[23.09] TIVC-DCNNSH

雙胞胎辨識的觀點
Twin Identification over Viewpoint Change: A Deep Convolutional Neural Network Surpasses Humans
雙胞胎辨識的問題一直是機器視覺研究的一個挑戰。
本篇論文旨在比較人類和深度卷積神經網路(DCNN)在同卵雙胞胎身份驗證中的準確性,並測試在視角變化時的表現。
研究者希望了解這兩種系統在高度相似的面孔區分方面的差異,以及在實際應用中,這些系統的可靠性。
來自另外一篇論文的回顧
本來我們要看的是這篇論文:
但是這篇論文的 PDF 必須付費購買才能下載。
後來我們發現,後續有其他論文引用了這篇付費的論文,而且有大篇幅地回顧了那篇論文的內容。
嘿!這麼剛好!那我們就一起了解一下吧!
DCNN 之前的演算法
2011 年至 2014 年間,許多研究測試了商業人臉辨識演算法在區分同卵雙胞胎方面的效能,得出的結論是當時的人臉辨識技術無法有效區分同卵雙胞胎。當時,以電腦為基礎的人臉辨識系統通常使用主成分分析(PCA)或手動選擇的特徵來處理人臉影像,並採用對數似然函數來降低錯誤率。這些研究幾乎完全依賴 Notre Dame Twins 資料集 (ND-TWINS-2009-2010) 的人臉影像。
在這些早期研究中,對於一些雙胞胎,可以從 2009 年和 2010 年拍攝的照片中獲取影像,從而支援延時辨識測試。這些資料集的可用性和品質激發了對雙胞胎人臉辨識的多項研究。例如,在一項研究中,參與者完成了一項身份驗證任務,其中他們查看了成對的同卵雙胞胎兄弟姐妹(不同身份試驗)和相同數量的相同身份圖像對。所有影像對都是在相同的照明條件下拍攝的。結果顯示,人類在有更多時間做出決定時的表現要比僅檢查影像對 2 秒時好得多,這表明了時間對於人類辨識同卵雙胞胎的影響。
在測試的電腦演算法中,只有一種商業演算法(Cognitec)的效能接近但低於人類效能。此外,隨著影像條件變化,這些早期演算法在區分同卵雙胞胎時的誤報率也會增加。
深度學習方法
深度學習方法,特別是深度卷積神經網路(DCNN),在推進自動人臉辨識領域的最新技術方面取得了巨大成功。這些網路的一個強大優勢是它們能夠概括圖像和外觀變化。將 DCNN 應用於區分同卵雙胞胎的嘗試雖然不多,但已經取得了一些初步的成功。
例如,在一項研究中,基於 PCA、定向梯度直方圖(HOG)和局部二值模式(LBP)的局部特徵提取演算法的組合在 ND-TWINS-2009 資料集上比物件訓練的 CNN 表現得更準確。在另一項研究中,研究者創建了一個基線面部相似性測量,並使用該基線來測量沒有家庭關係的「相似」身份的影響。他們發現,根據上述閾值的定義,15,455 個身份中有 6,153 個具有一個或多個潛在的相似者,表明在大規模資料集中存在大量的潛在相似者。
此外,近期的研究還表明,將針對雙胞胎辨識優化的深度網路應用於辨識雙胞胎的問題是合理的。例如,某些研究使用大型資料集進行初步訓練,隨後進行最佳化以區分同卵雙胞胎,並在測試中取得了不錯的效果。然而,這些研究的一個主要限制是資料集無法公開,這使得實驗結果難以複製和驗證。
美國國家標準與技術研究所(NIST)進行的人臉辨識供應商測試(FRVT)也檢驗了區分同卵雙胞胎的臉部問題。研究表明,提交給 FRVT 的所有演算法都無法在產生萬分之一誤報的閾值下檢測到同卵雙胞胎冒名頂替者。這些結果雖然提供了有價值的視角,但由於多種原因,從研究結果中得出的結論是有限的。
在本研究中,研究者選擇了一個高準確度的 DCNN,並通過關聯人類和機器的相似度評級來測試人類對高度相似圖像的感知與 DCNN 之間是否存在關係。這不僅提供了對演算法測試中使用的完全相同的臉部刺激和視點條件的人類基準測試,也有助於了解人臉辨識系統對於高度相似的臉部(包括雙胞胎)的可靠性。
定義問題
好,看完了之前的文獻回顧,讓我們回到原本要看的這篇論文。
由於同卵雙胞胎不論在人類眼中或是在機器視覺系統中,都極具挑戰性,因此這篇論文要做的事情其實很簡單:
- 就是比較人類和機器在區分同卵雙胞胎方面的表現。
研究者透過了解電腦視覺系統和人類認知的差異,試圖找到優化機器視覺系統的方法,以提高對同卵雙胞胎的辨識準確性。
解決問題
實驗 1:人類對同卵雙胞胎的辨識
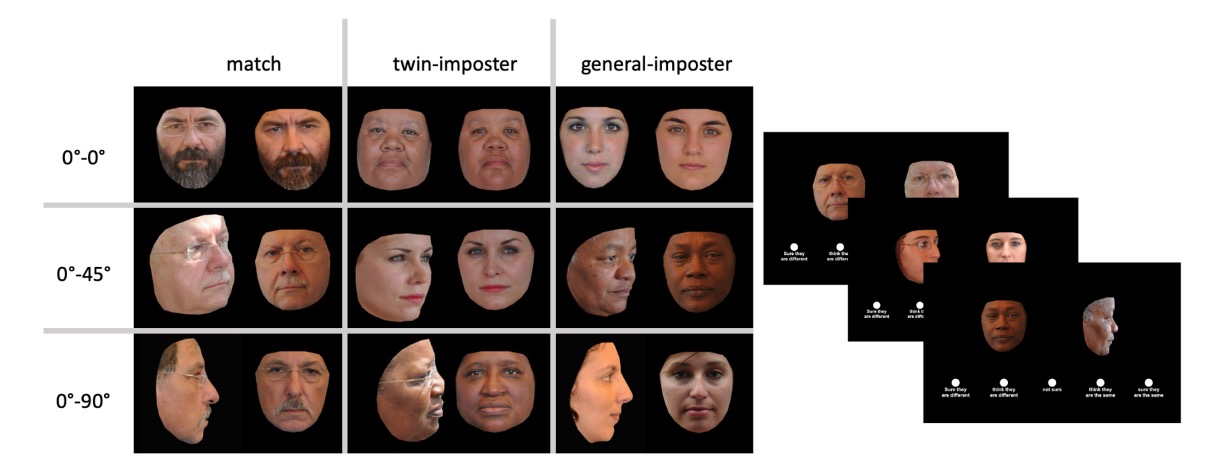
在實驗 1 中,研究者使用 ND-TWINS-2009-2010 資料集測量了人類參與者對雙胞胎的辨識性能。
研究者從德州大學達拉斯分校(UTD)招募了 87 名學生參與者。參與者以獲得課程學分作為報酬。
每個視角條件(正面對正面、正面對 45 度和正面對 90 度)各有 29 名參與者。參與者必須年滿 18 歲並具有正常或矯正後正常的視力。
參與資格通過 Qualtrics 調查進行自我報告。所有實驗程序均經過 UTD 機構審查委員會批准。
-
實驗設計
研究者測試了圖像對中的臉部身份匹配(身份驗證),並根據刺激類型進行了測試。圖像對顯示的是相同身份(相同身份對)或不同身份。在不同身份對的情況下,不同身份對分為雙胞胎冒名頂替對和一般冒名頂替對。相同身份對由同一身份的兩張不同圖像組成。雙胞胎冒名頂替對由同卵雙胞胎兄弟姐妹組成。一般冒名頂替對由兩個不同且無關的人物圖像組成。每種類型的圖像對在三個視角條件中都進行了測試。
身份匹配準確性通過計算兩個條件的 AUC 來測量:(a)相同身份對與雙胞胎冒名頂替對,和(b)相同身份對與一般冒名頂替對。
-
程序
參與者首先完成一份篩選問卷以確定資格。問卷確認參與者至少 18 歲並且具有正常或矯正後正常的視力。如果參與者滿足條件,他們將被引導到在線知情同意書。參與者完成知情同意書後,將獲得一個訪問代碼以安排研究時間。參與者在預定的時間內,通過特定於參與者的 Microsoft Teams 鏈接與研究助理見面。
研究員簡要描述了任務,解釋參與者將看到一系列臉部圖像對,並對每對圖像顯示的是同一個人還是兩個不同的人進行確定性評分。參與者被告知實驗中可能會有同卵雙胞胎。
在每次試驗中,一對臉部圖像並排出現在螢幕上。參與者被要求使用 5 點量表來判斷圖像對顯示的是同一個人還是兩個不同的人。回應選項包括:(1)確定是不同的人,(2)認為是不同的人,(3)不確定,(4)認為是同一個人,(5)確定是同一個人。
參與者使用滑鼠選擇評分,圖像和量表將保持在螢幕上直到參與者選擇回應。實驗在 PsychoPy 中編程。每位參與者的試驗呈現順序是隨機的。
實驗 2:DCNN 對同卵雙胞胎的辨識
在演算法測試中,我們使用了基於 ResNet-101 架構的深度卷積神經網路(DCNN)。該網路在 Universe 資料集上進行訓練,這是一個從網路上抓取的野外資料集,包含 5,714,444 張圖像,涉及 58,020 個唯一身份。這些訓練數據集中的圖像屬性變化很大,包括姿勢、光照、解析度和年齡。用於訓練網路的 Universe 資料集的族群組成尚不清楚。
該網路包含 101 層,使用跳躍連接來保持訓練過程中誤差信號的幅度。為了確保 L2 范數在學習過程中保持不變,應用了 Crystal loss,alpha 參數設置為 50。
此外,作為網路訓練的預處理步驟,臉部圖像被裁剪以包含內部臉部,並對齊到 128 × 128 的大小後再輸入網路。該流程對所有圖像姿勢都以相同方式應用。當完全訓練的網路完成後,倒數第二個全連接層的輸出用於生成每張圖像的身份表示特徵。
討論
實驗結果
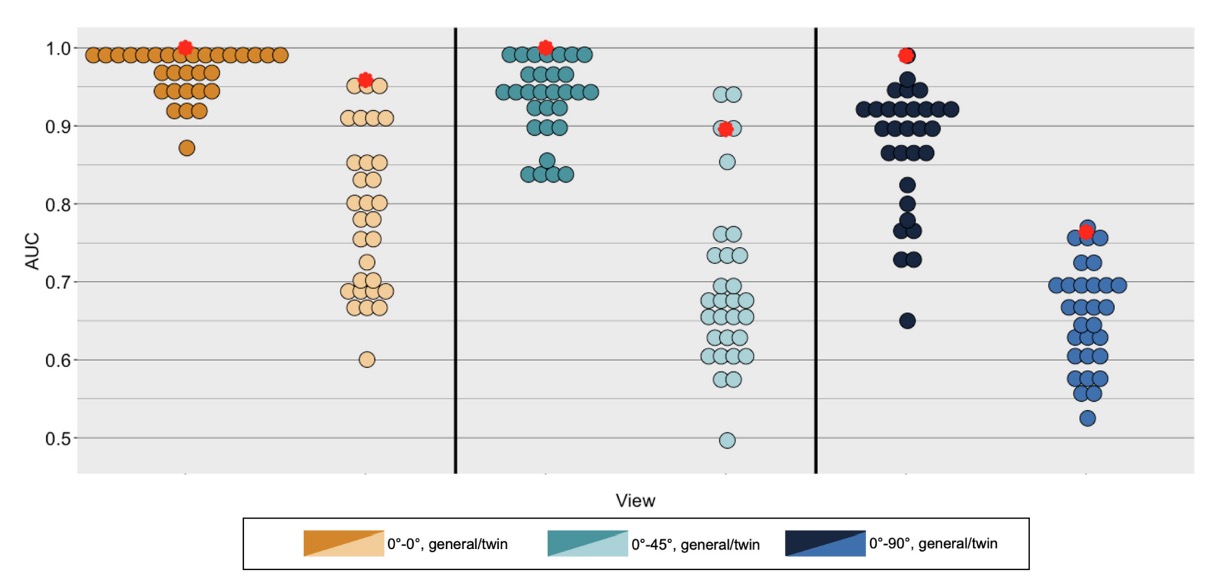
上圖中,紅色點為電腦視覺系統的結果,其他點為人類參與者的結果。
在所有條件下,一般冒名頂替條件下的身份匹配準確度明顯高於雙胞胎冒名頂替條件。
隨著圖像之間視角差異的增加,準確度下降,且雙胞胎冒名頂替條件下的下降幅度比一般冒名頂替條件更為顯著。
-
AUC 測量方法
- 每個參與者在每個視角條件下,計算了兩種條件的 AUC:
- 一般冒名頂替條件中的圖像對
- 雙胞胎冒名頂替條件中的圖像對
- 每個參與者在每個視角條件下,計算了兩種條件的 AUC:
-
AUC 計算基礎
- 在兩個條件下,相同身份的圖像對生成了正確的身份驗證反應。
- 一般冒名頂替條件中的誤報來自顯示兩個不同且無關身份的圖像對。
- 雙胞胎冒名頂替條件中的誤報來自顯示同卵雙胞胎的圖像對。
-
人類實驗結果
- 一般冒名頂替條件,正面對正面:0.969
- 雙胞胎冒名頂替條件,正面對正面:0.874
- 一般冒名頂替條件,正面對 45 度側面:0.933
- 雙胞胎冒名頂替條件,正面對 45 度側面:0.691
- 一般冒名頂替條件,正面對 90 度側面:0.869
- 雙胞胎冒名頂替條件,正面對 90 度側面:0.652
-
DCNN 實驗結果
在收集人類數據實驗中觀看的每對圖像對,DCNN 都生成了相似度評分。通過計算分配給相同身份圖像對和不同身份圖像對的相似度評分的 AUC 來測量 DCNN 的辨識準確度。正確的反應來自顯示相同身份的圖像對,而誤報來自顯示不同身份的圖像對。DCNN 的性能顯示在上圖中,以紅色圓圈表示,覆蓋在人類個體表現數據上。
- 對於一般冒名頂替條件,DCNN 獲得了完美的身份匹配性能(AUC = 1.0)。
- 對於雙胞胎冒名頂替條件,DCNN 的身份匹配性能仍然很高(AUC = 0.96)。
結論
本研究強調了在區分同卵雙胞胎時,表觀遺傳生物特徵的重要性,儘管指紋和虹膜紋理被認為是最可靠的方法,但臉部辨識技術也展示了其潛力。
深度卷積神經網路相較於早期的臉部辨識演算法,在不同視角和光照條件下仍能保持高準確度,顯示出顯著的進步。
本論文實驗結果表明,DCNN 在所有測試條件下的準確度均超過了大多數人類參與者,特別是在挑戰性高的雙胞胎辨識任務中,這與美國國家標準與技術研究所(NIST)的研究結果形成對比,強調了在不同問題背景下考量 DCNN 性能的重要性。人類參與者的表現顯示出廣泛的個體差異,而 DCNN 始終保持在高水平且無個體差異。未來研究應考慮包括外部特徵在內的更多辨識信息,並進一步探討 DCNN 生成的面部表示的性質,以提升人類和機器在雙胞胎辨識任務中的聯合作用,這對於如法醫應用等困難的圖像匹配任務尤為重要。
*
看完這篇論文,我們認為只有一個比較重要的結論:
- 電腦視覺系統和人類的表現是一致的,因此探討人類專家是如何辨識雙胞胎的機制,可以幫助我們改進電腦視覺系統。
本來我們期待這篇論文能給出解決雙胞胎辨識問題的方法或架構,但沒有。
不過既然都看完了,就順手記錄在此吧。