[23.11] 3A-TTA

荒野でのサバイバル
Test-Time Adaptation for Robust Face Anti-Spoofing
あなたが写真と顔を見分ける方法を覚えているとは思えません。
もしかしたら、光の加減や反射、あるいは何かしらの違和感から、それを感じ取ることができるのでしょう。
しかし、モデルにとっては、この問題は決して簡単ではありません。特に、誰にも教えられることなく、モデル自身が決定しなければならない時、それはさらに難しくなります。
問題定義
Face Anti-Spoofing(FAS)は、一見簡単そうに見えて、実際は非常に難しい問題です。
私たちはただその顔が本物か偽物かを判別する必要がありますが、この判別は、無数の環境の変化、攻撃の種類、デバイスの違いによって崩れてしまいます。
環境を越えた問題を解決するために、多くの研究者が強力に見える学習戦略を提案してきました。
- Domain Generalization(DG)は言います:「モデルをより安定させよう。」
- Domain Adaptation(DA)は言います:「新しいデータに先に触れさせてから学ばせよう。」
- さらに、Source-Free DA(SFDA)も言います:「大丈夫、古いデータを使わなくても微調整できるよ。」
もし未来の使用シーンが分かっていれば、これらの方法でモデルはトレーニング段階で未来の変化に適応できるようになります。
しかし、この世界は決して予測通りにはいきません。
モデルがすでにデプロイされ、攻撃者が見たことのない手法で侵入し始め、環境があなたが適応したことのない変数を生み出した時、私たちがトレーニングを完了したと思っていたそのモデルは、再度学習する機会を持つのでしょうか?
この論文の出発点は、このようなシナリオから来ています:
「学習の機会が推論の瞬間にしか残されていないとき、モデルはどう反応すべきか?」
これは単なる技術的な問題ではなく、遅れてきた記憶の対抗戦です。
私たちは攻撃者の次の手を予測することはできませんが、最後の瞬間にでも、モデルに見直すチャンスを与え、再び見る力を学ばせることができます。
解決方法
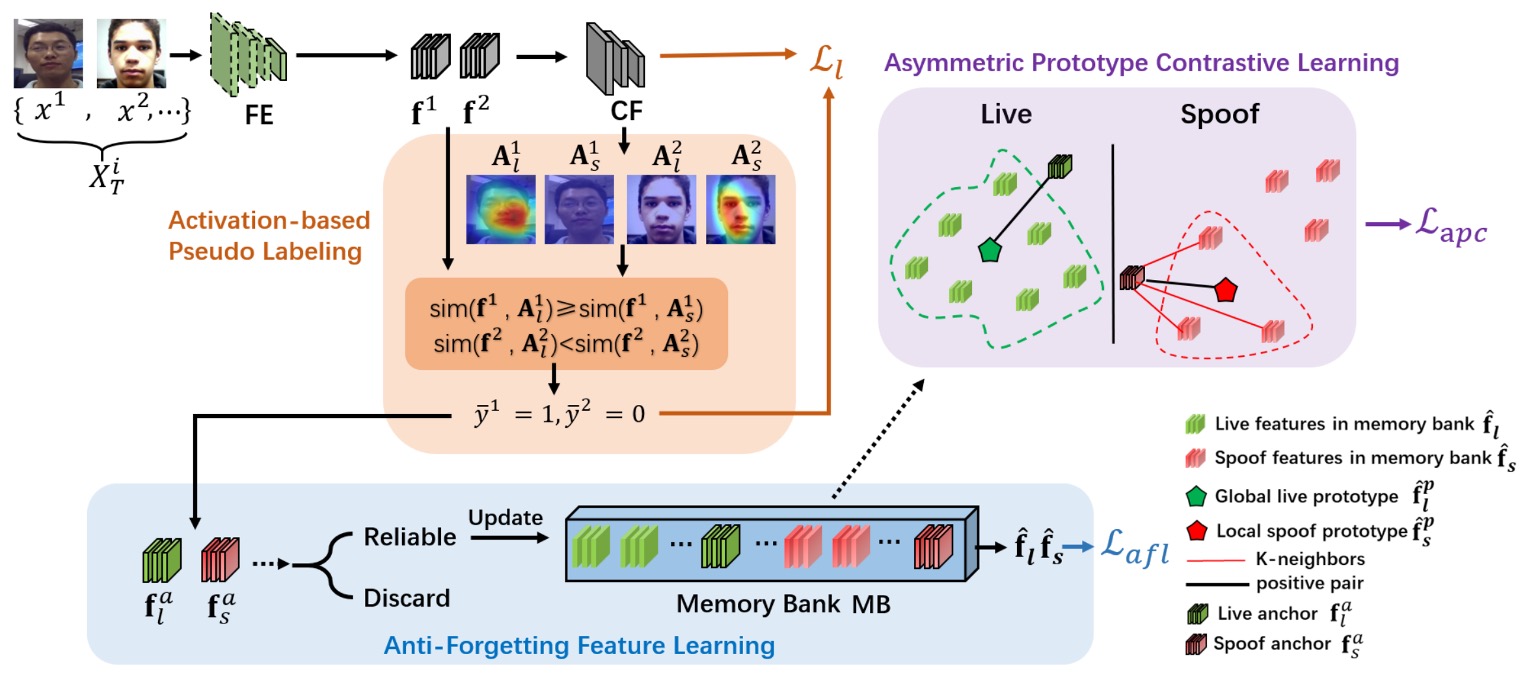
著者は3A-TTAという三つの機能を統合した解決策を提案し、モデルが「実際の推論」の時に、未ラベルのターゲットデータを使って最終的な適応調整を行えるようにしました。
このアーキテクチャは 3 つの主要なコンポーネントに分かれています:
-
Activation-based Pseudo-Labeling:
テストデータにはラベルがありません。では、モデルはどうやって学ぶのでしょうか?スコア(score-based)で偽ラベルを生成すると、実際の顔と偽造顔の外観が似ているため、混乱を招きやすくなります。
この部分では、CAM(Class Activation Map)を使用してより詳細な特徴位置情報を抽出し、余弦類似度を利用して、より信頼性の高い「偽ラベル」を生成します。
-
Anti-Forgetting Feature Learning:
新しいバッチに新たな攻撃タイプが含まれている場合、モデルはそれらを学習するかもしれませんが、同時に古い知識を「忘れて」しまうこともあります。
そのため、ここでは高い信頼性を持つサンプルを「選別」した後、それらの特徴をメモリバンク(Memory Bank)に保存し、毎回の更新時に一緒に考慮することで、モデルが知識を忘れるリスクを減らします。
-
Asymmetric Prototype Contrastive Learning:
新しい攻撃タイプは、古い攻撃や実際の顔と特徴空間で一部重複しているかもしれません。まだその攻撃を見ていない場合でも、どのようにして偽体と活体を区別するのでしょうか?
著者は対比学習を使用し、偽体に対しては局所的な集約(攻撃サンプルに近い K 個の偽体特徴を見つける)、活体には全体的な集約(すべてのライブ特徴を 1 つのプロトタイプに合成)を適用します。これにより、攻撃間の局所的な類似性を保ちながら、活体と偽体を明確に区別することができます。
著者の設定では、モデルが新しい「未ラベル」のターゲットデータのバッチを受け取るたびに、次の手順を実行します:
(1) 偽ラベルの生成 → (2) 信頼性の高いサンプルの選別 → (3) 対比学習の更新。
このプロセスは推論段階で行われ、追加のラベルを頼りにすることはなく、また古いデータを繰り返し呼び出すこともありません。
3A-TTA は、新しい攻撃を見た後に、偽ラベルと対比学習を使用してモデルのパラメータを即座に修正し、その後のバッチの判断をより正確にします。
もしあなたがコンセプトだけを知りたいのであれば、この論文はここまでです。
次に、各コンポーネントの動作原理を詳しく見ていきます。興味がない場合は、結論部分に直接飛んでください。
Activation-based Pseudo-Labeling

上の図はこのメカニズムの動作の概念図であり、このステップは「ラベルがない場合、どう学習するか」という問題を解決します。
ある未ラベル画像 を考えたとき、スコア予測だけでその画像が実際の顔か偽顔かを予測すると、光の加減や表面特徴が似ているため誤判定される可能性があります。
そのため、著者は過去の文献で使用された Class Activation Map (CAM) を参考にし、特徴空間内で実際の顔と偽顔の最も代表的な活性化領域を特定しました。
次に、著者は余弦類似度 を定義しました:
そして、実際の顔と偽顔の活性化マップの類似度を比較することで、偽ラベル を決定します:
これにより、各画像に対してより実行可能な偽ラベルを生成することができます。
最後に liveness loss を用いて、モデルがテスト段階でも更新を続けられるようにします:
Anti-Forgetting Feature Learning
偽ラベルだけでは不十分です。なぜなら、いくつかのバッチは「すべて live かすべて spoof」または「未知の新しい攻撃」が混ざっている可能性があるからです。このデータだけで更新すると、「新しい偽顔サンプルだけを覚えて、古い知識を忘れてしまう」という問題が発生します。
このような状況を避けるため、著者は毎回のバッチ更新時に閾値メカニズムを使用して最も信頼性の高い特徴を選別し、それらを Memory Bank (MB) に保存します。
新しいバッチが到来するたびに、MB 内の特徴も一緒に考慮し、Anti-Forgetting Liveness Loss を計算して、モデルが新しいデータに過度に偏らないようにします。
具体的な方法としては、各サンプル に対してその偽ラベル を定義し、以下の閾値判定を行い、信頼性を確認します:
ここで、 です。
もし ならば、この特徴は に書き込まれます(FIFO 方式で更新されます)。
このように生成されたサンプル特徴集合は、次のミニバッチ更新時にも考慮され、次のように Anti-Forgetting Liveness Loss を定義します:
この方法により、モデルは新しいバッチと過去の知識の両方を学習し、安定した意思決定を維持します。
Asymmetric Prototype Contrastive Learning
しかし、攻撃パターンが増えてくると、記憶庫でさえすべての変形手法を捉えることができない場合があります。
そのため、この段階で行うべきことは、同一の特徴空間内で「実際の顔と偽顔の距離を広げる」一方で、「偽顔同士の共通点を適度に集約する」ことです。
-
局所集約(Local Spoof Prototype)
例えば、新しい攻撃タイプの偽顔サンプル があるとしましょう。
しかし、記憶庫には「古い攻撃」の特徴が一部似ている可能性があります(例えば、高い光沢反射が現れる)。これら最も近い K 個の偽顔サンプルを集約して、局所的な spoof 原型を作成します。これにより、モデルは新しい攻撃に対する判別能力を向上させることができます。
-
全域集約(Global Live Prototype)
一方で、実際の顔はドメインを越えても大きな違いはありません(顔の位置は似ており、肌の色の違いも小さな変動です)。そのため、著者はすべての live 特徴を一つの「全域」の live 原型として集約し、実際の顔間の一貫性を強調します。
このようにして形成される「非対称対比学習」は、モデルが偽顔と実際の顔の間で距離を広げる一方で、異なる偽顔間の微妙な類似点も保持し、「攻撃適応」の柔軟性を高めます。
偽ラベル学習と防忘戦略があっても、未知の攻撃に対してモデルは十分な判別手がかりを欠いている可能性があります。正負サンプルの集合を取り入れた後、著者は Asymmetric Prototype Contrastive Loss を定義しました:
ここで、 と はそれぞれ spoof と live anchor の負のサンプル集合です。
この対比学習により、実際の顔と偽顔の間で距離を広げることができ、同時に各偽顔間の微妙な類似点を保持し、未知の攻撃に対する適応性を強化します。
総損失関数
最後に、著者は上述の 3 つの損失を統合して
とし、実験では 、 に設定しました。
偽ラベル学習 (Liveness Loss)、防忘 (Anti-Forgetting)、対比区別 (Prototype Contrast) を統合することにより、モデルはただ入力を受け入れるのではなく、最後の瞬間に素早く調整を行い、現実世界の未知の環境でも高い安定性と適応力を維持します。
討論
他の方法との比較
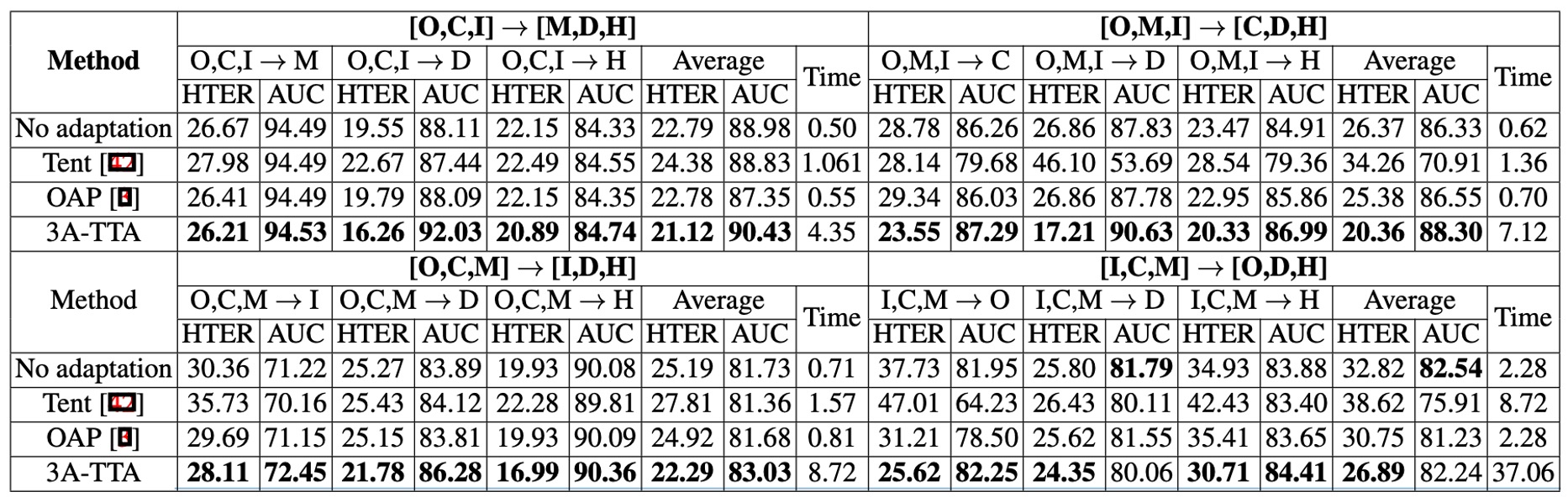
著者は 3A-TTA を他の一般的な Test-Time Adaptation 技術(例えば Tent や OAP など)と比較し、その全体的な性能を評価しました。
実験結果は上記の表に示されています:
- Tent などの非 FAS 専用 TTA 技術は、実際の攻撃シナリオにおいて、「No adaptation」よりも悪化しました。これは、汎用的な TTA 方法が必ずしも FAS に直接適用できるわけではないことを示しています。
- OAP はスコアベースの偽ラベルのみを使用しており、ほとんどの場合、効果が限られています。
- 3A-TTA はさまざまな評価基準で最優秀な結果を達成しました。例えば、平均 HTER で OAP より約 12.54% 改善され、AUC でも約 2.11% の向上が見られました。
消失実験
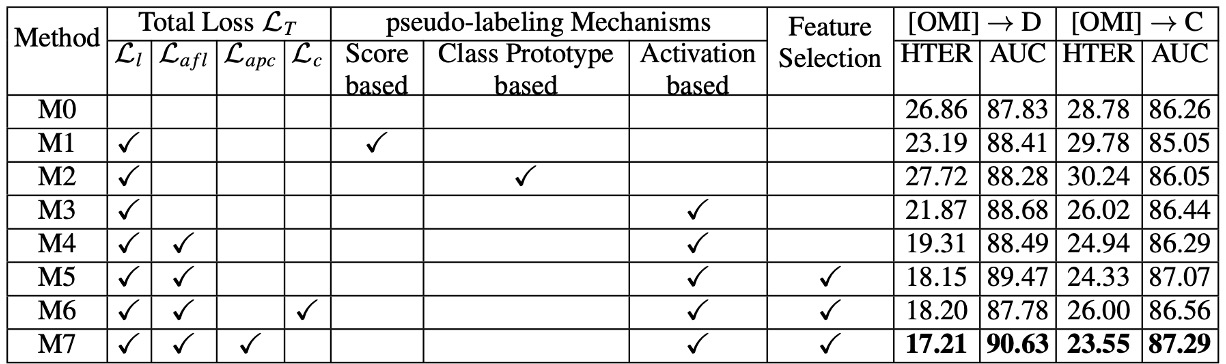
著者は三つの主要なモジュール(偽ラベル学習、Anti-Forgetting、Asymmetric Prototype Contrast)を分解し、さまざまな損失の組み合わせを比較しました。
主要な発見は次の通りです:
-
偽ラベル機構:
- スコア導向(Score-based)やプロトタイプ導向(Prototype-based)の方法は、Activation-based(本論文の方法)と比較して、偽ラベルの精度に顕著な差がありました。
- Activation は、地域ごとにより詳細な判断を提供するだけでなく、攻撃の論理に対して重要な部分を捉えることができることが示されました。
-
Anti-Forgetting Feature Learning:
- のみ、または を加えた場合、性能が明らかに向上しました。
- 可能な限り記憶庫機構を補助的に使用することで、モデルは新しい知識と古い知識を両立させ、現在のバッチに偏りすぎることを避けることができます。
-
プロトタイプ対比 vs. 一般的な対比:
- 一般的な対比学習 () を使用すると、すべての攻撃を「同質の偽顔カテゴリー」と見なしてしまい、新しい攻撃と古い攻撃の重要な違いが無視される可能性があります。
- Asymmetric Prototype Contrast () は攻撃間の微妙な差異をより効果的に強調できるため、未見の攻撃に直面した場合に顕著な優位性を発揮します。
視覚化分析
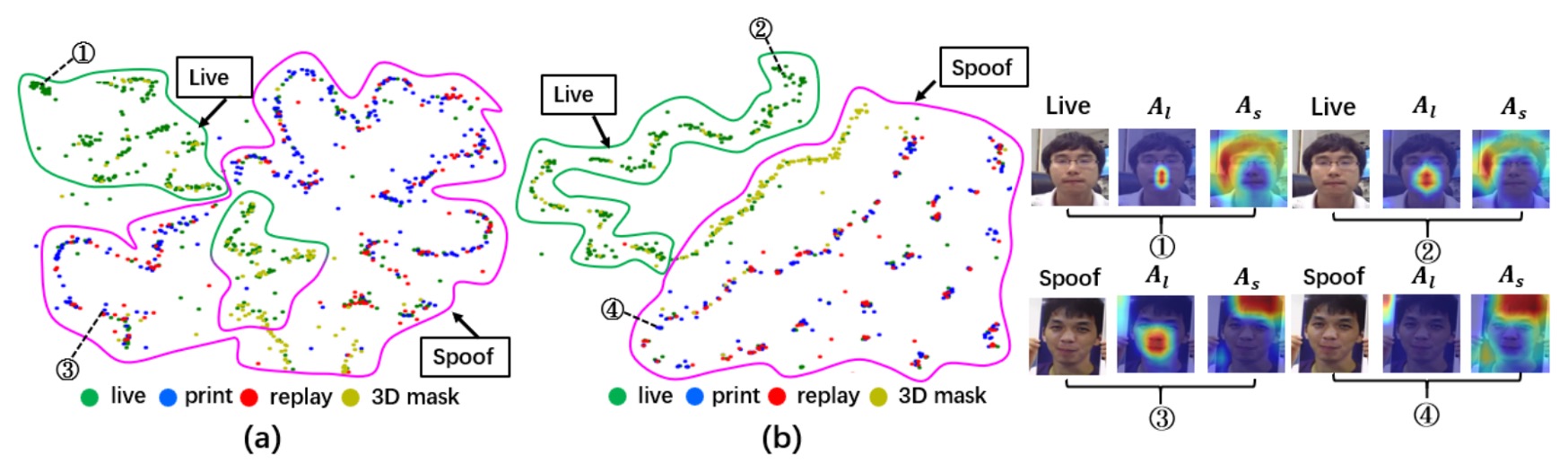
最後に、著者は 3A-TTA の結果を他の方法と視覚的に比較し、未適応のモデルと比較しました。
-
t-SNE 特徴分布:
- 上図 (a) では、未適応のモデルが新しいドメインや新しい攻撃に直面した際、Live と Spoof の特徴が明確に重なっていることが示されています。
- 上図 (b) では、3A-TTA の利点が確認され、Live と Spoof の特徴がより明確に分離され、モデルが未見の攻撃を区別する能力が大きく向上していることがわかります。
-
Activation Maps:
- 未適応の場合(上図の ① および ③)と比較して、3A-TTA による活性化マップ(② および ④)は、実際の顔の領域に焦点を合わせており、より優れた識別を示しています。
- 偽顔に対して、モデルはほとんど反応せず、偽顔の干渉を排除して、実際の顔の詳細に焦点を合わせることができています。
結論
Face Anti-Spoofing はもはや単純な分類タスクではありません。
生成攻撃が進化し、データソースがますます分散する環境において、FAS モデルが生き残るためには、次の能力が必要です:
未曾見のシーンでも、判断基準を自己修正できる能力。
本論文で提案された 3A-TTA は、この「自己修正」の試みであり、一定の意味でこれに対応しています。
結果として、この方法は TTA-FAS ベンチマークにおいて、従来の方法を上回り、Test-Time Adaptation が FAS タスクに新しい対応経路を提供できることを証明しました。
従来のモデルの寿命は訓練完了とオンライン推論で終わりますが、TTA モデルの寿命は推論時点で始まります。この考え方は、次のような問題を再考させます:
現場が戦場であるなら、モデルはどのようにして現場で反撃を学ぶべきか?
おそらく、未来の AI モデルはただ「答えを出す」だけでなく、「答えを出した後に修正する」方法も学ぶべきなのでしょう。