[20.02] SimCLR v1

大バッチサイズ
A Simple Framework for Contrastive Learning of Visual Representations
対照学習の研究は約 5 年が経ち、全体の状況は非常に複雑で混沌としています。アーキテクチャ設計だけでなく、具体的なモデル訓練方法も多種多様です。
本論文の著者は、対照学習のコアはもっとシンプルであるべきだと考えています。
問題の定義
対照学習に必要な要素を思い出してみましょう:
- 良い結果を得るためには、メモリーバンクが必要?
大量の負のサンプルがモデルにより良い表現を学ばせるために必要であり、メモリーバンクは確かにその機能を提供します。最初の InstDict はこのようにしていましたし、その後の MoCo もそうです。
しかし、面倒です!訓練中に追加でメモリーバンクを維持するのは明らかに非効率的な設計です。
著者はこの論文で、メモリーバンクの設計を放棄し、その代わりにより大きなバッチサイズを使用することを決定しました。十分な数の負のサンプルを与えれば、モデルは十分に良い表現を学べるのです!
InstDict や MoCo をまだ読んでいない方は、以下の記事を参考にしてください:
問題解決
モデルアーキテクチャ
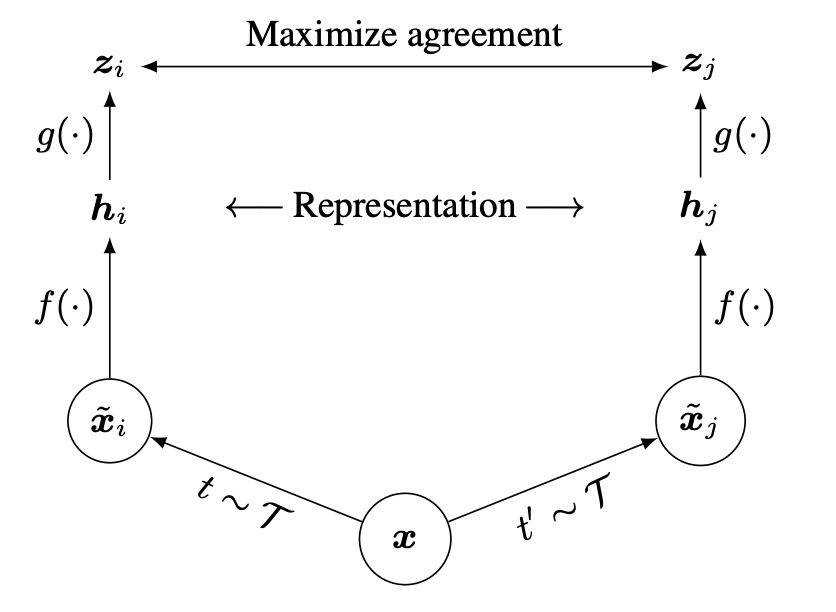
このアーキテクチャは非常にシンプルで、複数のエンコーダやメモリーバンクはありません。
プロセスは、同じ画像に対して 2 種類のランダムな強化を行い、「異なるように見えるが実際は同一の」2 つの画像を得ることから始まります。
次に、この 2 つの画像を「同じ」エンコーダネットワークに通して、2 つの潜在ベクトルを取得します。
その後、小型のプロジェクションネットワークを使ってこれらの潜在ベクトルを対照学習の空間にマッピングし、最後に対照損失関数を使って「同一の」強化画像が表現空間で近くなるようにします。
え?それだけ?
はい!それだけです、また論文を読み終わりました!(実際はそうではない)
画像強化

SimCLR では、著者は強化方法が多様で強力であり、監視付き学習よりも重要だと考えています。
論文で使用された画像強化方法は上図の通りです。特に重要なのは以下の点です:
- ランダムクロップ(random crop)
- カラー歪み(color distortion)
- ガウスぼかし(Gaussian blur)
2 つの強化後の画像は「正のサンプルペア」と見なされ、なぜならそれらは実際には同じ元の画像から来ているからです。
詳細設計
最初はエンコーダの部分です。ここでは ResNet-50 を基礎エンコーダとして使用し、強化後の画像を入力し、ベクトル を得ます。このベクトルの次元は通常非常に大きいです。例えば、ResNet-50 の場合、平均プーリング層を通すと 2048 次元となります。
次はプロジェクションヘッドの部分です。著者は、 の上で直接対照損失を計算するよりも、小型の MLP を追加する方が効果的であると発見しました。このプロジェクションネットワーク は通常、1 つの隠れ層を持ち、ReLU を通して、最終的に 128 次元のベクトル にプロジェクションされ、対照損失を計算します。
最も重要なのは、対照損失をどのように定義するかです。
コアの概念は、同じペア (同じ元の画像からの 2 回の強化)はベクトル空間でできるだけ近くなるべきであり、他の無関係なサンプルとはできるだけ遠ざけるべきだというものです。ここで著者は、NT-Xent(Normalized Temperature-scaled Cross Entropy Loss)という形式を引用しています。
NT-Xent 損失関数
これは以前に見た InfoNCE 損失関数と本質的に同じですが、著者は入力の形式を変更しただけで、数式自体は変わっていません。ここでは、入力特徴に ℓ₂ ノルム正規化を適用することで、コサイン類似度の計算をより安定させています。
InfoNCE を提案した論文に興味がある場合は、こちらを参照してください:
NT-Xent 損失関数の計算式は以下の通りです:
ここで:
- は、第 番目の拡張画像をプロジェクションヘッドに通した後に得られる 128 次元のベクトルです。
- はコサイン類似度を表します。
- (tau)は温度(temperature)というハイパーパラメータで、類似度スコアのスケールを調整します。
- 分子の は、 と正例(positive sample) との類似度スコアの指数関数です。
- 分母は、バッチ内のすべての他のベクトル(自身を除く)との類似度スコアの指数関数の総和です。
バッチ内に 枚の元画像があると仮定すると、それぞれの画像に対して異なる 2 種類のデータ拡張が施され、合計 枚の拡張画像が生成されます。同じ元画像から作られた 2 枚の異なる拡張画像 を正例ペアとし、それ以外の 枚の拡張画像を負例(negative sample)として扱い、損失を計算します。
目的は、正例 の類似度を最大化し、他の負例の類似度を最小化することです。つまり、 が (すべての に対して)よりも十分に大きくなるように学習させます。これにより、類似したサンプルがクラスター化され、異なるサンプルが適切に分離されるようになります。
バッチ内では、各正例ペア に対して と の両方の損失を計算し、それらを合算して逆伝播を行います。
NT-Xent は、コサイン類似度(ℓ₂ ノルム正規化付き)と温度パラメータ()を用いて負例の影響を動的に調整します。
- コサイン類似度:ベクトルの「長さ」ではなく「方向」に注目することで、表現間の相対的な類似度をより正確に比較できるようにします。
- 温度パラメータ ():
類似度スコアのスケールを調整し、負例の損失への影響を変化させます:
- が小さい場合 → 類似度の差が強調される → ハードネガティブ(hard negatives) をより重視。
- が大きい場合 → 類似度の差が平滑化される → 負例の影響が均一に。
従来のコントラスト学習の損失関数では、簡単な負例・難しい負例 の影響を適切に考慮するために、通常 semi-hard negative mining を手動で設計する必要がありました。負例の選択を行わないと、多くの負例が簡単に識別可能で(コントラストが強すぎるため)、学習の効果が低下する可能性があります。
しかし、NT-Xent は コサイン類似度 + 温度調整 により、負例の重みを類似度に基づいて動的に調整するため、手動で負例を選別する必要がありません。実験によると、semi-hard negative mining を使用しない場合、ロジスティック損失やマージン損失などの他のコントラスト損失関数は通常 NT-Xent よりも効果が低く、semi-hard negative mining を加えても NT-Xent に勝るとは限らないことが示されています。
討論
最も有用な強化の組み合わせ
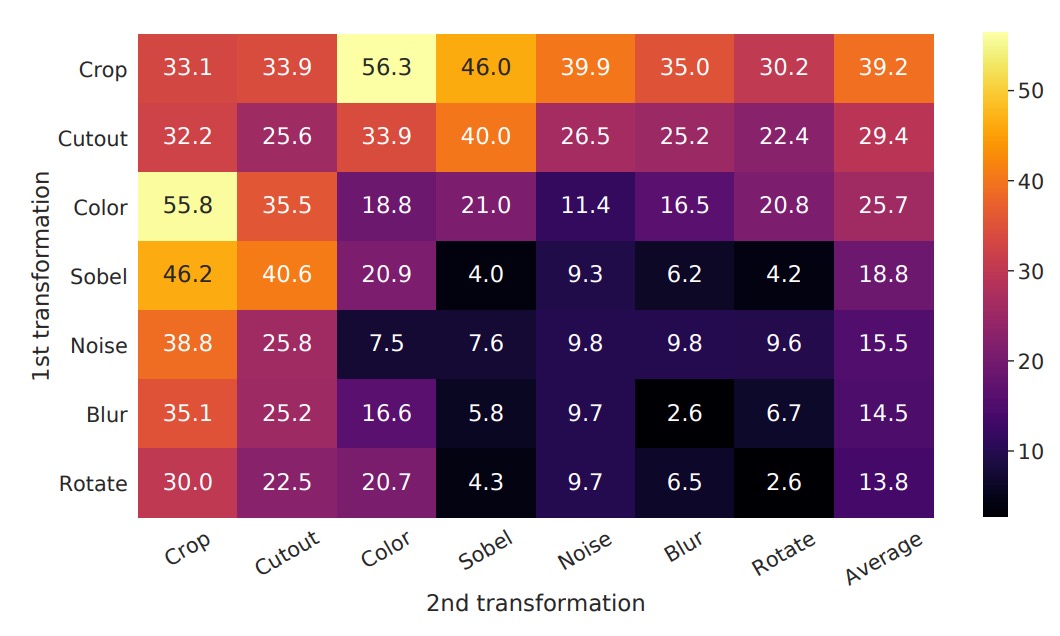
「異なるデータ強化方法(単独または組み合わせ)がモデルの学習した表現の品質に与える影響」を観察するため、著者はここで線形評価の方法を使用しています。これは、自己訓練したエンコーダを凍結し、その上に線形分類器(通常は 1 層の線形全結合)を重ね、ImageNet でトップ 1 精度を評価するというものです。
実験では、モデルの入力端には 2 つの「並行する強化パイプライン」があります。ここで著者は「1 つのパイプライン」のみにテストする強化を適用し、もう 1 つの分岐はその強化を施さず(最も基本的なランダムクロップ + リサイズのみ)、個別の強化や異なる強化の組み合わせが「それ自体」に与える影響をより直接的に観察できるようにしています。
上図の表の解釈方法は以下の通りです:
- 対角線(diagonal entries):単一の変換(例えば、ガウスぼかし、カラー歪みなど)。これはその強化を 1 つの分岐にのみ適用した場合を意味します。
- 非対角線(off-diagonals):2 種類の強化の組み合わせ(例えば、最初にガウスぼかしを適用し、その後にカラー歪みを適用)。
- 最後の列(the last column):各行の平均値、つまりその行の強化の組み合わせにおける全設定の平均パフォーマンスです。
実験結果は以下のことを示しています:
- 単一の強化(対角線)は通常、モデルが非常に強力な表現を学ぶには十分ではありません。なぜなら、この単一の変化だけに頼ると、モデルは他の不変な手がかりを使って「正のサンプルペア」を判断する可能性があるからです。
- 組み合わせ強化(非対角線)は線形評価の結果を向上させる傾向があります。
これは、2 つ以上の強化が同時に行われると、対照学習のタスクの難易度が上がる一方で、モデルがより一般的で安定した特徴を学習できるようになることを意味します。
強化の強度の影響
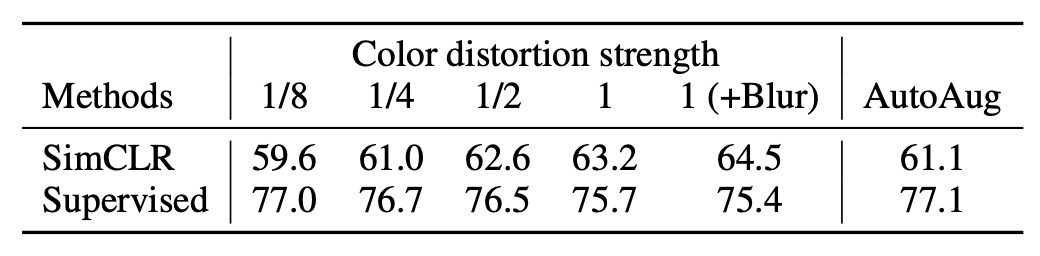
強化の強度を調整することができます。例えば、明度、コントラスト、彩度、色相の変化幅を大きくしたり小さくしたりできます。そこで著者は、「強化強度」がモデルのパフォーマンスに与える影響をさらに探求しました。
ImageNet で監視付き分類モデルを訓練する際には、AutoAugment のような自動強化戦略をよく使用します。しかし、著者はここで、AutoAugment が「シンプルなクロップ + 強力なカラー歪み」よりも優れているわけではないことを発見しました。
実験結果は上の表に示されており、監視なしの対照学習において、カラー歪みの強度を大きくすることが、モデルが最終的に学習する特徴品質を顕著に向上させることが分かります。これは、監視なしの対照学習に必要な強化手段が監視付き学習とは異なることを示唆しています。監視付き学習の下で「非常に効果的」な強化戦略が、必ずしも対照学習の効果を同じように向上させるわけではないのです。
異なる学習目標に対して、強化戦略の選択が異なる場合があることを忘れてはなりません。この問題を無視しがちですが、他に重要な事柄があるときでも、この点を考慮する価値があります。
著者の実験結果は、強化戦略の選択がモデルの学習効果に大きな影響を与える可能性があることを思い出させてくれます。したがって、この点を注意深く調整する時間を確保する価値があるということです。
モデル規模の拡大
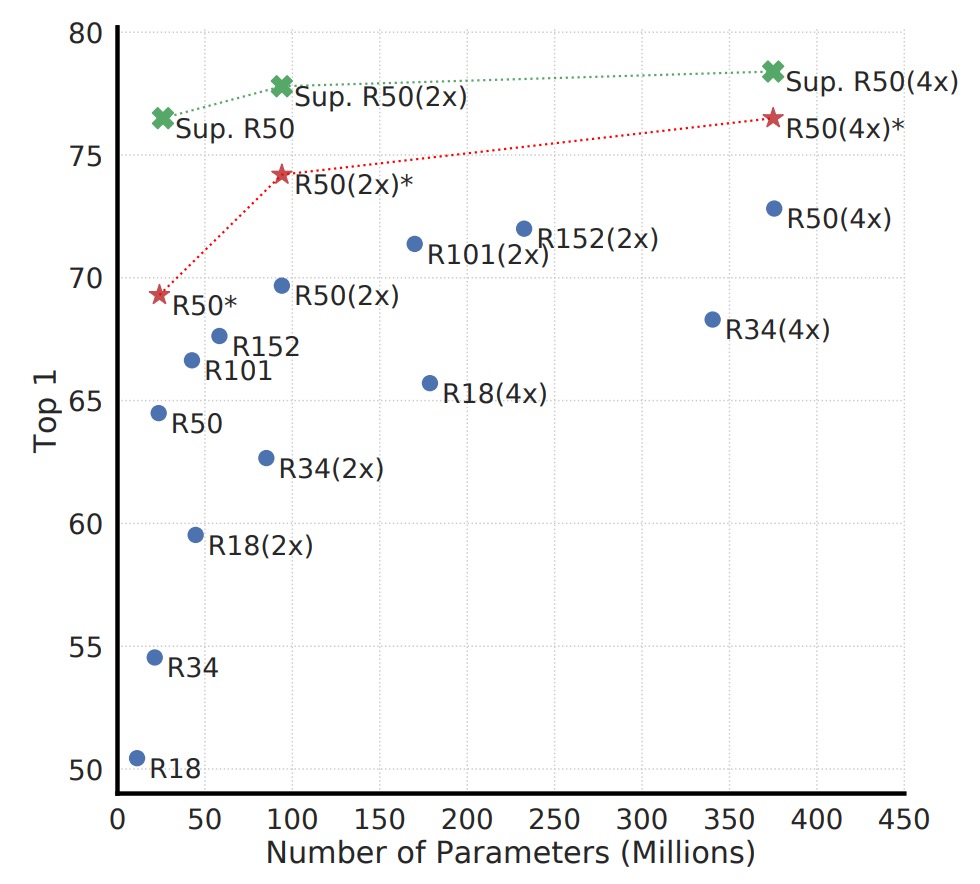
上図は、異なるモデル規模での対照学習の結果を示しています。著者は、モデルの規模が大きくなるにつれて、対照学習の性能が徐々に向上することを発見しました。
この結果は、監視付き学習での経験と似ています:モデルの容量を増やすことで、通常はより豊富な特徴表現能力を持つことができます。また、モデル規模が大きくなると、無監督対照学習の効果がより顕著に向上するため、対照学習は大きなモデルに対して依存度が高いことを意味します。
なぜ無監督学習は小さなモデルでは監視付き学習に劣るが、モデルが大きくなると競争力を持つのか?
無監督の状況では、モデルはデータの構造を自ら掘り起こさなければなりません。もしモデルが小さすぎると、表現空間に大きな制限がかかり、十分に豊かな特徴を学習することができません。しかし、モデル容量が十分であれば、ラベルなしでも観察できるさまざまなパターンを捉えることができ、そのパターンは監視付き学習で使用されるラベルよりも豊かである可能性があります。
バッチサイズの影響
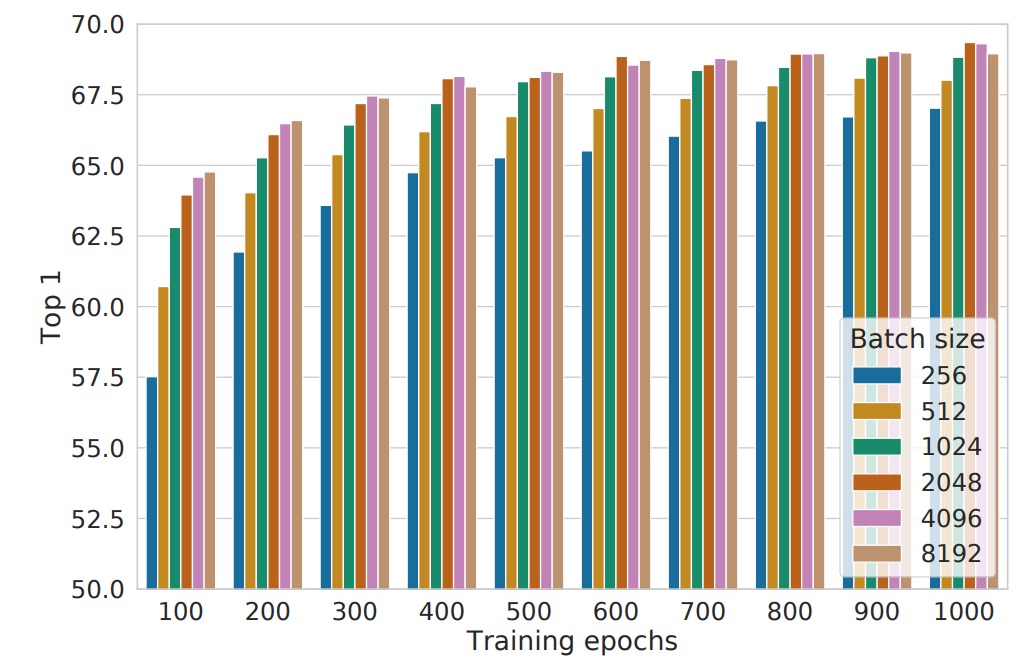
上図は、異なるバッチサイズと訓練エポック数での性能を示しています。各棒グラフは、最初から訓練した単回実験の結果です。
従来、バッチサイズの選択は計算効率と勾配の安定性を主に考慮して行われますが、対照学習ではバッチサイズにはもう一つ重要な役割があります:使用可能な負のサンプルの数に影響を与えるという点です。
- バッチが大きいほど、1 回の訓練で利用できる負のサンプルが多くなり、これによりモデルはより豊かな対照情報を学び、サンプルの区別能力が向上します。
- 収束速度の向上:訓練エポック数が少ない場合でも、大きなバッチサイズはモデルに多くの負のサンプルを観察させることができ、収束を加速させ、最終的な性能を向上させます。
これは監視付き学習とは異なります。監視付き学習では、大きなバッチを使用する主な目的は「勾配推定を安定させ、訓練を効率化する」ことですが、対照学習においては「より多くの負のサンプル」が大きなバッチのコアの利点です。
もう一つの興味深い発見は、訓練時間を長くすることで、小さなバッチサイズの欠点をある程度補うことができる点です:
- 訓練ステップ数が十分に多ければ、バッチサイズが小さくてもモデルは時間をかけて十分な負のサンプルの視野を蓄積し、大きなバッチとの性能差を縮小できます。
- しかし、同じ訓練時間であれば、大きなバッチは通常より早く同様の結果を達成できるため、限られた計算資源の中では、大きなバッチを選択することが効率的な戦略です。
他の方法との比較
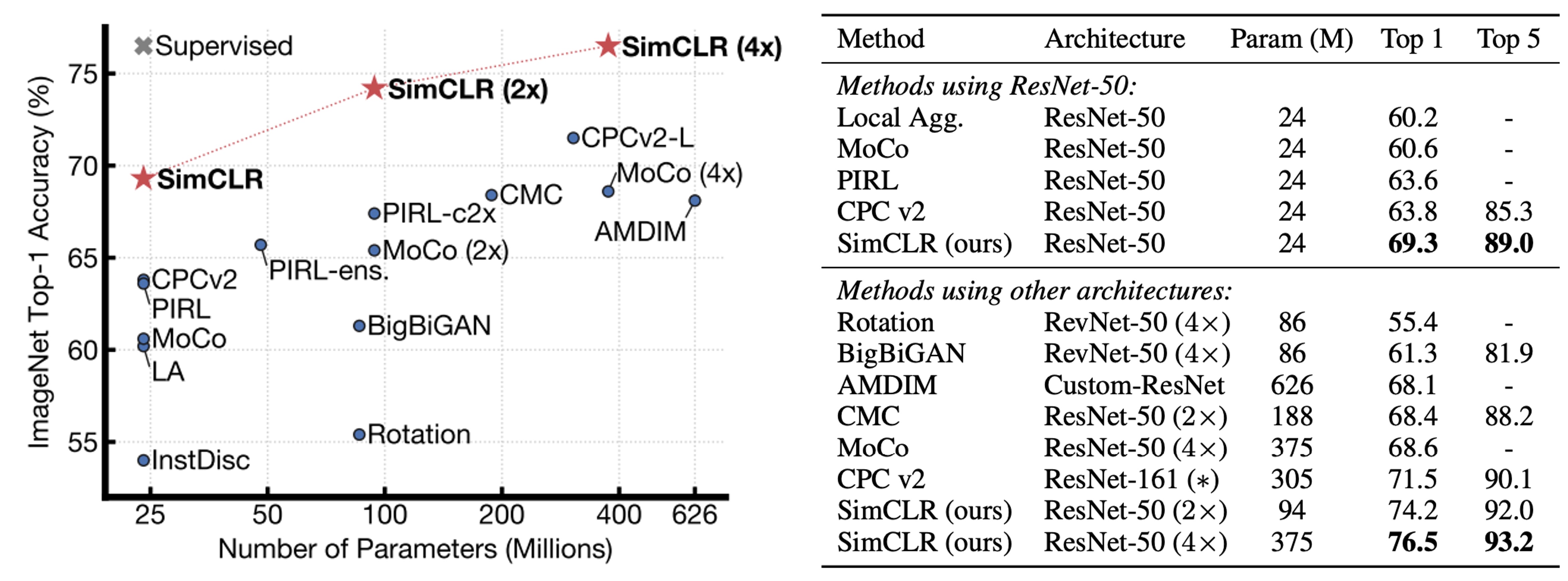
著者は、さまざまな自己教師あり学習法の線形評価結果を比較しました(つまり、バックボーンを凍結し、最後に線形分類器を 1 層追加)。
結果は、標準の ResNet アーキテクチャ(特別な設計なし)を使用しても、SimCLR は過去の特別に設計されたネットワーク構造を必要とする方法を上回るか、それに匹敵することを示しています。ResNet-50 を 4 倍に拡張すると、その線形評価結果は監視付きで事前学習された ResNet-50 と同等になり、無監督の対照学習が大きなモデルで非常に高い潜在能力を持っていることを示しています。
もし ImageNet のラベル数を 1%または 10%に圧縮し、カテゴリーバランスを考慮して微調整を行った場合、下記の表のように:
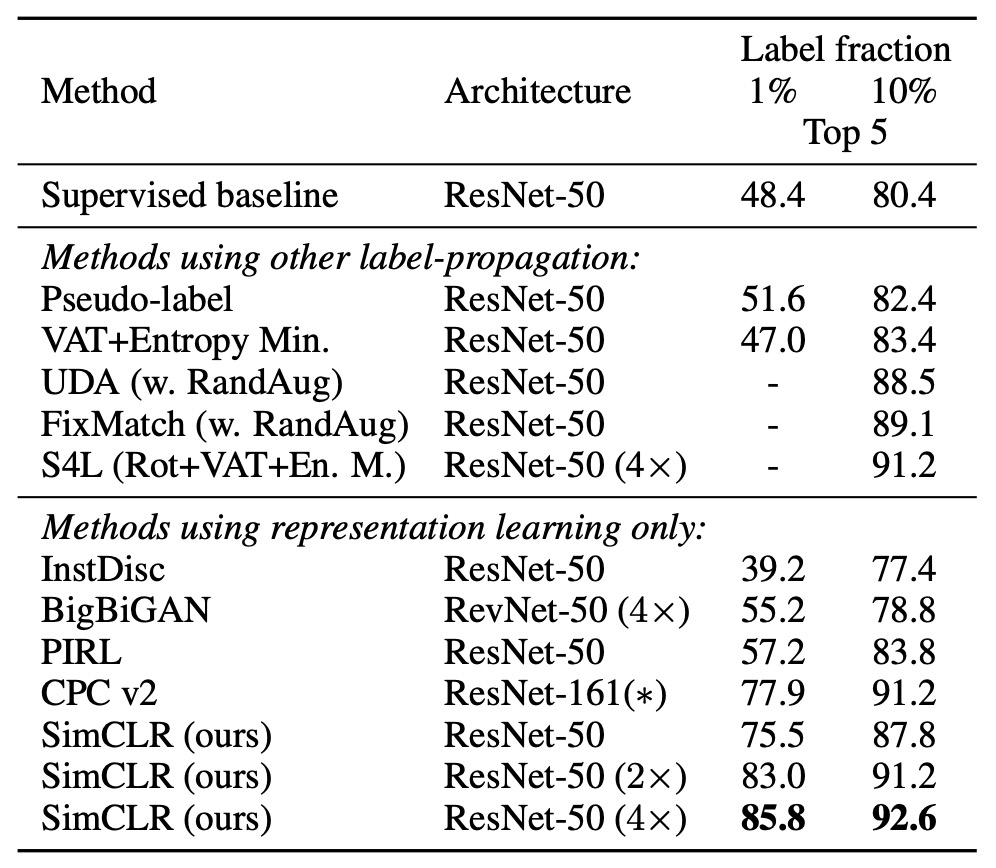
SimCLR の性能は依然として他の方法を上回っており、これにより対照学習が半教師あり学習でも大きな潜力を持つことが示されています。
結論
本研究では、著者はシンプルで効果的な対照学習フレームワークを提案し、さまざまな実験を通じて、異なる設計選択が学習効果に与える影響を深く分析しました。
結果として、データ強化戦略、非線形投影ヘッド、NT-Xent 損失関数を活用することで、SimCLR は自己教師あり学習、半教師あり学習、転送学習のタスクで先行技術を大きく上回る成果を上げました。
SimCLR と MoCo は対照学習の分水嶺となり、この分野で明確な研究方向を確立し、将来の研究に重要な参考を提供しました。