[19.02] GPT-2

四十八層解碼器
Language models are unsupervised multitask learners
第一代的 GPT 疊了十二層 Transformer 解碼器。
OpenAI 覺得這樣不夠,於是他們疊了四十八層 Transformer 解碼器,這就是 GPT-2。
定義問題
作者認為現有的機器學習系統表現出色,但其實充滿問題。
在這篇文章中,簡要的說明了幾個方向:
脆弱性
- 機器學習系統在資料分佈和任務規範的輕微變化方面表現出脆弱性。
- 這些系統對於不同輸入的多樣性和變化缺乏穩定性,導致不穩定的行為。
狹隘專家的局限性
- 當前的機器學習系統更像是狹隘的專家,而不是通用型的系統,限制了其應用範圍。
- 這些系統依賴於為每個特定任務手動建立和標記訓練資料集,過程繁瑣且不具通用性。
泛化能力不足
- 單域資料集上單任務訓練的普遍存在導致了系統缺乏泛化能力。
- 為了實現穩健的系統,可能需要在更廣泛的領域和多任務上進行培訓和測量效能。
解決問題
這篇論文沒有提出新的模型架構,而是將現有的 GPT-1 模型進行了擴展。
模型設計
首先,將 LayerNorm 移到了每個子塊的輸入處,這與前啟動殘差網路類似。此外,作者在最後一個自注意力塊(self-attention block)之後添加了一個額外的層歸一化。
作者使用了一種修改過的初始化方法,考慮到模型深度增加時殘差路徑上的累積。在初始化時將殘差層的權重按 1/√N 的因子進行縮放,這裡 N 是殘差層的數量。
為了增強模型的能力,作者將詞彙表擴展到 50,257。上下文大小也從 512 增加到 1024 個 Tokens,並且使用更大的 Batch size 為 512。
如果你有經驗,就會知道在這種設計下,Batch size 為 512 真的是個很大的數字。
多任務學習
一個通用系統應該能夠執行許多不同的任務。這意味著系統需要對 P(輸出|輸入,任務) 進行建模,而不僅僅是對單一任務的條件分佈 P(輸出|輸入) 進行建模。
在這裡,作者提出的實現方式為:將輸入和輸出全部指定為符號序列,並使用語言建模來訓練模型。例如,翻譯訓練範例可以表示為(翻譯為法文、英文文字、法文文字),而閱讀理解訓練範例可以表示為(回答問題、文件、問題、答案)。
總之,就是用文字說明,來區分不同的任務。
多樣化的資料
大多數先前的語言模型訓練工作集中在單一文本域,例如新聞文章、維基百科或小說書籍。作者提出的方法則鼓勵建立盡可能大和多樣化的資料集,以便涵蓋更多領域和上下文的自然語言演示。
為此,作者選擇了網頁抓取,特別是使用了 Common Crawl 資料集。
但是用了之後,發現 Common Crawl 存在嚴重的資料品質問題...
-
解決方案
- 新的網頁抓取:為了提高資料品質,作者抓取來自 Reddit 平台的所有出站鏈接,這些鏈接至少「需要獲得了 3 個其他用戶的認同」,才會被認為是可以使用的乾淨資料。
- 資料集 WebText:產生的資料集 WebText 包含這 4500 萬個連結的文字子集。WebText 初步版本不包括 2017 年 12 月之後創建的鏈接,經過重複數據刪除和啟發式清理後,包含略超過 800 萬個文件,共計 40 GB 文字。
- 維基百科文件排除:從 WebText 中刪除了所有維基百科文件,避免訓練資料與測試評估任務重疊,從而使分析更加準確。
這表示在 2017 年以前的資料才是沒有經過語言模型「污染」的真實人類語言。在這之後,人們很難判斷一篇文章或是一段文字到底是人寫的還是機器寫的。
這對之後的模型訓練產生很大的挑戰,因為當模型學習自己產生的資料時,任何錯誤或偏差都會被放大。隨著迭代次數增加,這些錯誤會累積,導致模型性能逐漸惡化,直到最終崩潰。
優化 BPE 編碼
位元組級 BPE 的優勢在於其靈活性和通用性,因為它可以將任何字元分解為位元組序列。然而,直接將 BPE 應用於位元組序列上,可能會因為 BPE 使用貪婪的頻率算法來構建詞彙,導致次優的合併結果。
為了解決這個問題,作者提出了一種改進的方法:在位元組序列中,阻止不同字元類別之間的合併,僅對空格作為例外。這樣可以顯著提高壓縮效率,同時僅在多個詞彙標記中添加最少的單字碎片。
這可能像是拼拼圖。
普通的 BPE 就像是你先把一些經常出現的拼圖塊組合起來,比如天空的部分、草地的部分,然後把這些組合好的大塊放到一起拼。這樣做的好處是,你很快就能拼出一大片天空或一大片草地,效率很高。
不過,如果這個拼圖的圖案非常複雜,有很多種不同的圖案組合(相當於 Unicode 字元),你需要記住所有這些圖案的組合方式,這樣你的拼圖塊就會變得非常多,管理起來很麻煩。
位元組 BPE(Byte-Level BPE)
位元組 BPE 的方法就像是你不管這些圖案,只關注每一塊拼圖本身。你把每一塊拼圖分成更小的單位,可能是每一小片的顏色或形狀。這樣做的好處是,你只需要記住這些基本的單位,而不需要記住整個圖案的組合方式。你的拼圖塊數量大大減少,只需要管理 256 種基本單位,比起成千上萬種圖案組合簡單多了。
但這也有一個問題,如果你隨意地把這些小單位組合起來,你可能會發現拼圖變得更加零散,比如說你會把一部分天空和一部分草地混在一起,這樣你很難拼出完整的圖案。
為了解決這個問題,作者提出了一個改進的方法。他們決定在組合這些小單位時,避免把不同類型的圖案混合在一起,比如不把天空和草地的單位混在一起,這樣可以保證每一部分圖案更容易拼出來。同時,他們允許在圖案之間留一些空白,這樣可以保持每一部分圖案的完整性。
這樣一來,他們就能結合兩種方法的優點:既能有效地拼出大的圖案,又不需要記住過多的圖案組合方式。這種方法讓他們能夠更高效地完成拼圖遊戲,也更容易看到完整的圖案。
討論
模型尺寸
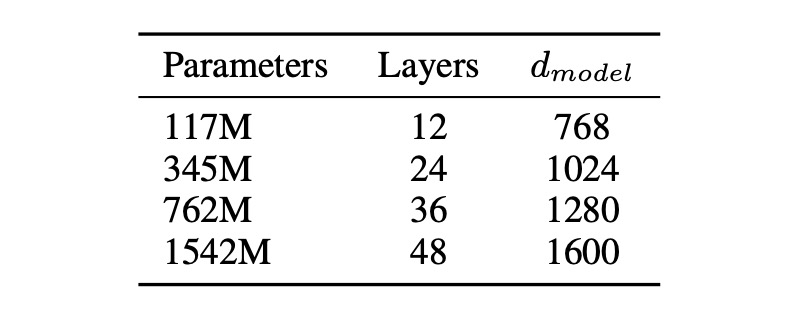
本論文提出了四個模型參數設計,進行了訓練和基準測試。
Zero-shot
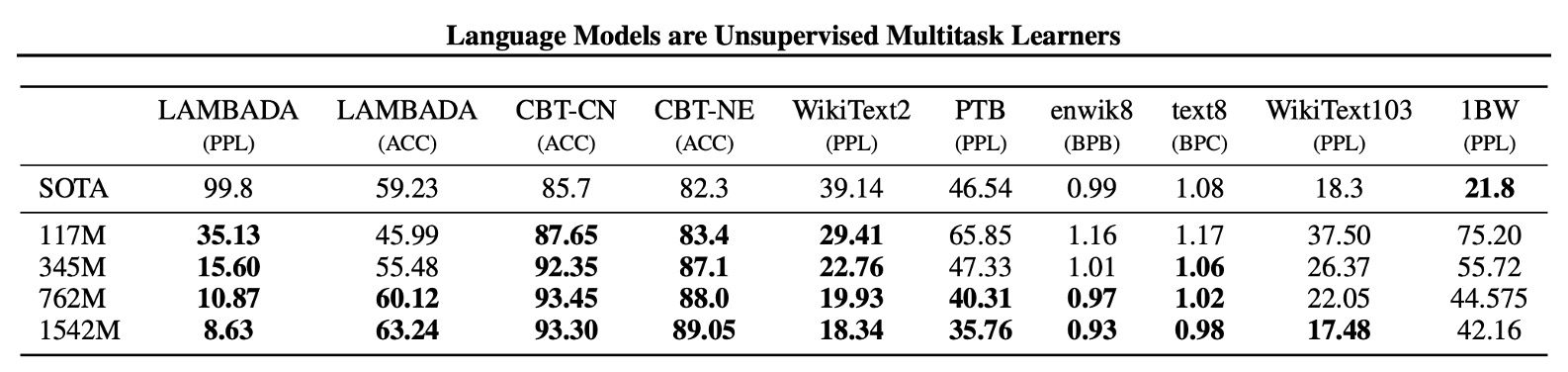
作者首先檢視模型的零樣本性能,即模型在未見過的任務上的表現。
他們發現,GPT-2 在跨域和跨資料集的遷移能力上表現良好,在零樣本設置中提升了 8 個資料集中的 7 個資料集的現有技術水平。在 Penn Treebank 和 WikiText-2 等小型資料集上,有顯著的改進,這些資料集僅有 100 到 200 萬個訓練標記。
針對長期依賴性測量的資料集(如 LAMBADA 和兒童圖書測試)也取得了巨大的進步。
| 指標 | 含義 | 解讀方式 |
|---|---|---|
| PPL | 困惑度:衡量模型預測序列的效果,數值愈低表示模型越好。 | 分數愈低,表示模型對序列的預測越準確,即模型越好。 |
| ACC | 準確率:衡量模型預測正確的比例。 | 分數越高,表示模型預測正確的比例越高,即模型越準確。 |
| BPB | 每位元組位數:每個位元組在二進制表示中平均需要的位數。 | 分數愈低,表示模型壓縮和預測的效率越高,即模型越優秀。 |
| BPC | 每字元位數:每個字元在二進制表示中平均需要的位數。 | 分數愈低,表示模型壓縮和預測的效率越高,即模型越優秀。 |
各類實驗
作者在各種不同的任務上進行了實驗,包括語言建模、機器翻譯、問答、文本摘要、文本生成等。
我們就簡單彙整一份表格,讓你快速了解 GPT-2 在各個任務上的表現:
| 測試名稱 | 目的 | 測試方式 | 結果 |
|---|---|---|---|
| 兒童圖書測驗 (CBT) | 檢查模型在不同類別單字上的表現。 | 預測完形填空測試中省略單字的正確選項。 | 普通名詞準確率 93.3%,命名實體準確率 89.1%。 |
| LAMBADA | 測試對遠端依賴關係的建模能力。 | 預測句子的最終單詞。 | 困惑度從 99.8 降至 8.6,準確率從 19% 提高到 52.66%;使用停用詞過濾器後準確度提高到 63.24%。 |
| Winograd Schema 挑戰 | 測量解決文本歧義的能力。 | 解決模糊性問題。 | 在 273 個範例的小型資料集上表現良好。 |
| 閱讀理解(CoQA) | 測試回答依賴對話歷史的問題能力。 | 使用對話問答資料集。 | 訓練集上達到 55 F1 分數,接近或超過四分之三的基線系統性能。 |
| 摘要 | 測試總結能力。 | 通過 Top-k 隨機採樣生成摘要。 | 生成摘要品質類似於摘要,但細節有時混淆;在 ROUGE 指標上僅勉強優於隨機選擇的 3 個句子。 |
| 翻譯 | 測試翻譯能力。 | 使用英語=法語句子進行翻譯。 | 英法測試集上獲得 5 BLEU;法英測試集上獲得 11.5 BLEU,低於最佳無監督方法的 33.5 BLEU。 |
| 問答 | 測試為事實性問題產生正確答案的頻率。 | 植入範例問題答案對,評估回答準確性。 | 正確回答了 4.1% 的問題,比基線多 5.3 倍;在最有信心的 1% 問題上的準確度為 63.1%。 |
結論
本研究旨在探索無監督任務學習在自然語言處理(NLP)中的應用和潛力,特別是利用 GPT-2 模型在無需監督適應或修改的情況下直接執行各種 NLP 任務的能力。
GPT-2 告訴我們:當大型語言模型在足夠大且多樣化的資料集上進行訓練時,它們能夠在許多領域和資料集上表現良好,並且能夠在不需要顯式監督的情況下執行大量任務。
這些發現為未來 NLP 任務中的無監督學習和模型改進提供了新的視角和可能性。