[21.06] BEiT

離散エンコーディングによる事前学習
BEiT: BERT Pre-Training of Image Transformers
この論文の主要な比較対象は ViT と DeiT です。
主に解決しようとしている問題は、ViT アーキテクチャの ImageNet 上での分類性能を向上させる方法です。
問題の定義
私たちは、BERT が過去に MLM による事前学習手法を用いて素晴らしい成果を上げたことをよく知っています。言うなれば、自己符号化モデルの中で最も有用な事前学習方法の一つと言えるでしょう。
しかし、画像領域では、BERT の概念はそれほど使い勝手が良くありません。ViT では、著者はモデルをマスクして、各マスクの「RGB 平均値」を予測することで自己教師あり学習を試みましたが、最終的な結果は期待外れでした。最終的には、監視型学習を用いた事前学習方法が選ばれました。
前人の懸念事項は、後に解決されるべきものです。
この論文の著者は、新しい事前学習方法を提案します:
- おそらく画像のピクセル値を直接予測するのではなく、画像の「離散ラベル」を予測する方法が良いのではないかと。これにより、モデルは画像のピクセル値ではなく、より高次の特徴を学習することができると考えられます。
解決方法
モデルアーキテクチャ
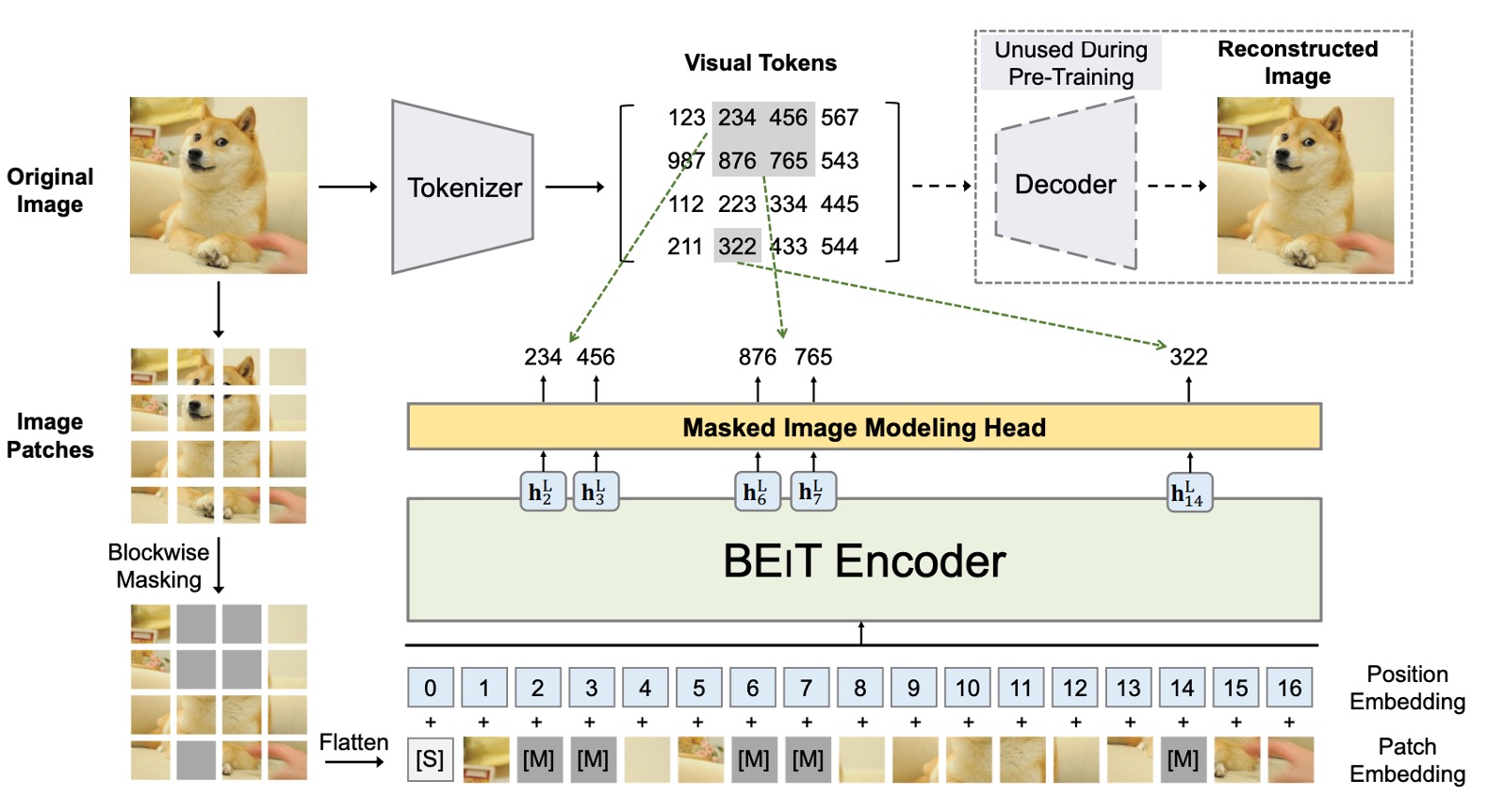
ここでは二つのアーキテクチャが同時に存在しており、それぞれを順を追って見ていきましょう。
最初のアーキテクチャは VAE に似た構造で、上図の最上部に示されています。この部分は著者が提案したものではなく、先行研究の結果を利用したものです。実際、この部分は訓練には参加せず、画像を小さなブロックに分割し、それにラベルを付ける役割を果たします。
この部分の目的は、画像を離散化し、モデルがピクセル値だけでなく高次の特徴を学習できるようにすることです。全体のコンセプトは、「画像辞書」を訓練するようなもので、画像の異なる抽象的な概念に対応する 8192 個のラベルがあります。
この部分の訓練方法と詳細については、原論文を参照してください:
-
[21.02] Zero-Shot Text-to-Image Generation
ヒントはい、あなたが考えている通り、それはあの有名な DALL-E です。
次のアーキテクチャは、上図の下半分に示されており、実際に勾配更新に参加するモデルです。
ここでは、私たちが知っている ViT と全く同じです。違いは、元々の ViT が画像ラベルを使用して監視型学習を行っていたのに対して、ここでは BERT の MLM 機構が導入されていることです:
-
Patchify:画像を小さなパッチに分割するのは、ViT と同じです。
-
Blockwise Masking:ここから違いが出てきます。この部分では、いくつかのパッチをランダムにマスクします。マスクのロジックは論文に記載されています:

このマスクロジックは「ブロック単位」のもので、BERT のように「トークン単位」のマスクではありません。ここでは、各反復ごとにランダムにアスペクト比を生成し、マスクサイズを決定し、最終的にブロック全体を覆い隠します。
この操作は繰り返し行われ、画像の 40%がマスクされるまで続けられます。
-
Transformer Encoder:この部分は ViT のエンコーダで、マスクされたブロックも一緒にモデルに入力され、予測が行われます。
-
Masked Patch Prediction:この部分では、マスクされたブロックのラベルを予測します。このラベルは、前述の 8192 個のラベルのうちの一つです。
訓練方法
BEiT のネットワークアーキテクチャは、ViT-Base の設計に従っており、公平な比較を確保しています。BEiT は 12 層の Transformer アーキテクチャを使用し、隠れ層のサイズは 768、注意力ヘッドは 12 個、FFN の中間層のサイズは 3072 です。入力パッチのサイズは 16×16、視覚的なトークンの語彙サイズは 8192 で、これらのトークンは事前に訓練された画像分割器によって生成されます。
BEiT は ImageNet-1K の訓練セットで事前学習されます。この訓練セットには約 120 万枚の画像が含まれています。事前学習中の画像増強戦略には、ランダムサイズ調整、切り抜き、水平反転、色のジッターが含まれます。注目すべきは、事前学習中にラベルが使用されていないことです。
著者は実験で 224×224 の解像度を使用し、入力画像を 14×14 のパッチに分割し、最大 75 個のパッチ(約 40%)をランダムにマスクします。
事前学習は約 500,000 ステップ(800 エポック)で行われ、バッチサイズは 2000 です。Adam オプティマイザーを使用し、、学習率はに設定され、最初の 10 エポックはウォームアップ段階として、以降はコサイン学習率減衰を適用します。重み減衰は 0.05 で、ランダム深度技術が 0.1 の割合で使用されます。
訓練は 16 枚の Nvidia Tesla V100 32GB GPU カードを使用し、約 5 日間かかります。
Transformer の大規模な事前学習を安定させるために、著者は適切な初期化を強調しています。最初にすべてのパラメータを小さな範囲でランダムに初期化し(例:)、その後、第層の Transformer に対して、自己注意モジュールと FFN の出力行列をに再スケーリングします。
下流タスクの微調整
BEiT の事前学習後、著者は Transformer にタスクレイヤーを追加し、下流タスクでパラメータを微調整します。これは BERT と同様の方法です。
論文では画像分類と語義分割を例に説明しています。その他の視覚タスクにも事前学習後の微調整パラダイムを直接適用できます。
-
画像分類:画像分類タスクでは、著者は単純な線形分類器をタスクレイヤーとして使用します。平均プーリングを用いて表現を集約し、グローバルな表現をソフトマックス分類器に渡します。
-
語義分割:語義分割タスクでは、著者は SETR-PUP で使用されているタスクレイヤーを採用しています。事前学習された BEiT をバックボーンエンコーダとして使用し、いくつかの逆畳み込み層をデコーダとして組み合わせ、分割を生成します。モデルは同様にエンドツーエンドで微調整され、画像分類と似た方法で進められます。
討論
ImageNet 上での性能
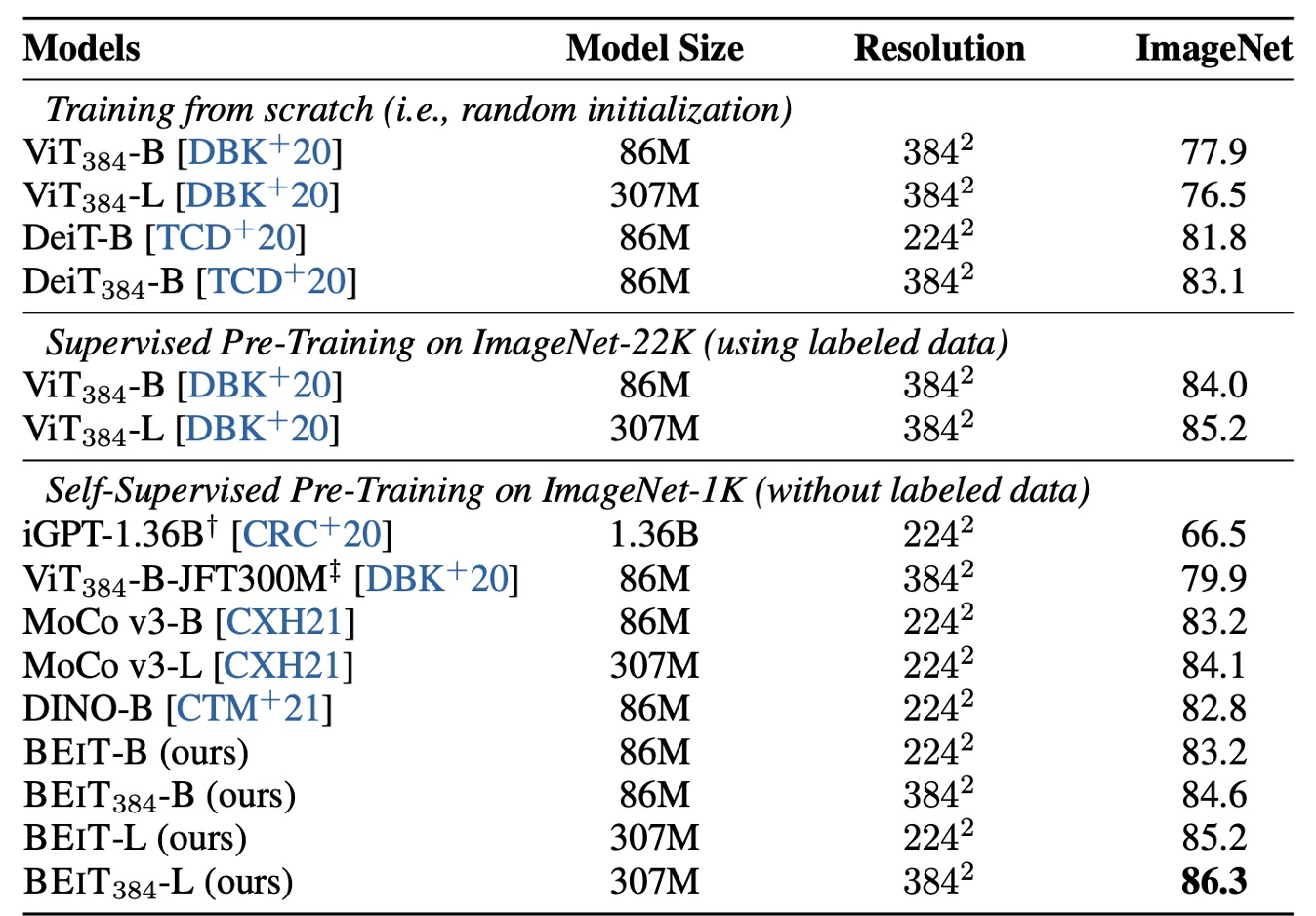
著者は BEiT モデルの画像分類タスクでの性能を調査し、他のいくつかの人気のある視覚 Transformer モデルと詳細に比較しました。これらのモデルの中で、iGPT を除き、他は基本的なサイズのモデルです。特に、ViT-JFT300M は Google 内部で 3 億枚の画像で事前学習されており、そのため比較で一定の優位性を持っています。
しかし、研究結果は、事前学習された BEiT モデルが ImageNet データセット上でこれらの比較モデルを大きく上回ることを示しています。
BEiT の性能をさらに検証するために、著者は 224×224 の解像度で微調整を行った後、384×384 解像度で追加の微調整を行いました。結果は、より高い解像度が BEiT の ImageNet 上での性能を顕著に向上させたことを示し、同じ解像度であっても BEiT384 の性能が ImageNet-22K での有監督事前学習を行ったよりも優れていました。
さらに、BEiT モデルは大きなバージョン(例えば BEiT-L)に拡張され、その性能向上が ViT の基本版から大型版に拡張する場合よりも顕著であることがわかりました。これは BEiT が大型モデルの処理において非常に優れた可能性を持っていることを示しています。モデルサイズが大きくなるにつれて、BEiT の改善効果はより顕著になり、特にラベル付きデータが不足している状況では、その優位性がさらに際立っています。
消融実験

最後に、著者はいくつかの重要なコンポーネントに対する消融実験を行いました。最初に消融されたのは Blockwise masking という技術で、ランダムにマスク位置をサンプリングする方法です。結果は、Blockwise masking が画像分類および語義分割タスクの両方に有益であり、特に語義分割タスクではその効果がより顕著であることを示しました。
次に、著者は視覚トークンの使用を消融し、マスクされた領域の元のピクセルを予測することで、事前学習タスクをピクセル回帰問題に変更してマスクされたブロックを復元しました。研究結果は、提案されたマスク画像モデルタスクが、単純なピクセルレベルの自己符号化よりも優れていることを示しています。
上表の結果と比較して、消融実験の結果は、両方のタスクで、ゼロから訓練された視覚 Transformer に対して劣ることがわかりました。これにより、視覚トークンの予測が BEiT の成功の鍵であることが示されています。
三番目に、著者は視覚トークンと Blockwise masking の両方を消融しました。結果は、Blockwise masking がピクセルレベルの自己符号化にとってより大きな助けとなることを示しており、短距離依存の問題を緩和するのに役立っています。
四番目に、視覚トークンをすべて復元すると、下流タスクの性能が損なわれることが確認されました。五番目に、著者は BEiT を異なる訓練ステップ数で比較しました。結果は、事前学習時間を延長することで、下流タスクの性能がさらに向上することを示しました。
これらの消融実験は、Blockwise masking と視覚トークン予測が BEiT モデルの成功の鍵であることを示しています。
結論

BEiT は ViT が未完成であった自己教師あり事前学習を引き継ぎ、BERT の成功体験を ViT のアーキテクチャに移行しました。自己教師ありの事前学習フレームワークを導入することで、BEiT は画像分類や語義分割といった下流タスクで優れた微調整結果を達成しました。
また、この方法は興味深い特徴を持っており、人工ラベルデータが一切ない状態で、意味的な領域に関する知識を自動的に獲得することができます(上図参照)。この特徴は今後の多モーダル事前学習タスクにおいて重要な役割を果たす可能性を秘めています。
後続の BEiT-V2 および BEiT-V3 ではさらに改良が加えられており、今後それらについて議論することが期待されます。