[22.01] SAFL

Focal Loss を試してみよう!
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss
最近、Transformer アーキテクチャが STR(シーンテキスト認識)の分野でますます登場しています。
研究をしていると、ちょっとした楽しみを見つけたくなりますよね。今回、著者は Focal Loss を試してみて、モデルのパフォーマンス向上に役立つかどうかを調べました。
問題の定義
最も一般的な訓練方法は、大きく分けて 2 つです。
1 つ目は CTC Loss です。この方法では、モデルの出力とラベルを直接比較し、その差異を計算します。これにより、ラベルを整列させることなく、出力シーケンスを与えて、モデルがどのように整列させるかを学習し、最終的な結果を得ることができます。
2 つ目は CrossEntropy Loss です。この損失関数を使用する場合、通常はデコーダーアーキテクチャを使用して出力とラベルを整列させます。デコーダーとしては、LSTM や Transformer を選択することができます。
CrossEntropy Loss があるので、他の損失関数を試すのは自然なアイデアです。隣のオブジェクト検出の分野では、Focal Loss が流行っているようなので、これを試してみるのも良いかもしれません!
そのため、著者は SAFL を提案しました。これは、Focal Loss を損失関数として使用する STR モデルです。
問題の解決
モデルアーキテクチャ
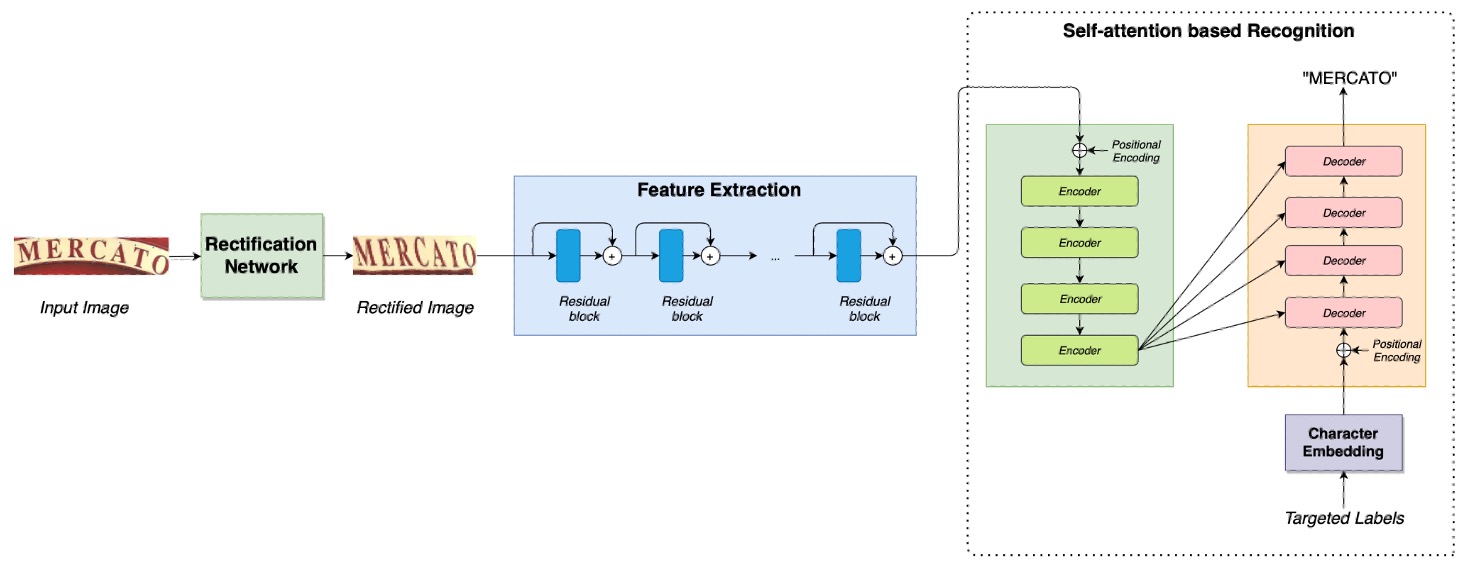
今回のアーキテクチャはシンプルで、ほとんどの内容は以前に見たことがあります。
まず、校正ネットワークがあります。この部分については以下を参照してください:
次に、特徴抽出ネットワークがあり、その後に Transformer アーキテクチャが続きます。この部分については以下を参照してください:
著者は最後に CrossEntropy Loss を Focal Loss に置き換えました。
なぜ Focal Loss に変更したのでしょうか?
Focal Loss
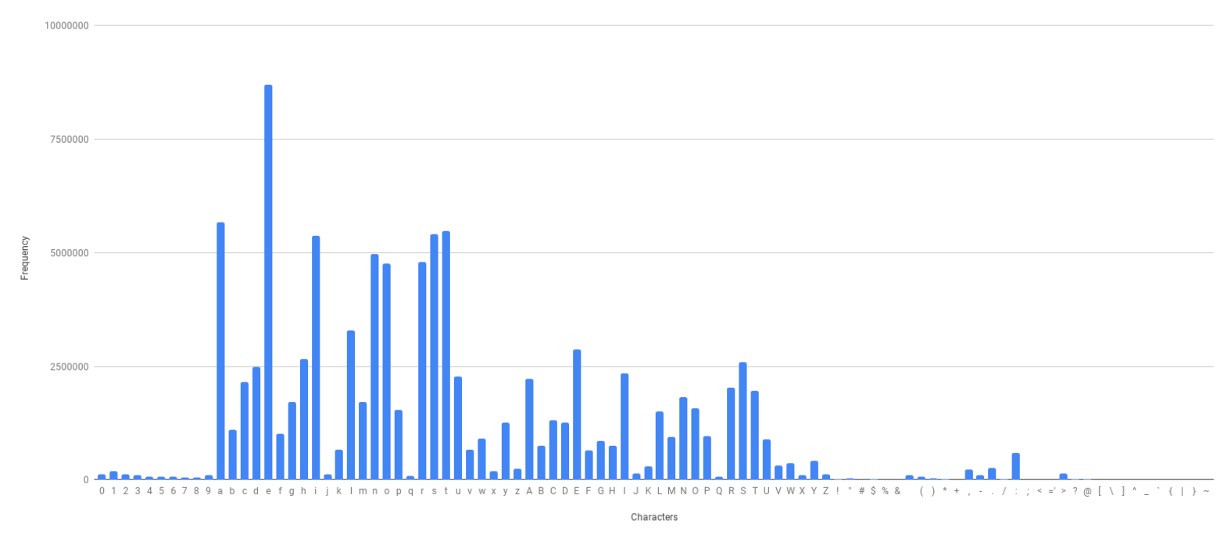
著者は訓練データの語彙分布を分析した結果、一部の語彙が非常に高い頻度で出現し、他の語彙は非常に低い頻度で出現することを発見しました。このような分布は、CrossEntropy Loss が効果的でない原因となります。なぜなら、高頻度の語彙に対する予測結果が敏感になり、低頻度の語彙に対する予測結果は無視されるからです。
Focal Loss は、この問題を緩和することができる損失関数であり、公式は次のようになります:
ここで、はモデルの予測確率、はハイパーパラメータで通常は 2 に設定されます。この公式の意味は、が 1 に近いほど、損失関数の値が小さくなるということです。これにより、モデルは予測が間違っているサンプルにより集中し、予測が正しいサンプルにはあまり関心を持たないようになります。
この論文は以前にも読んだことがあるかもしれません。参考にしてください:
討論
Focal Loss の効果はどうだったか?
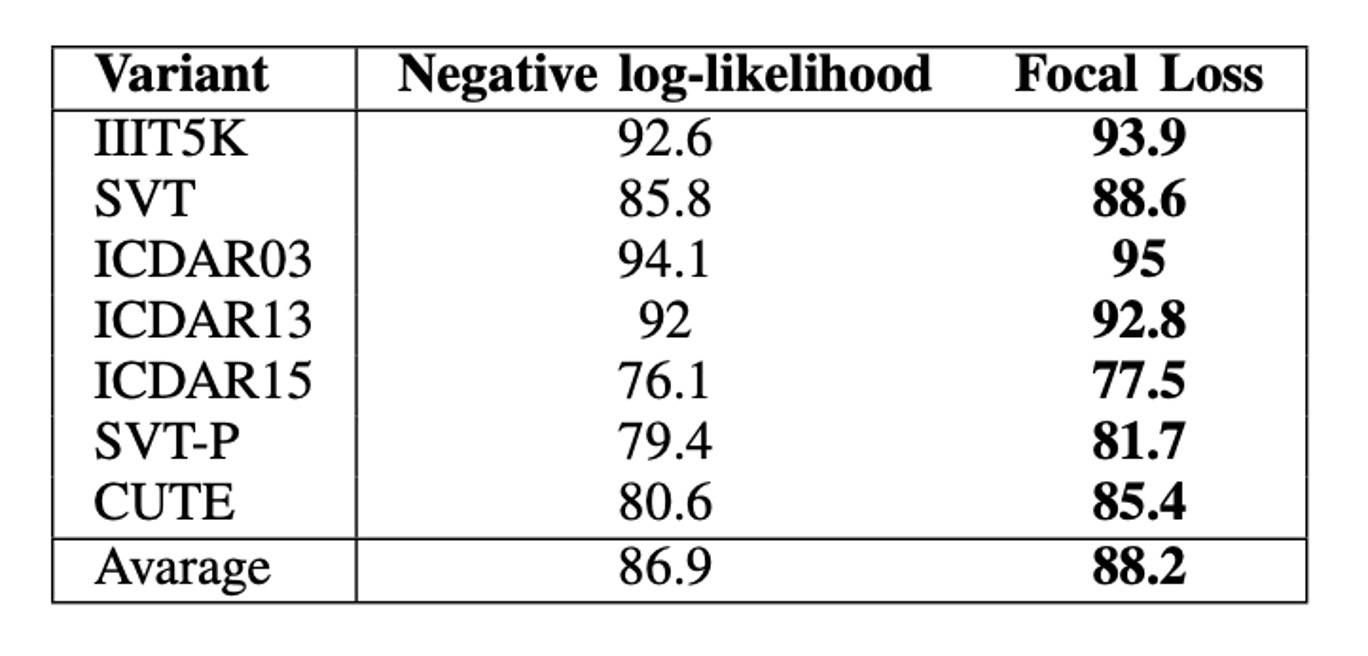
上の表のように、Focal Loss を使用したモデルは、すべてのデータセットで CrossEntropy Loss を使用したモデルを上回っています。
平均的に、Focal Loss は精度を 2.3%向上させました。最良の結果が得られた CUTE データセットでは、両者の性能差は 4.8%でした。
結論
この論文では、著者は自己注意機構と Focal Loss を組み合わせたシーンテキスト認識のディープラーニングモデルを提案しました。
実験結果は、SAFL が標準的なデータセットと不規則なデータセットの両方で最高の平均精度を達成したことを示しています。
もし STR の研究をしているなら、Focal Loss を試してみると、思わぬ効果が得られるかもしれません!