モデル設計
天下本無事,庸人自擾之。
そう、私たちは自分で問題を作ってしまいました。面倒だと感じながらも、面白いとも感じています。
二段階認識モデル
二段階モデルは MRZ 認識を二つの段階に分ける方法です:位置決定と認識。
このアプローチに基づき、関連するモデルの設計に取り掛かり、まずは位置決定モデルを見ていきましょう。
位置決定モデル
MRZ 領域の位置決定は、主に二つの方向に分けられます:
-
MRZ 領域の角点の位置決定:

画像出典:MIDV-2020 合成データセット これは以前行った書類の位置決定プロジェクトに似ていますが、ここでは書類の代わりに MRZ 領域を扱っています。
異なる点は、書類の位置決定では角点が「実際に」画像上に存在しており、モデルが「空想」する必要はありません。対照的に、MRZ 領域ではモデルがその角点を「推測」しなければならないということです。
実際には、この方法で作ったモデルは安定性に欠け、パスポートを少し動かすだけで、モデルが予測する角点が MRZ 領域の周りでランダムに動いてしまいます。
-
MRZ 領域の分割:

画像出典:MIDV-2020 合成データセット この方法はより安定しています。なぜなら、分割モデルを使って MRZ 領域の範囲を直接予測することができ、MRZ 領域の文字は実際に画像上に存在するため、モデルは「余計な」予測を行う必要がありません。この方法では、角点の問題を心配することなく MRZ 領域を分割することができます。
私たちは分割アプローチを採用しています。
実際の使用シーンでは、ユーザーが持っているパスポートは必ず何らかの角度で傾いているため、MRZ 領域を校正して、正しい矩形にする必要があります。
損失関数に関しては、以下のレビュー論文を参考にしました:
この論文では、過去数年間に提案された様々な分割用の損失関数を統一的に比較し、現行の問題に対する解決策としてLog-Cosh Dice Lossが提案されています。
興味のある読者はこの論文を参照できますが、ここでは詳細については割愛します。
私たちの実験では、単独でLog-Cosh Dice Lossを使用した結果は期待した通りの結果を出せず、最終的にピクセル分類損失CrossEntropyLossやピクセル回帰損失SmoothL1Lossを組み合わせてトレーニングしました。
認識モデル
認識モデルは比較的簡単です。なぜなら、MRZ 領域はすでに分割されているので、その領域を文字認識モデルに入力するだけで最終的な結果が得られるからです。
この段階ではいくつかの設計アプローチがあります:
-
文字列を分割し、個別に認識:
一部の MRZ は 2 行の文字で構成されています(例:TD2 および TD3 フォーマット)。一方で、3 行の文字列が含まれる MRZ(例:TD1 フォーマット)もあります。これらの文字列を個別に分割し、各部分を認識します。
認識モデルは、文字列の画像をテキストに変換する必要があります。利用できる手法としては、初期の人気であった CRNN+CTC や、現在人気のある CLIP4STR などが考えられます。
この方法にはいくつかの欠点があります。例えば、MRZ 領域が 2 行または 3 行に分かれているため、判定ロジックを追加する必要があります。また、MRZ が狭い間隔で配置されている証明書もあり、その場合文字を識別するのが難しくなることもあります。
ヒント関連する論文に興味がある方は、以下の文献を参照してください:
-
MRZ 全体の画像を一度に認識:
MRZ 領域の縦横比が大きく変わることはないため、MRZ 領域を一度に切り取って、そのまま全体を認識することができます。この場合、特に Transformer ベースのモデルを使うのが適しています。
例えば、Transformer Encoder 構造だけを使用する場合、モデルの設計は次のようになります:
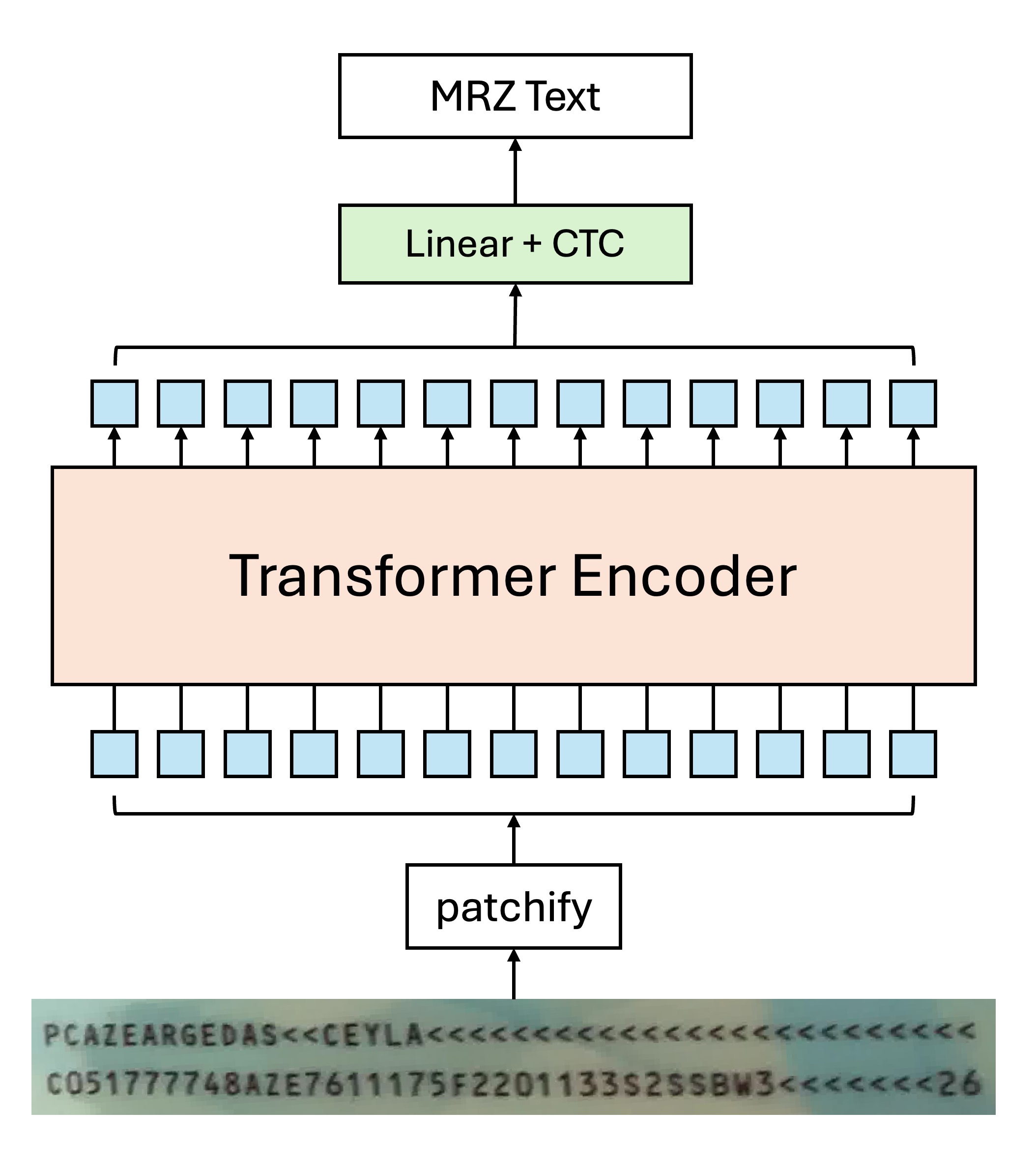
自己注意機構により、複数のトークンが同じ文字に向かって指示を出す場合があります。その際、通常のデコード方式を使うと、モデルが混乱する可能性があります:
この文字の画像なのに、なぜ別の文字をデコードするのか?
実験を通して、ここでは CTC 方式を使って文字をデコードするのが最も効果的であることが分かりました。なぜなら、各トークンは「ある」文字の画像領域から来ているため、最終的な出力結果を統合することで最終的な文字認識結果が得られるからです。
もちろん、CTC が煩わしいと感じる場合は、Encoder-Decoder 構造を使用することもできます。この場合、モデル設計は以下のようになります:
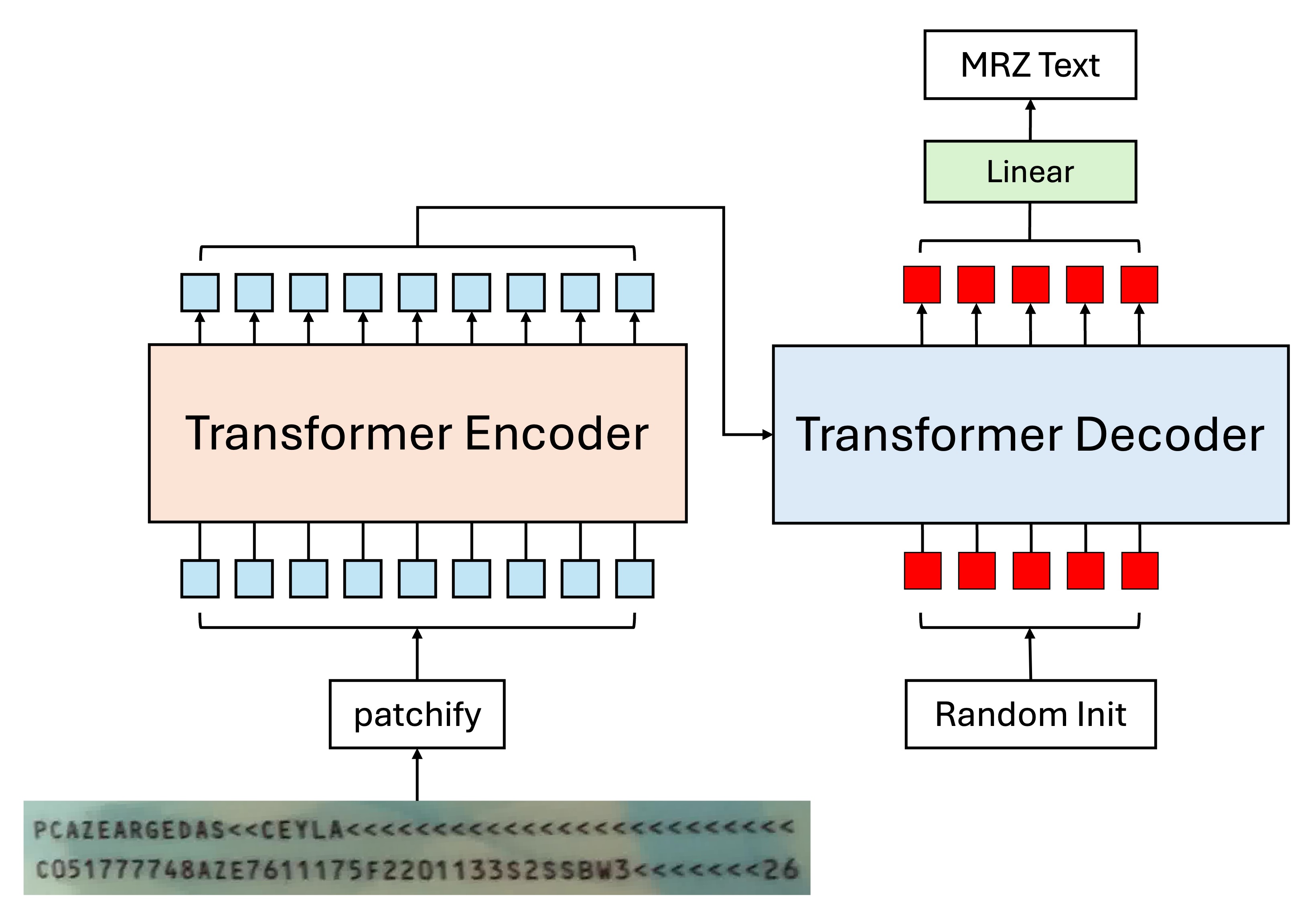
この方法では、文字列を直接デコードでき、CTC を挟む必要はありません。Decoder に渡されるトークンは文字の「検索」に対応しており、各トークンは順番に対応する文字を見つける役割を果たします。
ヒントここでの Decoder は並列で出力できます。自己回帰的な方法を使用する必要はありません。
思い返してみると、自己回帰的な方法を使用する理由は「前回の予測結果を基に次の予測を行う」ことですが、ここではそのような操作は必要ないことが明らかです。
なぜなら、MRZ の各文字は独立しており、最初の位置で予測される文字が何であれ、次の位置での予測結果には影響を与えません。すべての客観的な結果は Encoder の出力結果に既に含まれており、Decoder の仕事はそれらを検索して出力するだけです。
実際に並列出力と自己回帰のトレーニング方法をテストした結果、並列出力の方が収束速度が速く、パフォーマンスも良好で、汎化能力も高いことが確認されました。
誤差伝播
この時点で、コーナーの問題について再度議論できます。
すべての二段階モデルは共通の問題に直面します:誤差伝播。
私たちは、世の中に 100%正確なモデルが存在しないことを理解しています。なぜなら、統計母集団を完全にモデル化することはできず、どんな規則にも例外があるからです。どんなモデルにも誤差があるということです。
- コーナーの予測が不正確であること
コーナーの予測が不正確であるため、補正された MRZ 領域も不正確になります。MRZ 領域が不正確であるため、文字認識も不正確になります。これが誤差伝播の典型的な例です。
単段階認識モデル
単段階認識の主な課題は、多スケール特徴です。
MRZ 領域は、ユーザーの撮影角度によって変化するため、文字検出を行う前に、画像を多スケールで処理する必要があります。
モデルアーキテクチャ
Backbone
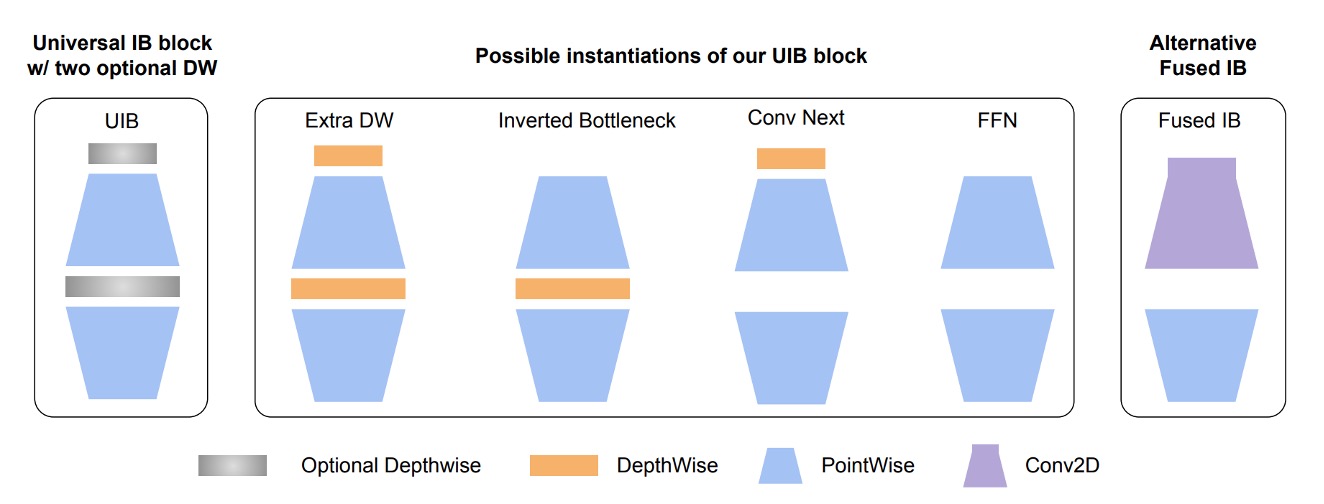
最近、Google が新しい論文MobileNet-V4を発表しました。このモデルはモバイルデバイス向けに最適化されており、私たちにとって非常に良いニュースです。これをそのまま利用します。
今回は、これをバックボーンとして使用し、timm の事前学習済みの重みを使用し、入力画像サイズは 512 x 512 の RGB 画像に設定します。
テスト結果によると、画像解像度が 512 x 512 の場合、各 MRZ の文字サイズはおおよそ 4~8 ピクセルです。解像度を下げすぎると、MRZ 領域の文字がぼやけ、認識精度が低下します。
Neck
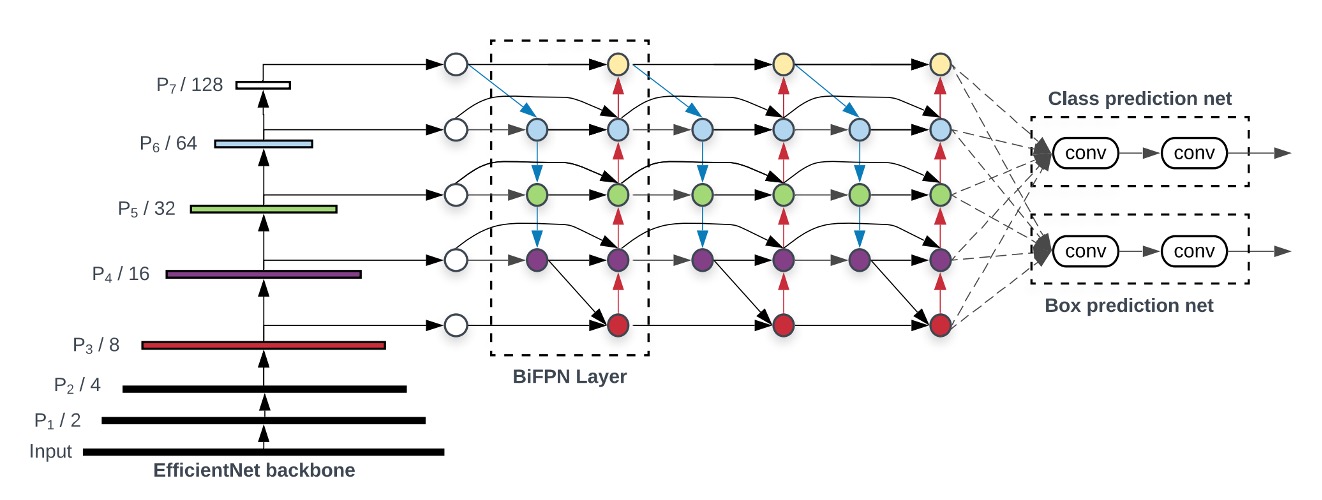
多スケール特徴をより良く融合するために、BiFPN を導入しました。コンテキスト情報が双方向に流れることで、特徴の表現力が強化されます。BiFPN は多尺度で語義が強い特徴マップを生成し、異なるスケールのオブジェクトを捉えるのに非常に効果的です。この特徴マップは最終的な予測精度に良い影響を与えます。
実験では、この部分を取り除いてバックボーンから直接特徴マップを使用しましたが、トレーニングがうまくいきませんでした。
Patchify
ここからは、私たちの独自のアイデアが入ってきます。
まず、各ステージの特徴マップを Transformer の入力形式に変換する必要があります。ここでは通常の畳み込み操作を使用し、特徴マップを個別のパッチに変換しています。
以下は私たちの設定のいくつかです:
-
パッチサイズ:4 x 4。
MRZ 領域内の文字サイズを手動で測定した結果、小さい文字は約 4~8 ピクセルです。それより小さくすると文字が読めなくなります。大きい文字は撮影距離に依存するため、サイズが固定されていません。このため、パッチサイズは 4 x 4 に設定しました。
-
各特徴マップに対応するパッチ埋め込みと位置埋め込みが一組ずつある。
各特徴マップのスケールが異なるため、共通の埋め込みを使うことはできません。共通の埋め込みを設計することも考えましたが、実装が難しいため、現在はこのアイデアを放棄しています。
私たちは共有された重みを用いたパッチ埋め込みを試しましたが、効果が薄かったです。
Cross-Attention
最後に、文字認識のために Cross-Attention を使用しました。
93 個のトークンをランダムに初期化しました。
- なぜ 93 個なのか?
これは、最長の MRZ 形式である TD1 が 90 文字で構成されているためです。さらに、TD1 には 3 行があり、2 つの「区切り」文字が必要です。最後に、「終了」文字が必要で、合計で 93 個です。
接続文字は&、終了文字は[EOS]としました。余った位置には[EOS]を配置し、その後の文字は監視せず、モデルが予測した内容をそのまま受け入れます。
Transformer デコーダーの基本設定は以下の通りです:
- 次元数:256
- 層数:6
- 注意力ヘッド数:4
- ドロップアウト:0
- 正規化:Post-LN
このアーキテクチャの主な設計理念は、「多スケール」特徴空間をデコーダーに提供することです。これにより、デコーダーは異なるスケールの特徴を自由に選択して文字認識を行えます。
さらに続きます
実験中にいくつか記録したことがあり、ここで共有します。これが参考になるかもしれません。
-
64 次元と 128 次元のモデルは収束しますが、次元を半分にするたびに収束速度が倍増します。
私たちのトレーニング機器は RTX4090 で、256 次元モデルのトレーニングに約 50 時間、128 次元のモデルで 100 時間、64 次元のモデルで 200 時間かかりました。
512 次元は試しませんでした。なぜなら、そうするとモデルが大きすぎて 100MB を超えてしまうからです。
-
追加の分岐(例えばポリゴンや文字の中心位置)を追加すると、モデルの収束速度が向上します。
しかし、実際には使いにくいです!データ収集がすでに難しく、MRZ 領域を見つけてそのデータにラベル付けする作業が大変です。
最終的に収束結果は似ており、全体の貢献度は大きくありません。
-
Neck を取り除く。
収束は可能ですが、時間が 3 倍かかります。慎重に考える必要があります。
-
位置エンコーディングを取り除く。
収束しません。
-
Weight Decay をからに調整。
収束は早くなりますが、汎化能力が低下します。
小さなモデルは自然に正則化効果があるため、強い Weight Decay は必要ありません。
-
Pre-LN を使用。
収束は早くなりますが、汎化能力が低下します。
Pre-LN はモデルの深さをある程度制限するため、小さなモデルには向いていません。
-
さらに多くの画像増強を行う。
実験を加速するため、MRZ 画像の回転角度を ±45 度に制限しました。
全方位の回転やその他の画像増強を試しましたが、この規模のモデルではこれほど多くの画像増強には耐えられず、収束しませんでした。
結論
現時点では、単一段階モデルの設計にはいくつか重要な要素が欠けており、今後さらに多くの文献を読み、実験を重ねていく必要があります。
モデルの規模を大きくすることが最も効果的な方法であると思われますが、「軽量」なパラメータ規模でこれらすべての要件を満たす方法を考える必要があります。
ただし、先に述べたように、二段階の解決策を使用すれば、ほとんどすべてのシナリオで安定した結果が得られます。実際に取り組みたいのであれば、二段階モデルを開発することをお勧めします。