[17.04] EAST

日出東方
EAST: An Efficient and Accurate Scene Text Detector
在全卷積網路 FCN 開始流行後,密集預測的方式解決了文字尺寸變化劇烈的問題。接著,多尺度特徵融合概念也正式走進人們的視野。U-Net 論文提出將不同層次的特徵進行拼接融合,提高了物體檢測的準確率。
既然解題的工具有了,研究者們肯定是要找個地方來用用看。
文字檢測領域也理所當然地跟上了這個潮流。
定義問題
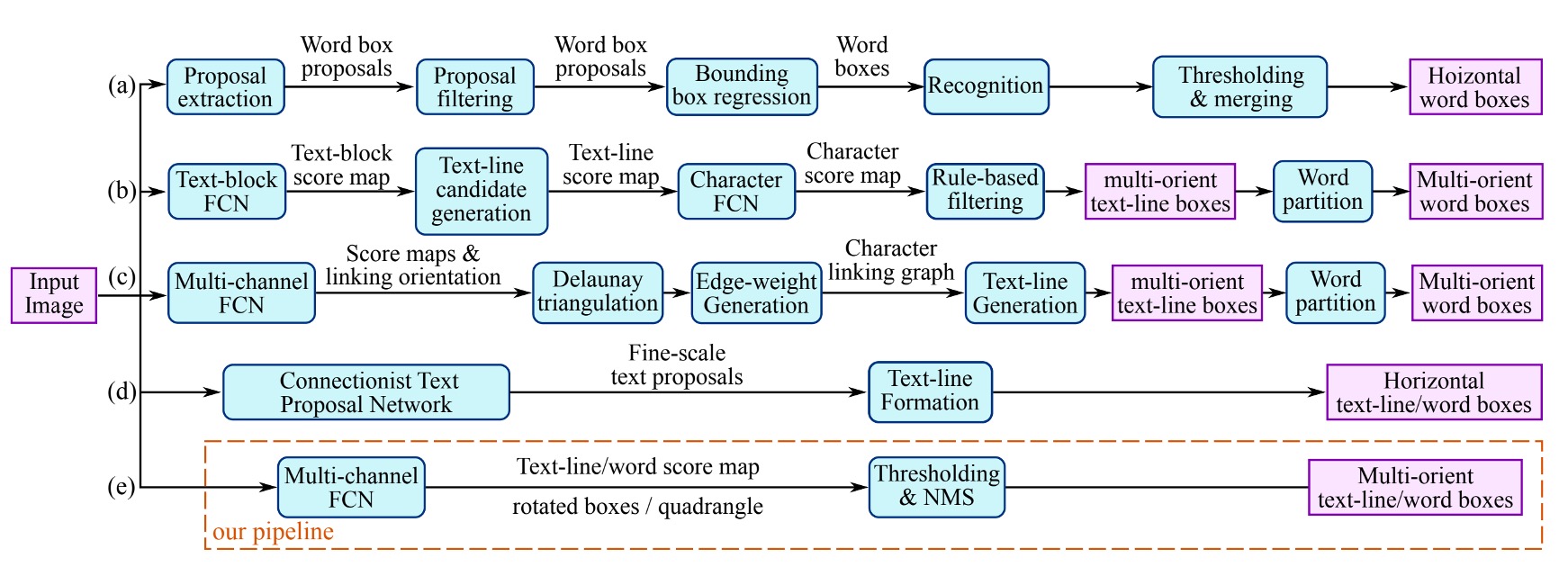
作者整理了過去文獻所使用的文字檢測的方法,如上圖。
大多數的方法必須經過兩個以上的步驟,像是文字區域特徵計算、方向計算、區域合併等。又或是依賴手動設計的特徵,基於筆畫寬度和最大穩定極值區域之類的方法。
但不只是你不喜歡,作者也不喜歡這些方法。因為這些方法需要太多步驟了!不好用啊!
作者的目標就是希望能夠提出一個簡單且高效的方法。
解決問題
由於文字區域的大小變化很大,確定大區域文字的存在需要神經網路後期的特徵,而預測包含小區域文字的精確幾何形狀需要早期的低階資訊,因此模型需要融合多尺度的特徵。
模型架構
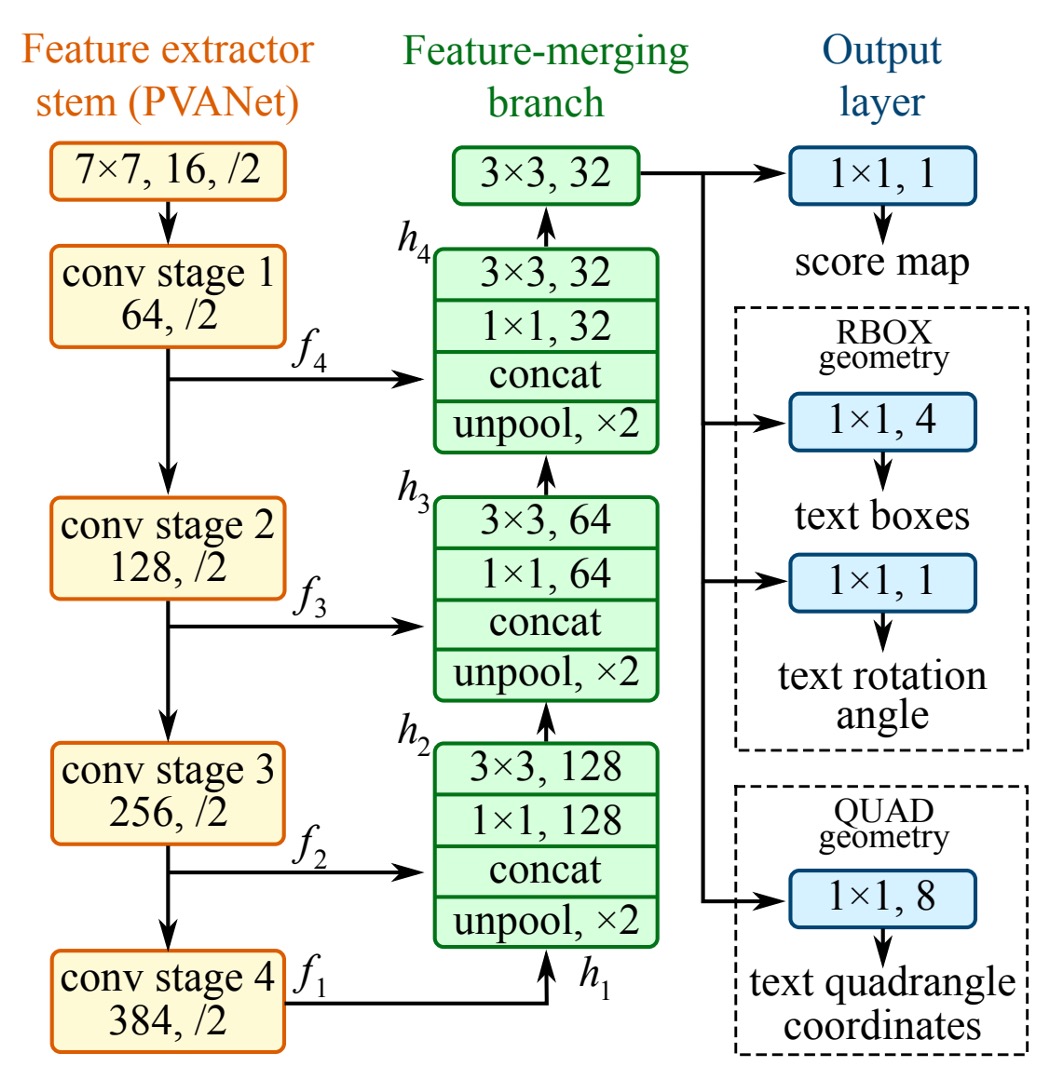
在上圖架構中,最左邊的黃色區塊,就是我們熟知的 Backbone 網路,可以隨意替換。在論文中,作者使用 VGG16 作為 Backbone 網路。
綠色區塊是特徵金字塔網路,作者使用了 U-Net 作為特徵金字塔網路,但沒有使用原始的 U-Net 結構,而是對其進行了一些修改。
這裡我們不再贅述 U-Net 的細節,有興趣的讀者可以參考:
最後是檢測頭的設計。
作者使用 U-Net 網路所輸出的「最大解析度」的特徵圖進行預測,分成三個部分:
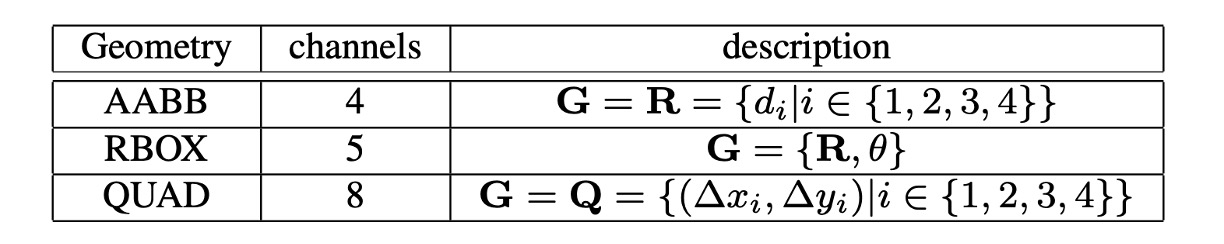
- RBOX:由 4 個軸對齊邊界框和 1 個旋轉角度組成,共輸出 5 個通道。其中 4 個通道分別代表像素位置到矩形的上、下、左、右四個邊的距離。
- QUAD:由 4 個點組成,共輸出 8 個通道,表示四邊形的四個角頂點到像素位置的座標偏移,因為必須區分 和 ,所以共輸出 8 個通道。
- SCORE:輸出文字的分數,用來判斷是否為文字區域,共輸出 1 個通道。
輸出概念圖如下:
標籤生成
-
四邊形的分數圖生成
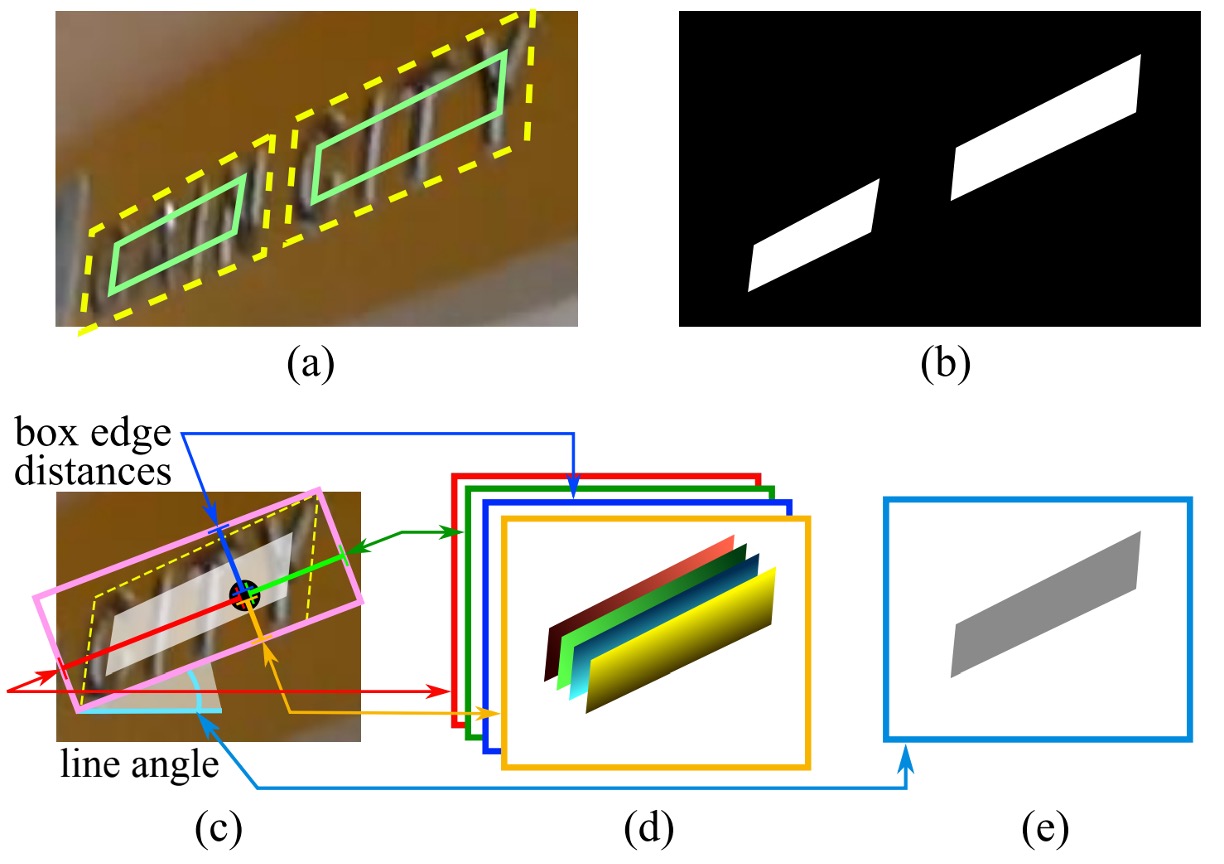
當幾何形狀為四邊形時的情況,分數圖中的四邊形正區域設計為原四邊形的縮小版本,如上圖 (a) 所示。對於一個四邊形 ,其中 是按順時針順序排列的頂點。
縮小四邊形的步驟如下:
-
首先計算每個頂點 的參考長度 ,公式為:
其中 是頂點之間的 L2 距離。
-
先縮短四邊形的兩條較長的邊,再縮短較短的邊。
-
對於兩對相對的邊,通過比較它們長度的均值來判斷哪一對為「較長」。
-
每條邊 與 的縮小方式是將兩端點沿邊內縮,分別移動 和 。
-
-
幾何圖生成
幾何圖可以是 RBOX 或 QUAD。RBOX 的生成過程如上圖 (c-e) 所示。
對於那些以四邊形 (QUAD) 樣式標註的數據集(例如 ICDAR 2015),作者首先生成一個最小面積的旋轉矩形來覆蓋該區域。對於每個有正分數的像素,則是計算其到文本框四個邊界的距離,並將其放入 RBOX 的 4 個通道中。
另外一種對於 QUAD 的 Mask 標籤則是對每個有正分數的像素,其在 8 通道幾何圖中的值是該像素到四邊形 4 個頂點的座標偏移量。
損失函數
總損失函數可以表示為:
其中, 表示分數圖的損失, 表示幾何圖的損失, 用來平衡兩者的權重。
在實驗中,設置 。
-
分數圖的損失
許多先進的檢測方法使用平衡抽樣和難負樣本挖掘來解決目標物不均衡的分佈問題,這些技術雖能提升效能,但會增加非微分過程和調參負擔。為了簡化訓練過程,作者使用了類別平衡交叉熵:
其中, 是預測的分數圖, 是真實標籤, 是正負樣本的平衡因子:
這種平衡交叉熵首次由 Yao 等人用於文本檢測,實際應用效果不錯。
-
RBOX 損失
文本檢測的一個挑戰在於自然場景中文本尺寸的差異很大,直接使用 或 損失會使大文本區域的損失偏大。為了確保對大小文本區域都有準確的幾何預測,損失函數應該具備尺度不變性。
因此,對於 RBOX 的 AABB 部分,作者採用 IoU 損失;
其中, 是預測的 AABB 幾何, 是真實值。
旋轉角度的損失為:
幾何圖的總損失為 AABB 和角度損失的加權總和:
其中, 在實驗中設置為 10。
-
QUAD 損失
對於 QUAD,作者基於 Smooth L1 損失,並加入一個針對單詞四邊形的正規化項,其通常在一個方向上較長。
所有四邊形座標的有序集合表示為:
損失函數表示為:
其中,正規化項 是四邊形最短邊的長度:
表示所有可能的頂點排列,因為公開數據集中四邊形的標註順序並不一致。
訓練策略
網路使用 ADAM 優化器進行端到端訓練。為了加速學習,從影像中均勻抽取 512x512 的裁切區域來組成每批次大小為 24 的小批次。ADAM 的學習率從 開始,每 27300 個小批次衰減為原來的十分之一,直到 為止。
訓練過程持續進行,直到性能不再提升。
是個不管不顧 Train 到底的策略。
局部感知的 NMS
在進行閾值篩選後,保留下來的幾何形狀需要透過 NMS 合併。
傳統的 NMS 演算法的時間複雜度是 ,其中 是候選幾何數量,這在密集預測的情況下是不可接受的,因為在這個情境中,要面對的是成千上萬的幾何形狀。
假設附近像素的幾何形狀通常高度相關,作者提出「按 row 合併」的方式。
對於同一 row 的幾何形狀,迭代地將當前遇到的幾何形狀與上一個已合併的幾何形狀合併。這種改進方法在最佳情況下的運行時間複雜度為 。雖然最壞情況下與傳統的 NMS 相同,但只要局部性假設成立,演算法在實踐中運行速度就能滿足需求。
具體過程如以下:

與傳統 NMS 不同,這裡採用的是「加權平均」幾何形狀,而不是「選擇」幾何形狀,這實際上起到了一種投票機制的作用。然而,為了方便理解作者在這裡仍然使用「NMS」一詞作為功能描述,因為其核心功能仍然是在合併和抑制多餘的幾何形狀。
在函數 WEIGHTEDMERGE(g, p) 中,兩個多邊形 和 的頂點座標會根據它們各自的分數進行加權平均。如果將合併後的多邊形稱為 ,那麼每個頂點的坐標 都由兩個原始多邊形頂點的坐標 和 根據它們的分數進行加權計算,公式如下:
其中:
- 和 分別是多邊形 和 的分數。
- 和 是這兩個多邊形的第 個頂點的坐標。
- 是合併後多邊形 的第 個頂點的坐標。
合併後多邊形 的總分數 則是兩個原始多邊形分數的總和:
基準數據集
為了比較所提出的演算法與現有方法,作者在三個公開基準數據集:ICDAR2015、COCO-Text 和 MSRA-TD500 上進行實驗。
-
ICDAR 2015
ICDAR 2015 是文字檢測中常用的資料集,包含 1500 張圖片,其中 1000 張用於訓練,剩下的用於測試。文字區域由四個頂點的四邊形標註。
-
COCO-Text
當前最大的文本檢測數據集,共包含 63,686 張圖片,其中 43,686 張用於訓練,20,000 張用於測試。文本區域以軸對齊的邊界框(AABB)標註,這是 RBOX 的特例。對於此數據集,角度 被設為 0,並與 ICDAR 2015 相同的數據處理與測試方法。
-
MSRA-TD500
這是一個多語言、任意方向和長文字行的數據集。包含 300 張訓練圖像和 200 張測試圖像,文字行標註為行級標註。由於訓練集較小,實驗中加入了 HUST-TR400 數據集的圖像作為訓練數據。
討論
ICDAR 2015
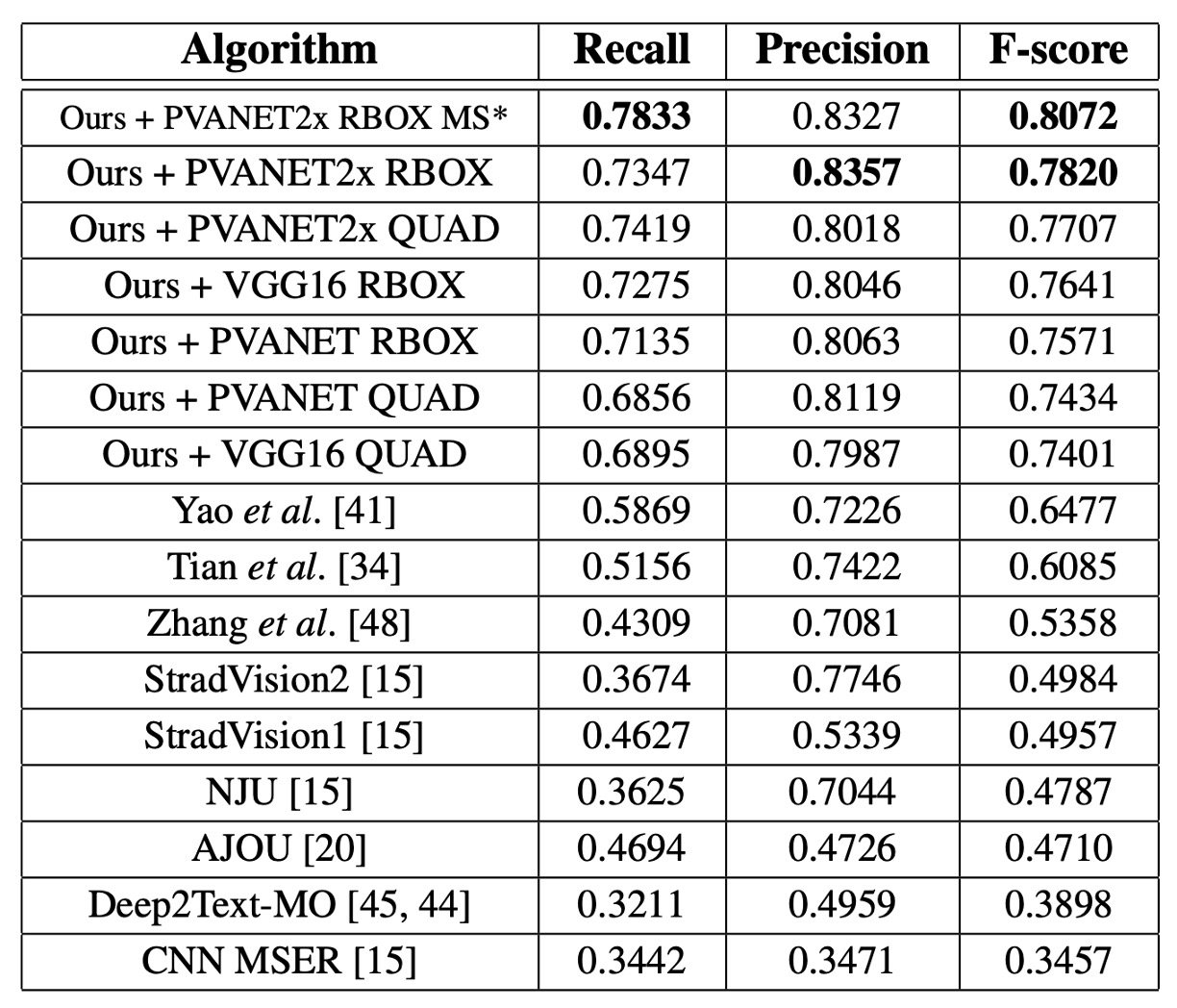
單一尺度下 F-score 為 0.7820,多尺度測試後達到 0.8072,明顯超越過去的最佳方法(0.8072 vs. 0.6477)。使用 QUAD 輸出時,對比文獻[41]中的最佳方法高出 0.0924,使用 RBOX 輸出時高出 0.116。
COCO-Text
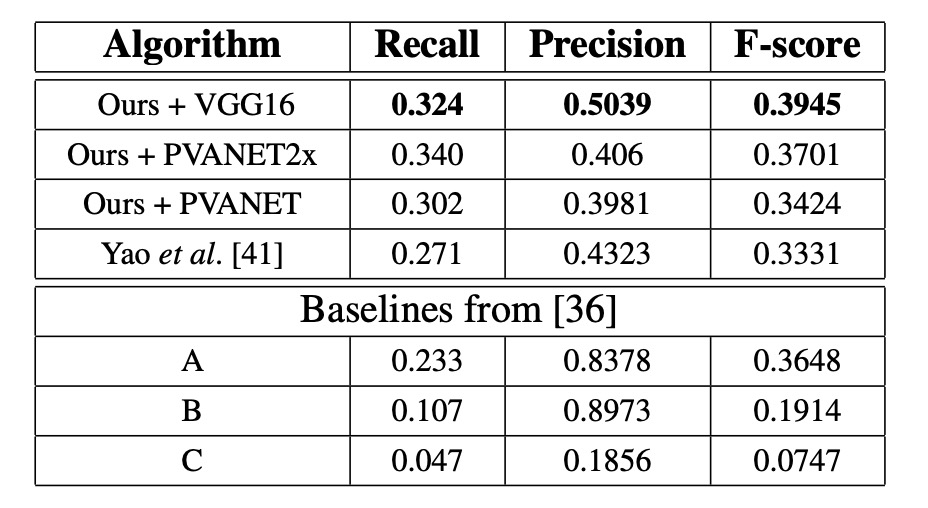
在所有設置中,本論文的方法都是最佳表現,F-score 提升了 0.0614,Recall 提升了 0.053。
MSRA-TD500
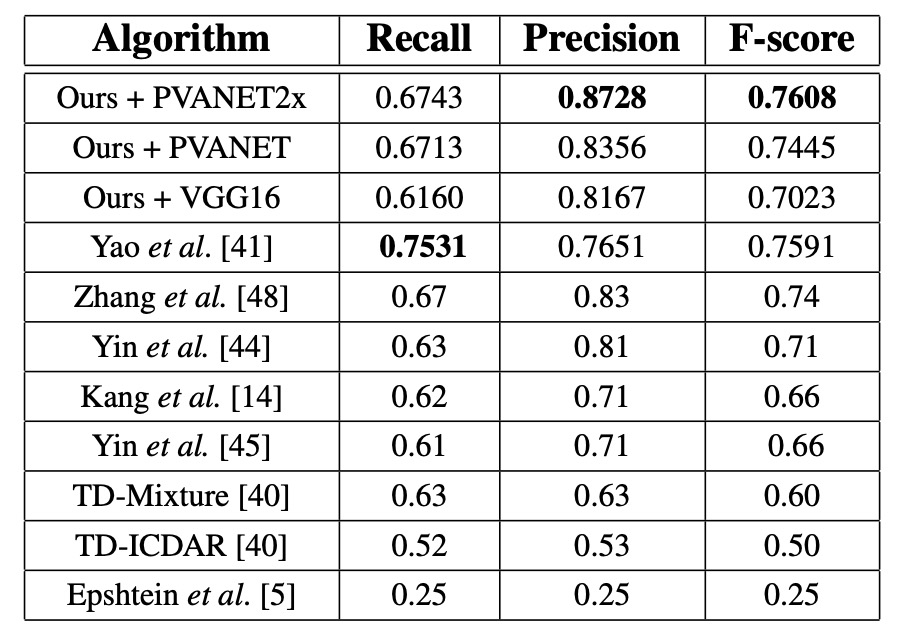
使用 PVANET2x 時,F-score 為 0.7608,比過去最先進的系統高出 0.0208,精度提升 0.0428。VGG16 表現較差(F-score 0.7023 vs. PVANET2x 的 0.7608),因為 MSRA-TD500 的評估要求輸出句子級別的預測,而 VGG16 的感受野較小。
可視化結果

結論
本論文設計了一個簡單且高效的文本檢測框架,通過單一神經網路就能夠完成從整圖到文字區域的檢測,並生成精確的幾何預測。這一方法避免了多步驟的複雜處理流程,使得模型更為輕量且易於實現。
在這篇研究中,對於訓練方式的討論沒有過多著墨,因此我們無法得知這個架構的設計中,哪個組件對於最終的效果起到了關鍵作用。但從實驗結果來看,這個方法在三個基準數據集上都取得了最佳效果,證明了其在文字檢測領域的優越性。