[12.09] AlexNet

卷積網路的崛起
ImageNet Classification with Deep Convolutional Neural Networks
神經網路的研究在更久以前就開始了。
而 AlexNet 是一個重要的里程碑,它在 2012 年的 ImageNet 挑戰賽上取得了驚人的成績。
定義問題
這個時候,卷積網路的應用已經初見端倪。
在此之前,LeNet-5 成功地利用卷積神經網路(CNN)來處理手寫數字辨識問題。
除此之外,這個架構也已經開始應用在一些小規模的資料集上,像是 CIFAR-10、MNIST 等。
與傳統的前饋神經網路相比(全連接神經網路),卷積神經網路受益於其架構的歸納偏差,對於圖像資料來說,具有強大的學習能力,其結構能夠有效地捕捉影像中的空間依賴性和統計平穩性,而且參數量要少得多,因此更容易訓練。
儘管 CNN 具有吸引人的特性,但是高解析度影像上的大規模應用仍然非常昂貴。
就這麼剛好,NVIDIA 也在那個現場,現代的 GPU(當年是 GTX580-3GB)與高度優化的 2D 卷積實現結合,提供了足夠的計算能力,支持大型 CNN 的訓練。
最後,大規模資料集的問題也得到了解決。
在 2009 年提出的大規模影像資料集: ImageNet,提供了足夠的標記範例,能夠有效地訓練這些模型而不會嚴重過度擬合。
*
演算法有了、資料有了、計算能力也有了。
那接著的問題就是:如何設計一個更深、更大的 CNN 來改進影像辨識的性能?
解決問題
模型架構
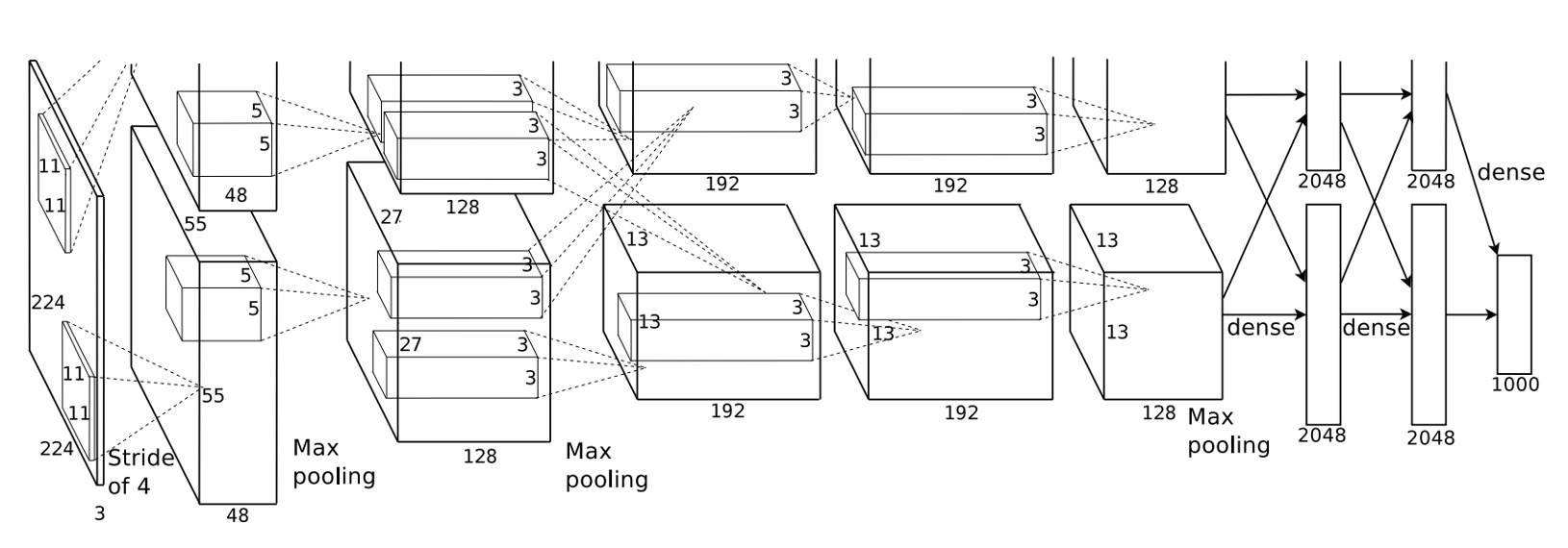
AlexNet 使用深度卷積神經網路,它有 5 層卷積層和 3 層全連接層。
這個架構一直延續很久的以後,後續關於卷積神經網路的研究大多都是在這個基礎上演化過去的。
這個時候的卷積神經網路的範式還沒有確立,像是我們所熟悉的五層降採樣,Batch Normalization 等,此時都沒有。
ReLU 啟動函數
在過去的研究中,使用 ReLU 啟動函數取代了 Sigmoid 和 tanh 函數,收斂速度更快,並且可以避免梯度消失的問題。
其公式為:。
意思是:當輸入大於 0 時,輸出等於輸入;當輸入小於 0 時,輸出等於 0。
多 GPU 訓練
不要再問為什麼 AlenNet 的模型架構圖裁切不完整了!
因為原始論文上的圖就是這樣。
作者在這裡只是想表示:他們把模型拆成兩半,分別放在兩個 GPU 上。
Local Response Normalization
那個時候還沒有 Batch Normalization,但是模型還是需要正規化,不然會很難訓練。
LRN 的基本思想是通過對每個神經元的啟動值進行標準化,使其受周圍神經元啟動值的影響,從而抑制那些過於活躍的神經元,促進不同神經元之間的競爭。
這類似於生物神經元中的側抑制機制,能夠防止某些神經元過於活躍而其他神經元始終不啟動的情況。
在 AlexNet 中,LRN 被定義如下:
給定一個神經元在位置 處的啟動值 ,這是通過應用第 個卷積核並經過 ReLU 非線性變換得到的。
經過 LRN 後,標準化後的啟動值 的計算公式為:
這裡的符號解釋如下:
- :應用第 個卷積核在位置 的輸出啟動值,經過 ReLU 非線性變換後的結果。
- :經過 LRN 後的標準化啟動值。
- 、、 和 :LRN 的超參數,這些參數的值通過驗證集調整得到。
- :該層中總的卷積核數量。
- :遍歷相鄰的卷積核索引,範圍是 。
重疊最大池化
在 AlexNet 中,最大池化層的尺寸為 3x3,步長為 2。
這個操作可以讓特徵圖的尺寸減半,降低計算量。
作者表示:設計成帶有重疊區域的最大池化可以降低過擬合,提高模型的泛化能力。
Dropout
在訓練過程中,作者發現模型容易過擬合,為了解決這個問題,他們引入了 Dropout 技術。
Dropout 在每一個訓練迭代中,隨機地丟棄(即將輸出設為零)神經網路中的一些神經元。
這意味著在每一次前向傳播過程中,網路會以某種隨機的子集結構進行計算。
被丟棄的神經元不會對前向傳播做出貢獻,也不參與反向傳播。
這樣,神經網路就不會依賴於特定神經元的存在來進行學習,從而減少了神經元之間複雜的共同適應現象。
推論時,Dropout 會被關閉,所有神經元都會參與計算。
模型實作
我們接著來詳細看一下整個網路的組成:
- 輸入 224x224 的圖片。
- 第一層卷積核大小為 11x11,步長為 4,輸出 96 個特徵圖,輸出尺寸為 55x55。
- 接著是一個最大池化層。
- 第二層卷積核大小為 5x5,輸出 256 個特徵圖,輸出尺寸為 27x27。
- 再接一個最大池化層。
- 第三層卷積核大小為 3x3,輸出 384 個特徵圖,輸出尺寸為 13x13。
- 第四層卷積核大小為 3x3,輸出 384 個特徵圖,輸出尺寸為 13x13。
- 第五層卷積核大小為 3x3,輸出 256 個特徵圖,輸出尺寸為 13x13。
- 最後是三層全連接層,第一層 4096 個神經元,第二層 4096 個神經元,最後一層 1000 個神經元,對應 ImageNet 的 1000 個類別。
根據論文,有以下幾個重點:
- 在每個卷積層和全連接層後面都有 ReLU 啟動函數。
- 在第一層和第二層卷積後應用了局部正規化(Local Response Normalization)。
- 最大池化曾用在局部正規化和第五個卷積層之後,尺寸為 3x3,步長為 2。
- 在前兩個全連接層之間使用了 Dropout,丟棄率為 0.5。
好,整體資訊已經非常清楚了,我們可以直接寫成模型了:
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.stage1 = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.stage2 = nn.Sequential(
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.stage3 = nn.Sequential(
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU()
)
self.stage4 = nn.Sequential(
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU()
)
self.stage5 = nn.Sequential(
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.stage5(x)
x = self.classifier(x)
return x
討論
卷積網路學到什麼?

作者將第一層卷積核的部分可視化,可以看到這些卷積核學到了一些特徵,比如邊緣、顏色、紋理等。
在過去的研究中,人們通常會手動設計這些特徵,然後將這些特徵提供給機器學習算法。像是我們熟悉的 SIFT、HOG,還有 Sobel 運算子等。
在 AlexNet 之後,我們就不再推崇手動設計特徵,而是該問:怎樣設計才能網路自己學到更好的特徵?
ILSVRC-2010 結果
| Model | Top-1 | Top-5 |
|---|---|---|
| Sparse coding [2] | 47.1% | 28.2% |
| SIFT + FVs [24] | 45.7% | 25.7% |
| CNN | 37.5% | 17.0% |
在 ILSVRC-2010 比賽中,AlexNet 的結果如下:
- Top-1 錯誤率: 37.5%
- Top-5 錯誤率: 17.0%
與當時其他最佳方法的比較:
- Sparse coding 方法的 Top-1 錯誤率為 47.1%,Top-5 錯誤率為 28.2%。
- SIFT + Fisher Vectors (FVs) 方法的 Top-1 錯誤率為 45.7%,Top-5 錯誤率為 25.7%。
這表明 AlexNet 在 ILSVRC-2010 中的表現顯著優於其他方法。
ILSVRC-2012 結果
| Model | Top-1 (val) | Top-5 (val) | Top-5 (test) |
|---|---|---|---|
| SIFT + FVs [7] | — | — | 26.2% |
| 1 CNN | 40.7% | 18.2% | — |
| 5 CNNs | 38.1% | 16.4% | 16.4% |
| 1 CNN* | 39.0% | 16.6% | — |
| 7 CNNs* | 36.7% | 15.4% | 15.3% |
- * 表示這些模型在整個 ImageNet 2011 Fall 釋放版上進行了預訓練。
在 ILSVRC-2012 比賽中,由於測試集標籤不可公開,所有模型的測試錯誤率無法完全報告,但以下是一些關鍵結果:
- 單個 CNN 模型在驗證集上的 Top-5 錯誤率為 18.2%。
- 將五個類似的 CNN 模型的預測進行平均,Top-5 錯誤率下降到 16.4%。
- 將一個包含第六個卷積層的 CNN 模型預先訓練在整個 ImageNet 2011 Fall 釋放版(包含 1500 萬張圖像和 22000 個類別)上,然後在 ILSVRC-2012 上進行微調,Top-5 錯誤率為 16.6%。
- 將兩個預先訓練在 ImageNet 2011 Fall 釋放版上的 CNN 模型與之前的五個 CNN 模型的預測進行平均,Top-5 錯誤率進一步下降到 15.3%。
第二名的參賽方法通過對不同類型的密集採樣特徵計算出的 FVs 進行多個分類器的預測平均,達到了 26.2%的 Top-5 錯誤率。
結論
AlexNet 在 ILSVRC-2012 比賽中取得了驚人的成績,它的出現標誌著深度學習在計算機視覺領域的崛起。
這個網路的設計和訓練方法,對於後來的深度學習發展產生了深遠的影響。