データセットの提出
現実の世界はさまざまな状況があり、時には私たちのモデルがうまく対応できない場合があります。
私たちのモデルも同様で、すべてのケースに対応できるわけではありません。
もし使用中に、特定の状況で私たちのモデルが正しく処理できないことに気づいた場合は、ぜひデータセットを提供してください。提供されたデータセットを基に、モデルの調整と最適化を行います。
データセットを提供していただけることに感謝し、すぐにテストと統合を行います。
フォーマット説明
データセットの提出形式の例は以下の通りです:
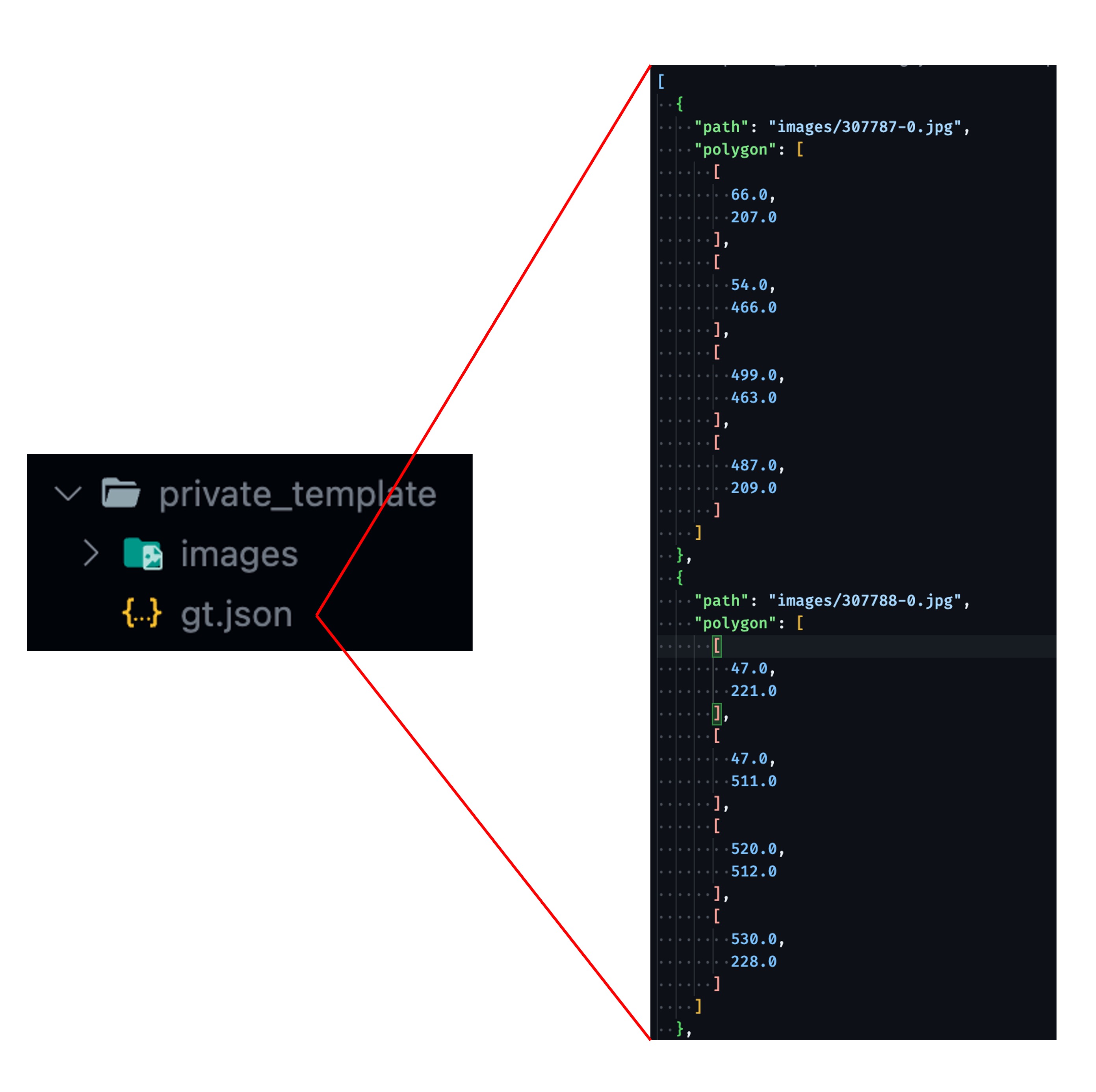
まず、収集した画像が含まれているデータセットがあり、同じディレクトリ内に gt.json ファイルがあり、その中には各画像のラベルが含まれています。
ラベルのフォーマットは以下を含む必要があります:
- 画像の相対パス
- 画像内の文書の「四つの角点のポリゴン」境界
簡単なデータの形式は以下のようになります:
[
{
"file_path": "path/to/your/image.jpg",
"polygon": [
[
[0, 0],
[0, 1080],
[1920, 1080],
[1920, 0]
]
]
}
]
データのラベリングが完了したら、Google Drive にアップロードし、メールでリンクを送ってください。データを受け取った後、できるだけ早くテストと統合を行います。もし提供されたデータが私たちの要件に合わない場合は、すぐにお知らせします。
-
要件に合わない理由としては:
-
データセットの精度が不足している:
例えば、データセット内の一部の画像のラベルが不正確であったり、間違ったラベルが付けられている場合。
-
データセットのラベルが不明確:
私たちが解決しようとしている問題は、画像内の文書の四つの角点を特定することです。したがって、データに「複数のターゲット」や「四つ以上の角点」が含まれている場合は使用できません。
-
ターゲットが小さすぎる:
もしターゲットが小さすぎる場合、アルゴリズムの選定を再検討することをお勧めします。私たちのモデルは小さなターゲットには適しておらず、後処理においても効率が悪くなります。
-
データセットの規模が過度に精緻すぎる:
たとえデータが数十枚であっても、過度にフィットしてしまう可能性があるため、私たちはデータセットの規模を増やして、過度なフィッティングを防ぐことをお勧めします。
-
上記で示したデータ形式と命名規則は厳格ではありません。基本的に画像のパスとポリゴン境界が含まれていれば問題ありませんが、テストを簡単に行うために、できるだけ上記の形式に従ってください。
ラベルデータにはLabelMeを使用することをお勧めします。これはオープンソースのラベリングツールで、画像にラベルを付けて JSON ファイルとしてエクスポートできます。
よくある質問
-
四つの角点の順番は重要ですか?
- 重要ではありません。私たちのトレーニングプロセスは自動的にこれらの角点を並べ替えます。
-
ラベルフォーマットの要件は何ですか?
- フォーマットの要件は厳格ではなく、画像のパスとポリゴン境界が含まれていれば問題ありません。しかし、テストを容易にするために、標準的な形式に従うことをお勧めします。
-
ファイル名の重要性はどの程度ですか?
- ファイル名は主な焦点ではありません。画像が正しくリンクされていれば問題ありません。
-
画像フォーマットに関するおすすめはありますか?
- 空間を節約するために、jpg フォーマットを使用することをお勧めします。
-
ラベルの精度はモデルのトレーニングにどのように影響しますか?
- ラベルの精度は非常に重要です。不正確なラベルはモデルのトレーニング結果に直接影響します。
-
ラベルのターゲットタイプは重要ですか?
- はい、非常に重要です。
- ターゲットは文書でなければならず、各画像には一つのターゲットしか含まれていない必要があります。
-
ターゲットのサイズはモデルのトレーニングにどのように影響しますか?
- ターゲットのサイズは非常に重要です。私たちのモデルは小さなターゲットには適しておらず、後処理の効率に影響を与えます。
-
「小さなターゲット」とはどのように定義されますか?
- 例えば、1920x1080 解像度の画像で、ターゲットが 32x32 ピクセル未満であれば小さなターゲットと見なします。具体的な計算式は
min(img_w, img_h) / 32です。
- 例えば、1920x1080 解像度の画像で、ターゲットが 32x32 ピクセル未満であれば小さなターゲットと見なします。具体的な計算式は
お問い合わせ
もしさらにサポートが必要な場合は、以下のメールアドレスまでご連絡ください:docsaidlab@gmail.com