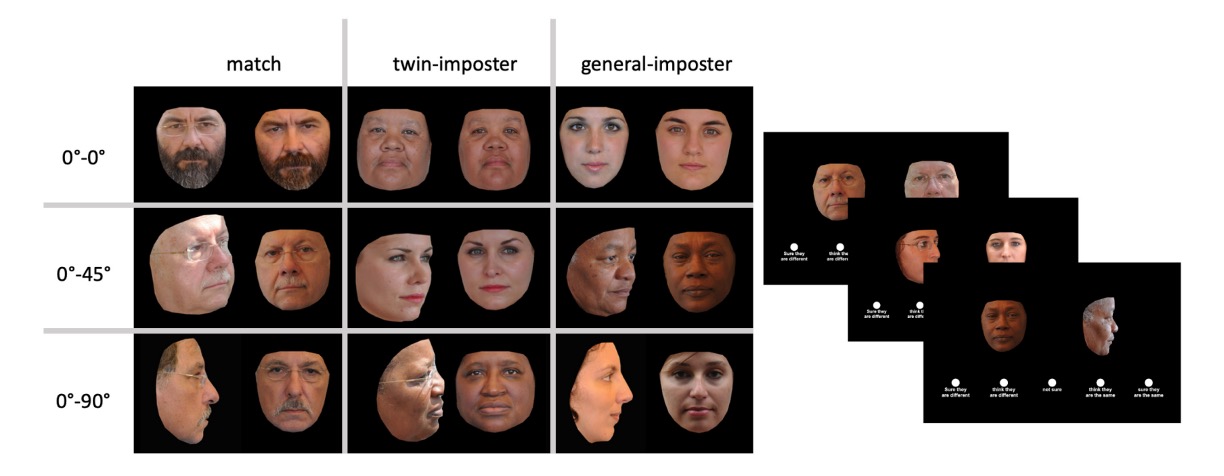
In Experiment 1, researchers measured the performance of human participants in identifying twins using the ND-TWINS-2009-2010 dataset.
Eighty-seven student participants from the University of Texas at Dallas (UTD) were recruited and compensated with course credits.
Twenty-nine participants were assigned to each viewpoint condition (frontal to frontal, frontal to 45 degrees, and frontal to 90 degrees). Participants had to be at least 18 years old and have normal or corrected-to-normal vision.
Eligibility was determined through a Qualtrics survey. All experimental procedures were approved by the UTD Institutional Review Board.
-
Experimental Design
Researchers tested facial identity matching (identity verification) based on the type of stimuli. The image pairs were either of the same identity (same identity pairs) or different identities. Different identity pairs were further divided into twin impostor pairs and general impostor pairs. Same identity pairs consisted of two different images of the same person. Twin impostor pairs consisted of monozygotic twins, while general impostor pairs consisted of images of two different, unrelated individuals. Each type of image pair was tested under three viewpoint conditions.
Identity matching accuracy was measured by calculating the AUC for two conditions: (a) same identity pairs vs. twin impostor pairs, and (b) same identity pairs vs. general impostor pairs.
-
Procedure
Participants first completed a screening questionnaire to determine eligibility, confirming they were at least 18 years old and had normal or corrected-to-normal vision. Eligible participants were directed to an online informed consent form. Upon completion, they received a code to schedule their study session. Participants met with a research assistant via a participant-specific Microsoft Teams link at the scheduled time.
The researcher briefly described the task, explaining that participants would see a series of face image pairs and rate the certainty of whether the pairs showed the same person or two different people. Participants were informed that the experiment might include identical twins.
During each trial, a pair of face images appeared side-by-side on the screen. Participants rated whether the image pair showed the same person or two different people using a 5-point scale. Response options included: (1) Definitely different people, (2) Probably different people, (3) Not sure, (4) Probably the same person, (5) Definitely the same person.
Participants selected their rating with a mouse, and the images and scale remained on screen until a response was made. The experiment was programmed in PsychoPy. The order of trials was randomized for each participant.
Experiment 2: DCNN Identification of Monozygotic Twins
In the algorithmic test, a DCNN based on the ResNet-101 architecture was used. The network was trained on the Universe dataset, a web-crawled dataset containing 5,714,444 images of 58,020 unique identities. The dataset features significant variability in attributes like pose, lighting, resolution, and age. The demographic composition of the Universe dataset is unknown.
The network comprises 101 layers, using skip connections to maintain the error signal amplitude during training. Crystal loss with an alpha parameter set to 50 was applied to ensure the L2 norm remained constant during learning.
As a preprocessing step for network training, facial images were cropped to include only the internal face and aligned to a size of 128 × 128 before inputting into the network. This procedure was uniformly applied across all image poses. Once fully trained, the output of the penultimate fully connected layer was used to generate identity representation features for each image.
Discussion
Experimental Results
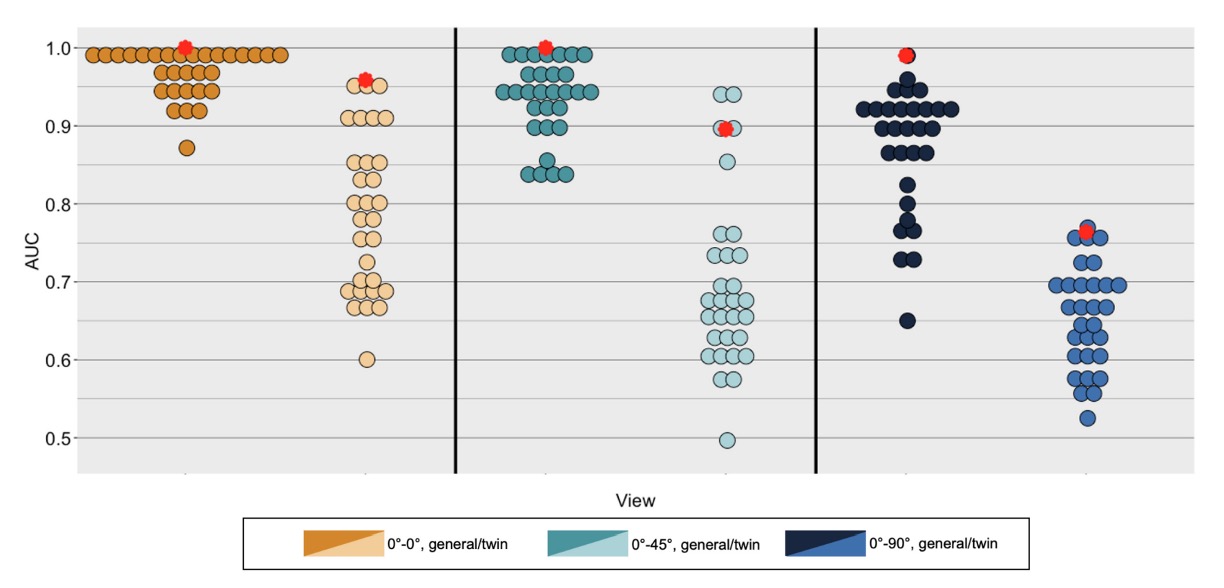
In the above image, the red dots represent the computer vision system's results, while the other dots represent human participants' results.
Under all conditions, identity matching accuracy was significantly higher for general impostor conditions than for twin impostor conditions.
As the viewpoint difference between images increased, accuracy decreased, with the decline being more pronounced for the twin impostor condition compared to the general impostor condition.
-
AUC Measurement Method
- For each participant, the AUC was calculated under each viewpoint condition for two scenarios:
- Image pairs under the general impostor condition.
- Image pairs under the twin impostor condition.
- For each participant, the AUC was calculated under each viewpoint condition for two scenarios:
-
Basis for AUC Calculation
- In both conditions, correct identity verification responses were generated from same-identity image pairs.
- False positives in the general impostor condition came from image pairs showing two different, unrelated identities.
- False positives in the twin impostor condition came from image pairs showing monozygotic twins.
-
Human Experiment Results
- General impostor condition, frontal to frontal: 0.969
- Twin impostor condition, frontal to frontal: 0.874
- General impostor condition, frontal to 45 degrees: 0.933
- Twin impostor condition, frontal to 45 degrees: 0.691
- General impostor condition, frontal to 90 degrees: 0.869
- Twin impostor condition, frontal to 90 degrees: 0.652
-
DCNN Experiment Results
For each image pair viewed in the human data collection experiment, the DCNN generated similarity scores. The accuracy of the DCNN in distinguishing identities was measured by calculating the AUC assigned to same-identity and different-identity image pairs. Correct responses came from image pairs showing the same identity, while false positives came from image pairs showing different identities. The performance of the DCNN is shown in the above figure, represented by red circles, overlaid on the individual human performance data.
- For the general impostor condition, the DCNN achieved perfect identity matching performance (AUC = 1.0).
- For the twin impostor condition, the DCNN's identity matching performance remained high (AUC = 0.96).
Conclusion
This study emphasizes the importance of epigenetic biometric features in distinguishing monozygotic twins. Although fingerprints and iris textures are considered the most reliable methods, facial recognition technology also shows promise.
Compared to earlier face recognition algorithms, DCNNs maintain high accuracy under different viewpoints and lighting conditions, demonstrating significant improvements.
The experimental results indicate that DCNNs surpass most human participants in all tested conditions, particularly in the challenging task of twin identification. This contrasts with the findings of the NIST, highlighting the importance of considering DCNN performance in different problem contexts. Human participants showed considerable individual variability, while the DCNN consistently maintained high performance without individual differences. Future research should consider incorporating more identification information, including external features, and further explore the nature of facial representations generated by DCNNs to enhance the combined performance of humans and machines in twin identification tasks, which is especially important for challenging image matching tasks such as forensic applications.
*
Having reviewed this paper, we believe the most important conclusion is:
- The performance of computer vision systems and humans is consistent, so exploring the mechanisms by which human experts identify twins can help improve computer vision systems.
Although we hoped the paper would provide solutions or architectures for solving the twin identification problem, it did not. However, since we've gone through it, we might as well record it here.