[24.12] DeepSeek-V3

專家的遠眺
眨眼間就來到第三代了。
快速回想一下之前研究團隊都做了些什麼事?
定義問題
第一代,也就是 DeepSeek LLM,沿用了 LLaMA 架構,提出自己的 Scaling Law,經過幾輪暴測,擬合出最優公式。
第二代,也就是 DeepSeek-V2,基於上一代的成果,引入 DeepSeekMoE 架構和多頭潛在注意力機制(MLA),打出了漂亮的結果。
現在當然也要延續過去的成功經驗。
研究團隊在第三代架構中把模型規模再往上加大約一倍,打算做個更大的模型。
不過如果只是單純提升規模,那論文就沒什麼好發的了,必須得再多點什麼才行。
因此,在這篇論文中,研究團隊提出了幾個新的改善方向:
- 調整輔助損失函數策略,讓專家系統更穩定。
- 提供更多預測目標,壓縮每個 token 的資訊密度。
- 引入 FP8 混合精度進行訓練並實現更高效的平行化算法。
和之前類似的部分我們就不再重複,接著來看一下這篇論文提出的改善方向的具體細節。
想知道前幾代模型的技術細節的讀者,可以參考我們之前的筆記:
解決問題
DeepSeek‑V3 整體架構仍然基於 Transformer,但針對訓練成本與推理效率進行了優化,主要體現在 MLA 和 DeepSeekMoE 兩個模組上。
- Multi‑Head Latent Attention (MLA):透過低秩壓縮降低關鍵–值(Key-Value, KV)緩存的記憶體消耗。
- DeepSeekMoE 搭配免輔助損失策略:利用細粒度的專家分支架構,並設計動態調整機制以保持各專家負載均衡,而不需引入額外輔助損失。
其中 MLA 提升推理效率,DeepSeekMoE 則可以降低訓練成本。
這兩個部分我們在 DeepSeek‑V2 就看過了,以下略過不提。
這次來看一下免輔助損失策略。
還記得在 DeepSeek‑V2 中,作者使用一大篇幅的章節來說明「輔助損失策略」,因為傳統 MoE 模型常透過輔助損失來避免路由失衡(routing collapse),但過大的輔助損失會損害模型性能,來回調整靠的也是經驗。
時隔半年,在這篇論文中,研究團隊告訴我們說:「這個東西,我們不要了!」
免輔助損失策略
原文為 Auxiliary‑Loss‑Free Load Balancing。
免輔助損失策略的做法是 為每個專家增加一個偏置項 ,並將其加到對應的親和力(affinity)分數上,用於決定 Top‑ 路由:
要注意到這個偏置項僅用於路由決策,計算門控值時仍以原始 為依據。
每個訓練步驟結束時,根據各專家的負載狀況:若某專家過載,則將其 減少 ;若不足,則增加 (其中 為偏置更新速度的超參數)。
如此一來,可以在不引入額外輔助損失的情況下保持負載均衡,從而避免過大輔助損失對模型性能的負面影響。
為防止單一序列內極端不平衡,研究團隊還引入了序列級輔助損失:
其中:
- 為序列中 token 的數量,
- 為指示函數,
- 是一個極小的超參數。 此損失用於進一步鼓勵每個序列內的專家路由分佈保持平衡。
為了降低跨節點通信成本,系統限制每個 token 最多只被路由到 個節點(根據每個節點上最高 的 affinity 分數決定)。
最後由於負載均衡策略有效,DeepSeek‑V3 在訓練與推理時均無需丟棄任何 token。
傳統方法:透過專家層級、裝置層級及通信平衡損失來鼓勵各專家間的激活頻率和親和分數保持均衡,但這些損失需要額外的超參數調整。
本論文的方法:在每個訓練步驟結束時,根據各專家的負載狀況,動態地更新偏置項 :如果某個專家過載,就將 減少;如果專家使用不足,則增加 。這樣的調整能夠自動讓路由更均衡,而不需要通過額外損失來「懲罰」不平衡現象。
Multi‑Token Prediction
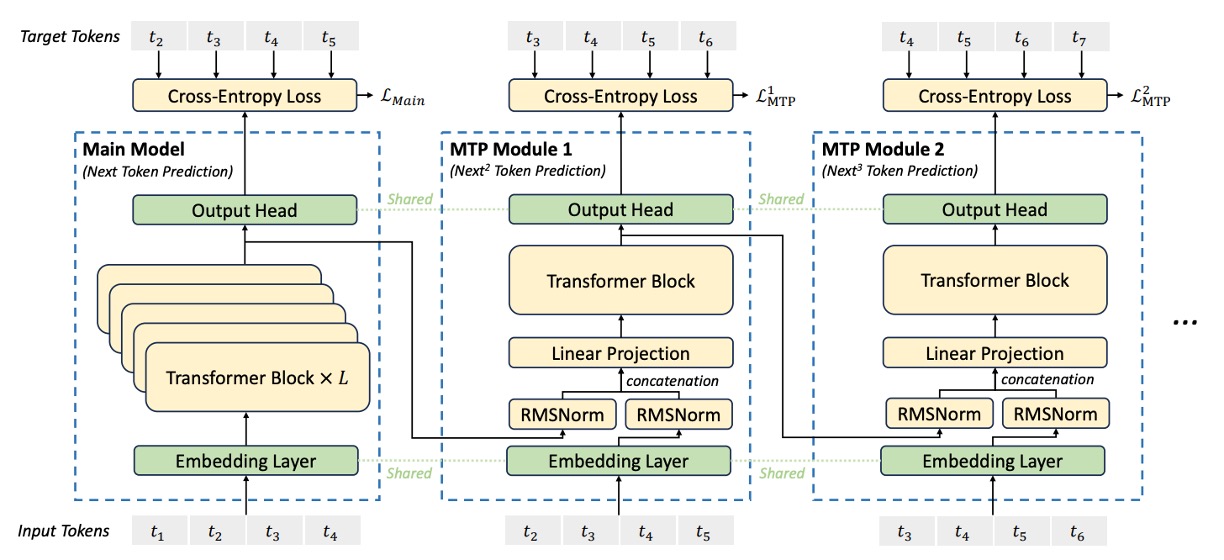
DeepSeek‑V3 引入新的訓練目標,讓模型在每個位置順序預測多個未來 token。
這個策略具有兩個主要優點:
- 訓練信號更密集: 每個位置同時產生多個預測目標,提升了數據利用效率。
- 提前規劃表示: 模型能逐層預測並調整其內部表徵,使得未來 token 的生成更具前瞻性與準確性。
與以往文獻採用並行獨立輸出頭的方法不同,MTP 採用序列化預測方式,保證在每個預測深度上均保持完整的因果鏈。
整個 MTP 目標由 個順序模組構成,每個模組用於預測一個額外 token,且與主模型共享嵌入層和輸出頭。每個 MTP 模組包含以下組件:
-
共享嵌入層 Emb(·): 與主模型共享,用於獲取 token 的嵌入表示。
-
共享輸出頭 OutHead(·): 將 Transformer 模塊的輸出映射到 logits,再經 Softmax 轉換成預測機率。
-
Transformer Block : 在第 個預測深度進一步處理信息。
-
投影矩陣 : 用於將前一層表示與未來 token 的嵌入線性組合,映射回 維空間。
對於第 個輸入 token ,在第 個預測深度中,首先取來自上一層的表示 (當 時, 為主模型輸出),以及 token 的嵌入 ;接著,分別對這兩個向量進行 RMSNorm 正規化後拼接,並利用投影矩陣 進行線性變換:
這一步將來自上一層的表示和未來 token 的信息融合,為第 層預測提供更豐富的輸入特徵。
將上述融合後的表示 輸入專用的 Transformer block ,生成更新後的表示:
這裡 為輸入序列長度,由於每增加一個預測深度,處理範圍縮短 個 token,確保每個預測都有相應的真實標籤可供訓練。
利用共享輸出頭將 Transformer block 輸出表示映射到預測分佈,生成第 個 token 的預測:
此處 為預測概率分佈( 為詞彙表大小),通過線性映射到 logits 再經 Softmax 得到。
為了指導多層次預測,每個預測深度 定義了一個交叉熵損失,對於第 層預測,其損失計算為:
其中 表示第 個 token 的真實標籤,而 是該 token 在第 層的預測概率。損失從 開始計算,以確保每個預測層對應後續的真實 token。
將所有 個預測深度的損失平均後,乘以權重因子 得到總體 MTP 損失:
此總損失作為額外的訓練目標,與主模型損失共同反向傳播,促使模型在生成過程中學習更前瞻性的表示。
MTP 模組主要用於提升訓練時的數據利用率和預測能力,通過多層次損失引導模型提前「規劃」未來 token。
在推理階段可選擇捨棄 MTP 模組,使主模型獨立運作。也可以重新利用 MTP 模組進行 speculative decoding,以降低生成延遲。
在論文中有比較多的數學描述,如果你和 Transformer 不太熟,看起來可能會比較費神。
實際上這沒有脫離我們使用文字接龍來訓練模型的概念。
舉個例子,如果我們原本給模型的出題方式是:
給你這句話:「我今天吃了__。」
你只要填上「晚餐」這一個答案就好。
這樣的訓練方式,每次只讓模型練習「預測下一個詞」,就像每次考試只考一道題,學習效率有限。
而 DeepSeek-V3 的 Multi‑Token Prediction(MTP),就像換了新的出題方式:
給你同樣的句子:「我今天吃了__。」
現在要你連續預測接下來的三個詞:「晚餐」、「很好吃」、「但太撐了」。
這裡不是一次預測三個詞,而是 第一層預測第一個詞,第二層預測第二個詞,第三層預測第三個詞,每一層都會考慮前一層的答案,逐層修正、逐層規劃。
這樣的訓練方式有兩大好處:
- 更多題目可以練: 一句話中,每個詞都可以觸發一連串的預測任務,等於讓模型在同一段文本中練習了多次。
- 能學會規劃: 模型不只是看當下詞怎麼接,還會考慮後面幾個詞要怎麼走,讓它的內部思考更像「腦中排好一整串句子」而非只看一步。
這樣做,模型在訓練階段就學會了如何「提前規劃和修正」,而不是等到生成出錯才後悔。對生成品質和效率都有實質幫助。
Infrastructures
本章節在論文中有大量的篇幅,主要教你怎麼搭建訓練環境各項軟硬體設施。不過我們閱讀論文的重點還是偏向軟體層面,所以這裡簡單帶過這一章節,如果你手邊剛好有一點錢(可能 1 億美金?)可以搭建這個環境的話,請直接去閱讀原始論文。
DeepSeek‑V3 能夠成功訓練,離不開先進的硬體平台和高效的訓練框架。
本章節將從計算集群、訓練框架、低精度 FP8 訓練、推理部署以及未來硬體設計建議五個部分展開介紹:
-
計算集群:
DeepSeek‑V3 的訓練平台依托於一個超大規模的 GPU 集群:
-
硬體規模: 集群中共配置 2048 顆 NVIDIA H800 GPU,每個節點配備 8 顆 GPU。
-
內部互聯: 節點內部的 GPU 通過 NVLink 和 NVSwitch 進行高速連接,確保內部數據交換延遲極低。
-
跨節點通信: 節點間則使用 InfiniBand (IB) 互聯,該技術提供了高帶寬與低延遲的特性,使得在大規模並行計算環境下,各節點之間能夠實時共享數據。
-
-
訓練框架:
為了充分利用這樣的硬體資源,研究團隊採用了自主研發的 HAI-LLM 訓練框架。該框架融合了多種先進的並行策略,具體包括:
- 流水線並行(Pipeline Parallelism, PP): 模型被分解為多個階段,並通過 16 路流水線並行運行。為了彌補流水線中的空泡(pipeline bubbles),團隊提出了創新的 DualPipe 算法,使前向與反向運算中的計算與通信實現有效重疊。
- 專家並行(Expert Parallelism, EP): 針對 MoE 模型中的專家模塊,DeepSeek‑V3 採用了 64 路甚至更大規模的專家並行,分布在多個節點上,保證每個專家都有足夠的 batch 大小以提升計算效率。
- 數據並行(Data Parallelism, DP): ZeRO-1 技術進一步分散了大規模數據的處理壓力,讓模型參數分佈在不同的計算節點上,有效降低內存負擔。
此外,DualPipe 算法的核心在於將每個計算 chunk 拆分成 attention、all-to-all dispatch、MLP 及 combine 四個部分,並在前向與反向過程中巧妙重疊通信與計算,使得跨節點的通信延遲幾乎被完全隱藏。
-
低精度 FP8 訓練:
在大規模模型訓練中,計算速度與內存占用始終是一對矛盾。研究團隊通過引入 FP8 混合精度訓練技術,有效加速了核心計算:
- 核心思想: 主要計算(例如矩陣乘加 GEMM 操作)在 FP8 下執行,而一些對數值穩定性要求較高的操作則保留在 BF16 或 FP32。這樣既能大幅提升計算速度,又能保證模型訓練的穩定性。
- 細粒度量化策略: 針對 FP8 的動態範圍限制,作者提出 tile-wise(1×128)和 block-wise(128×128)的量化方法,有效應對激活值、權重與梯度中的異常值。
- 累加精度提升: 通過在 Tensor Cores 上有限累加與 CUDA Cores 上的 FP32 累加結合,有效解決了 FP8 GEMM 累加精度不足的問題,使得相對損失誤差始終控制在 0.25% 以下。
- 低精度存儲與通信: 為進一步降低內存和通信開銷,激活和優化器狀態也以低精度格式進行存儲與傳輸,這對於大規模 MoE 模型的訓練尤為關鍵。
這一套混合精度方案在理論上可提升近 2 倍的計算速度,同時大幅減少內存占用,使得大規模模型訓練變得更加經濟高效。
-
推理與部署策略:
DeepSeek‑V3 的推理部署同樣依托於高效的硬體環境,並根據不同需求將流程分為兩個階段:
- Prefilling 階段:
- 部署單位:最小部署單位為 4 個節點(32 顆 GPU)。
- 在該階段,Attention 部分採用 4 路 TP 結合 Sequence Parallelism 與 8 路 DP;MoE 部分則利用 32 路 EP。
- 為平衡各 GPU 的負載,採用冗餘專家機制,每個 GPU 除原有專家外還額外部署冗餘專家;同時,通過微批次重疊策略隱藏通信延遲,提高吞吐量。
- Decoding 階段:
- 部署單位:最小部署單位為 40 個節點(320 顆 GPU)。
- 這一階段重點在於實現低延遲在線推理,Attention 部分與 MoE 部分分別採用 TP4、SP、DP80 及 EP320;冗餘專家部署和點對點 IB 通信(結合 IBGDA 技術)共同確保了推理過程的高效性。
這兩個階段的分工與優化,使得系統在保持高吞吐量的同時,也能滿足嚴格的在線服務延遲要求。
- Prefilling 階段:
-
未來硬體設計建議:
基於 DeepSeek‑V3 的實踐經驗,研究團隊向硬體供應商提出了以下改進建議:
- 通信硬體:
- 建議未來開發專門的通信協處理器,將部分通信任務從 SM 卸載,並統一 IB 與 NVLink 的接口,從而釋放計算資源並降低通信延遲。
- 計算硬體:
- 提升 FP8 GEMM 的累加精度,避免目前 Tensor Cores 中 14 位累加精度帶來的誤差。
- 原生支持細粒度量化(tile-/block-wise 量化),使 Tensor Cores 能直接處理縮放因子,從而減少 Tensor Cores 與 CUDA Cores 之間的數據搬移。
- 融合 FP8 cast 與 TMA 訪問,實現 online quantization,從而進一步降低內存讀寫次數。
- 支持直接轉置 GEMM 操作,以簡化反向傳播中對激活值進行去量化和轉置的流程。
- 通信硬體:
預訓練
DeepSeek‑V3 在預訓練階段不僅進一步擴大了訓練數據規模,還在數據構建、損失策略、超參數設置和長上下文處理上做出了多項創新。
我們依序來看看:
-
數據構建
-
語料優化: 與 DeepSeek‑V2 相比,DeepSeek‑V3 在預訓練語料中增加了數學與程式設計樣本的比例,同時擴展了多語種覆蓋,超越了僅僅依賴英語和中文的限制。
-
數據處理流水線: 改進了數據處理流程,既最大限度地減少了冗餘,又保證了語料的多樣性。
-
文件打包與 FIM 策略: 參考過去的文獻方法,使用文件打包保持數據完整性,但不進行跨樣本注意力屏蔽;同時引入 Fill-in-Middle (FIM) 策略,具體通過 Prefix-Suffix-Middle (PSM) 框架結構化數據,形如:
<|fim_begin|> fpre <|fim_hole|> fsuf <|fim_end|> fmiddle <|eos_token|>FIM 策略以 0.1 的比例應用於整體語料,幫助模型學習中間文本的預測,從而提升整體生成能力。
-
Tokenizer 優化: 使用 Byte-level BPE 並擴展到 128K 詞彙,針對多語種進行優化,並加入了標點與換行符結合的 token;為解決 token 邊界偏差,隨機拆分部分結合 token,使模型能處理更多特殊情況。
-
-
超參數設置
-
模型結構:
- Transformer 層數設為 61 層,隱藏維度 7168,參數標準差初始化為 0.006。
- MLA 中注意力頭數為 128,每頭維度 128,KV 壓縮維度設為 512,查詢壓縮維度為 1536,RoPE 的每頭維度為 64。
- 除前三層 FFN 外,其餘層替換為 MoE 層:每個 MoE 層包含 1 個共享專家和 256 個路由專家,每個專家的中間維度為 2048,激活 8 個路由專家,每個 token 最多分配到 4 個節點。
- 多 token 預測深度 設為 1,即每個 token 除預測下一個詞外再預測一個額外 token。
-
訓練參數:
- 使用 AdamW 優化器,超參數設定為 ,,weight_decay=0.1。
- 預訓練最大序列長度為 4K,總語料達 14.8T token。
- 學習率採取階段性調度:起始 2K 步內線性增至 ,接著保持常數直到 10T token,然後按照 cosine 曲線逐漸衰減至 ,最後進入細調階段。
- 批次大小隨訓練進程逐步增加,初期由 3072 增至 15360,後續保持不變。
- 針對 MoE 的負載均衡,設定偏置更新速度 及序列級平衡損失超參數 等,確保每個 token 最多路由到 4 個節點。
整體配置下,DeepSeek‑V3 總參數達 671B,其中每個 token 激活 37B 參數。
-
-
長上下文擴展
在預訓練結束後,借鑒 DeepSeek‑V2 的方法,通過 YaRN 進行兩個階段的上下文擴展:第一階段將序列長度從 4K 擴展到 32K,第二階段進一步擴展到 128K;在這兩個階段中,批次大小和學習率均進行了相應調整以適應長上下文的計算需求。
擴展後的模型在如「Needle In A Haystack」(NIAH)等測試上顯示出顯著的長上下文處理能力,證明模型在處理長文本時仍能保持穩定且優異的性能。
後訓練
在完成預訓練後,研究團隊通過後續的微調與強化學習階段進一步提升模型對人類偏好的對齊能力和生成品質。
這一階段主要包括監督微調(Supervised Fine-Tuning, SFT)與強化學習(Reinforcement Learning, RL),同時輔以詳細的評估,確保最終模型能夠在多領域下表現優異。
這種模型「預訓練-對齊」的方法已經成為目前主流 LLM 產出的標準流程。
監督微調(SFT)
在 SFT 階段,團隊精心構建了涵蓋 1.5M 個樣本的指令調整數據集,數據涵蓋多個領域,每個領域採用了針對性的數據生成方法:
-
推理數據: 為了提升模型在數學、編程競賽及邏輯推理方面的能力,利用內部的 DeepSeek-R1 模型生成推理數據。然而,直接生成的數據可能存在「過度思考」或格式冗長等問題,因此採取了雙重數據生成策略:
- 第一種格式為:
<problem, original response>,保留原始回答; - 第二種格式則加入了系統提示(system prompt),格式為:
<system prompt, problem, R1 response>,提示中包含引導模型進行反思與驗證的指令。
接著,利用專家模型(先通過 SFT 與 RL 訓練得到)生成最終 SFT 數據,並採用拒絕抽樣來篩選高品質樣本。
- 第一種格式為:
-
非推理數據: 對於創意寫作、角色扮演、簡單問答等非推理任務,則利用 DeepSeek-V2.5 生成答案,再由人工校驗其正確性,確保數據品質。
-
SFT 訓練設置: 微調過程中,DeepSeek‑V3‑Base 微調兩個 epoch,學習率採用 cosine decay,從 衰減至 ;同時在單個序列中對多個樣本進行打包,但使用 sample masking 策略來避免樣本間的互相干擾。
強化學習(RL)
強化學習部分旨在進一步對齊模型輸出與人類偏好,主要通過兩種獎勵模型和一個群組相對策略優化算法實現:
-
獎勵模型(Reward Model, RM): 研究團隊採用了兩種獎勵模型:
- 基於規則的 RM: 針對數學或 LeetCode 這類有明確答案的任務,根據特定格式(例如答案框中顯示)或通過編譯器驗證測試用例給出獎勵。
- 基於模型的 RM: 對於無明確正確答案的任務(如創意寫作),RM 根據輸入問題及生成回答,並結合 chain-of-thought 信息進行評價,這樣可降低獎勵作弊的風險。
-
群組相對策略優化(Group Relative Policy Optimization, GRPO):
為了更新策略模型,GRPO 不再使用傳統的 critic 模型,而是從舊策略生成的輸出群組中計算優勢,並根據這些優勢更新當前策略。
該方法使得策略更新更穩定,同時能充分利用多樣化的生成結果。
公式上,GRPO 目標函數中涉及對每個輸出 的比例調整與 clip 操作,以保證更新過程不會偏離舊策略太遠,並引入 KL 散度懲罰來維持一定的約束。
-
RL 整體流程: 在 RL 過程中,團隊使用來自不同領域(編程、數學、寫作、角色扮演等)的提示,讓模型產生多樣化輸出,進而通過 RM 提供獎勵。這個過程不僅使模型學會融合 R1 模型的生成模式,還能更好地滿足人類偏好,最終在有限的 SFT 數據上顯著提升性能。
討論
各類比較表格眾多,有興趣的讀者可以翻閱原始論文,我們挑重點圖表來看。
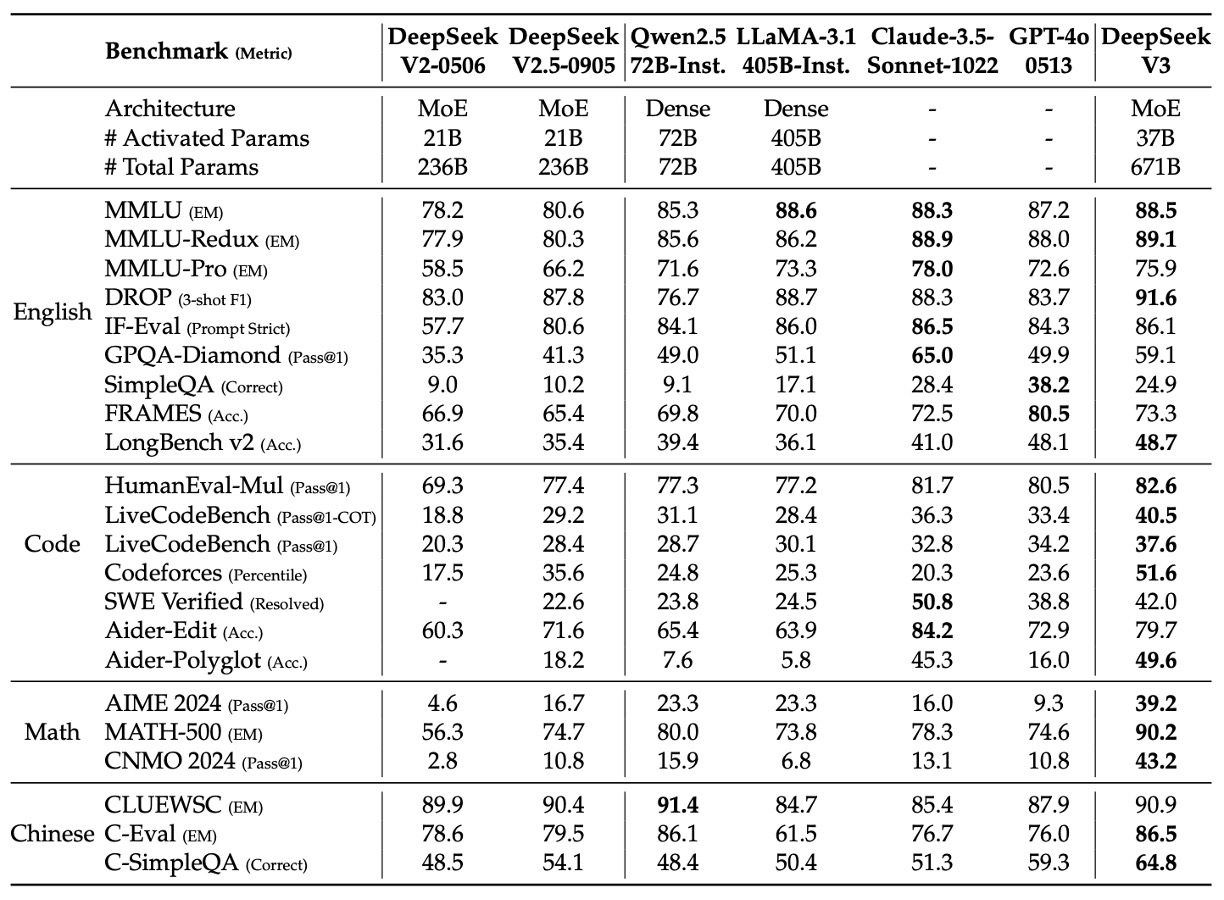
上表的數據展示了多個標準基準下各模型的表現,從中我們可以清楚看到 DeepSeek‑V3 與 GPT‑4o 相比具有以下幾個顯著優勢:
-
英語知識與長上下文能力:
- 在 MMLU 和 MMLU‑Redux 上,DeepSeek‑V3 表現與 GPT‑4o 基本持平或略有優勢。
- 在 DROP(3-shot F1)和 LongBench v2 等長上下文測試中,DeepSeek‑V3 的分數分別達到 91.6 與 48.7,而 GPT‑4o 僅為 83.7 和 48.1,顯示其在處理長文檔時具有更強的能力。
-
程式碼生成與編程能力:
- 在 HumanEval‑Mul、LiveCodeBench 和 Codeforces 指標中,DeepSeek‑V3 分別獲得 82.6、40.5 和 51.6,遠超 GPT‑4o(分別為 80.5、36.3 和 23.6)。特別是 Codeforces 的百分位數上,DeepSeek‑V3 具有顯著優勢,表明其在解決編程算法問題時更具競爭力。
-
數學推理能力:
- 在 AIME 2024、MATH‑500 和 CNMO 2024 上,DeepSeek‑V3 的表現遠超 GPT‑4o。例如,在 AIME 2024 中,DeepSeek‑V3 達到 39.2(Pass@1)而 GPT‑4o 僅為 9.3;在 MATH‑500 上,DeepSeek‑V3 取得 90.2 EM,而 GPT‑4o 僅為 74.6。這表明 DeepSeek‑V3 在複雜數學推理任務上有明顯優勢。
-
中文能力:
- 在中文標準測試上(例如 CLUEWSC、C-Eval 和 C-SimpleQA),DeepSeek‑V3 分別達到 90.9、86.5 和 64.8,而 GPT‑4o 的表現分別為 87.9、76.0 和 59.3。這意味著在中文知識和推理任務中,DeepSeek‑V3 表現更出色。
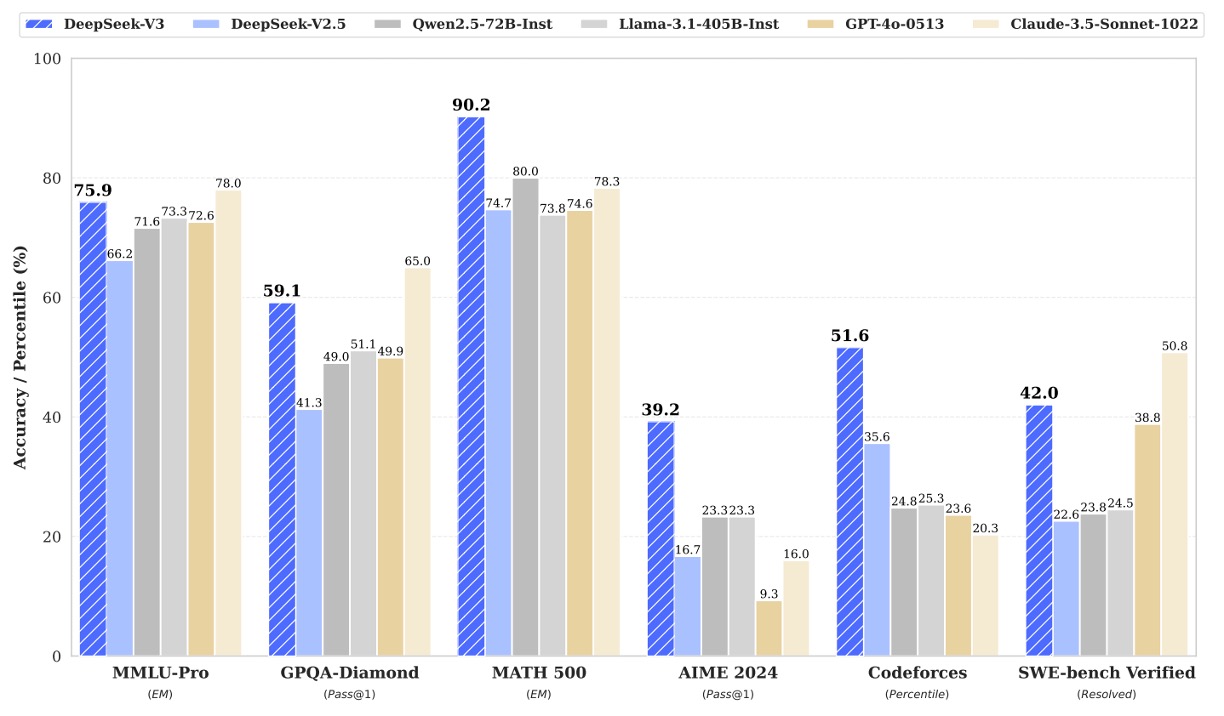
綜合上述各項結果,DeepSeek‑V3 不僅在作為最佳開源模型中領先,且在多個關鍵任務上與 GPT‑4o 等最前沿閉源模型展現了競爭力,尤其是在程式碼生成、數學推理和中文理解等領域,其優勢尤為明顯,下圖展示各個重要領先的評估數值:
結論
最後我們來複習一下 DeepSeek‑V3 的關鍵參數。
其總參數達 671B,但每次僅激活 37B 參數,並且在 14.8T tokens 上進行訓練。
除了繼承上一代的 MLA 與 DeepSeekMoE 架構外,本代模型更引入了兩項創新技術:
- 免輔助損失策略:從根本上解決了傳統 MoE 模型中輔助損失帶來的副作用,使專家負載更加穩定和高效。
- 多 Token 預測策略(MTP):通過同時預測多個未來 token,有效增強了訓練信號和預測規劃能力。
這些技術革新使 DeepSeek‑V3 在各項評測基準上達到了與頂尖閉源模型(如 GPT‑4o 和 Claude‑3.5-Sonnet)相當甚至超越的表現,同時保持了極具競爭力的訓練成本(全程僅耗費 2.788M H800 GPU 小時)。
DeepSeek‑V3 不僅體現了在硬體、數據與算法層面追求高效平衡的探索,也為未來大規模模型的進一步發展指明了方向:
- 要準!還要便宜。