モデル設計
私たちは過去の研究文献を参考にし、まずは点回帰モデルを検討しました。
点回帰モデル
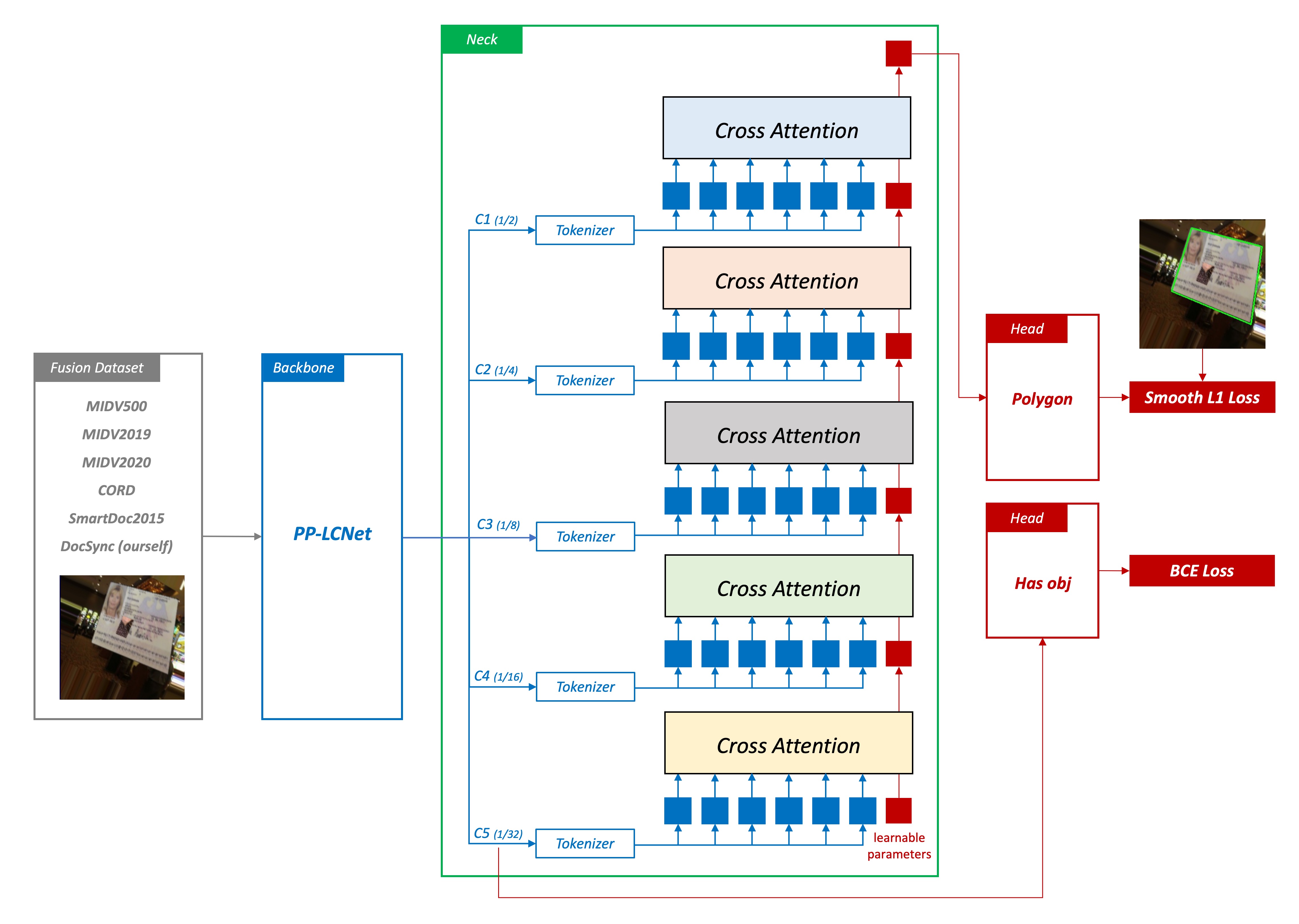
点回帰モデルは私たちの最初期のバージョンであり、その基本構造は 4 つの部分に分かれています:
1. 特徴抽出
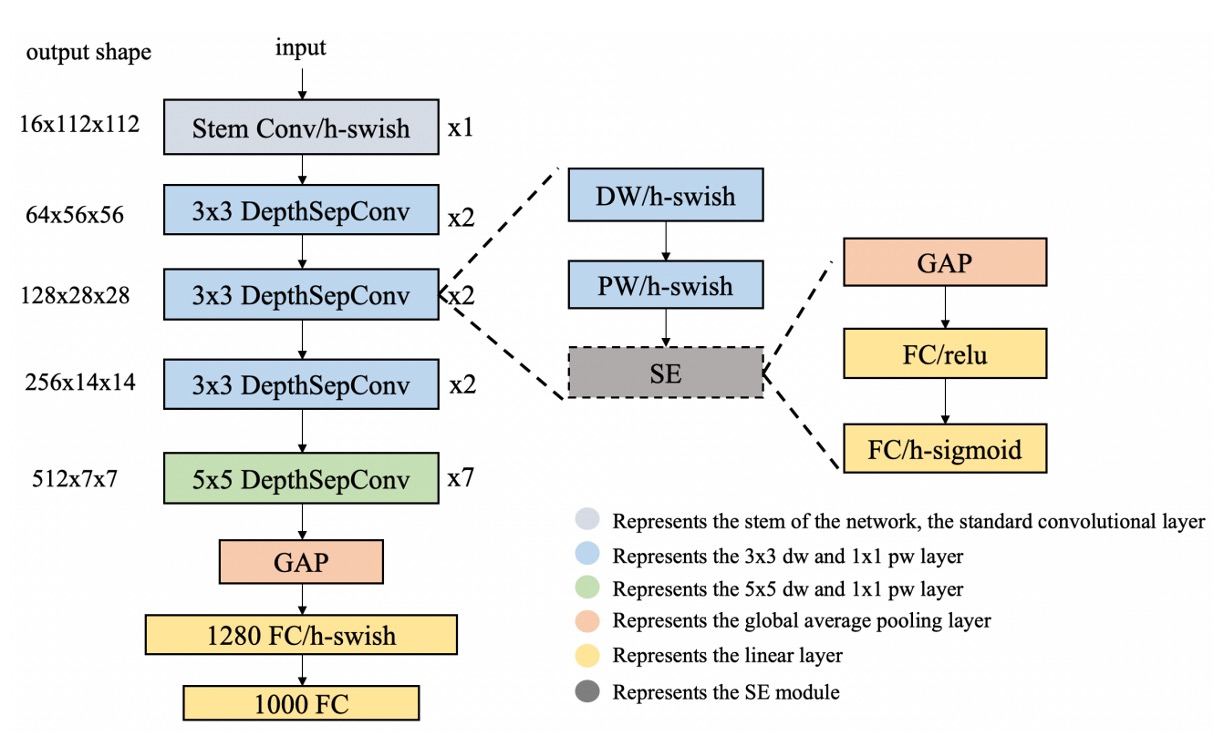
この部分は、画像をベクトルに変換するために使用され、特徴抽出器として PP-LCNet を使用しています。
入力画像は 128 x 128 の RGB 画像で、特徴抽出器を通した後、256 次元のベクトルが出力されます。
なぜ LCNet を使用するのですか?
私たちはモデルをモバイルにデプロイすることが多いため、LCNet は非常に軽量なモデルであり、モバイルでの運用に適しています。また、モデルを量子化する必要がある場合、LCNet は計算子がサポートされない問題が少ないため、便利です。
2. Cross-Attention
このモデルでは、Neck 部分はバックボーンから出力された特徴を強化するために使用されます。
このモデルでは、Cross-Attention メカニズムを使用しています。これは Transformer でよく使われるメカニズムで、異なる特徴間の関係を捉え、それらの関係を特徴の強化に適用します。Cross-Attention は、画像内の異なる点間の空間的関係を理解するのに役立ち、予測精度の向上を期待しています。Cross-Attention のほかにも、位置エンコーディング(positional encodings)を使用しており、これによりモデルは画像内の点の空間位置を理解し、予測精度が向上します。
点回帰の特徴を考慮し、精密なピクセル位置決定は低レベルの特徴に非常に依存しているため、私たちは深層特徴から始め、次に浅層特徴(1/32 -> 1/16 -> 1/8 -> 1/4 -> 1/2)でクエリを行います。この設計により、モデルは異なるスケールの特徴で文書の位置を見つけることができます。このクエリ方法がモデルの精度を効果的に向上させると考えています。
3. 点回帰
予測ヘッドの設計では、単純な線形層をヘッドとして使用し、特徴を点の座標に変換しています。モデルが Cross-Attention による特徴の表現力に依存することを期待しており、複雑なヘッド構造には頼らないようにしています。
4. Smooth L1 Loss
私たちのモデルでは、損失関数として Smooth L1 Loss を選択しました。これは回帰タスクでよく使用される損失関数で、異常値の影響がある場合に特に有用です。
L1 Loss と比べて、Smooth L1 Loss は予測値と実際の値の差が大きいときにより頑健で、異常値の影響を減らします。また、点回帰の拡大誤差を抑えるために、点の予測の重みを「1000 に増加」させました。私たちの実験によると、この設計はモデルの精度を効果的に向上させることができます。
角点の損失に加えて、他の損失も使用しています:
- Classification Loss: これは分類用の損失関数で、画像に文書が存在するかどうかを予測します。BCE Loss を使用しています。
注意すべきは、この分類損失は補助的な損失に過ぎず、主要な損失の 1 つであるということです。角点予測自体の制限により、ターゲットオブジェクトがない場合でも角点を予測することがあり、デプロイ時には分類ヘッドを使用して、対象物が存在するかどうかを確認する必要があるからです。
災難的失敗
「点回帰モデル」のアーキテクチャでは、非常に深刻な「拡大誤差」の問題に直面しました。
この問題の根本的な原因は、私たちがモデルのトレーニング中に、元の画像を 128 x 128 または 256 x 256 に縮小する必要があることです。この縮小プロセスにより、元の画像の詳細情報が失われ、モデルが予測時に文書の角点を正確に見つけることができなくなります。
正確に言うと、モデルは縮小された画像に基づいて角点を見つけます。
そして、これらの角点を元の画像のサイズに拡大しないと、元の画像での角点位置を見つけることができません。
このような拡大プロセスにより、角点の位置におおよそ 5〜10 ピクセルの偏移が生じ、モデルが文書の位置を正確に予測できなくなります。
想像してみてください:元の画像で目標角点が周囲 10 ピクセルの範囲にあると、予測時にその範囲が 1 ピクセルに縮小されます。その後、モデルが予測を行い、最後に拡大プロセスで角点の位置がずれてしまうというわけです。
他の人はどうしているか?
この問題に直面した後、私たちは他の研究者がどのように解決しているかを意識的に調べました。
その結果、この分野(Document Localization)の多くの文献では、解決策として以下の方法が示されています:
大きな画像で予測
この方法は、モデルが予測時に文書の角点を正確に見つけることを保証できます。
しかし、とても遅いです。非常に遅いです。
アンカーポイントとオフセットを導入
アンカー(Anchor-Based)方式は物体検出分野から参考にすることができ、アンカーのサイズを定義するために事前知識が必要です。しかし、文書は画像内で任意の角度や変形を持つ可能性があり、アンカー設計はモデルの検出能力を一定の範囲に制限することになります。
基本的に、アンカー構造に関する知識を持っていれば、その優缺点をここに再度書くことができます。
現実世界の文書のアスペクト比は非常にランダムであり、アンカー設計には適していません。
評価データセットに直接適合
初期の論文では、SmartDoc 2015 に特化したアルゴリズムが設計されており、汎用的なモデルの設計ではなくなっています。
近年の論文では、SmartDoc 2015 を自分でトレーニングデータとテストデータに分け、その方法で SmartDoc 2015 のスコアを向上させる方法が取られています。
したがって、ベンチマーク結果では多くの構造が良いスコアを示していますが、実際のアプリケーションでは十分な一般化能力を持っていないことがわかります。
この分野の研究者は、この問題の解決方法に関して統一した見解を持っていないことがわかりました。
ヒートマップ回帰モデル
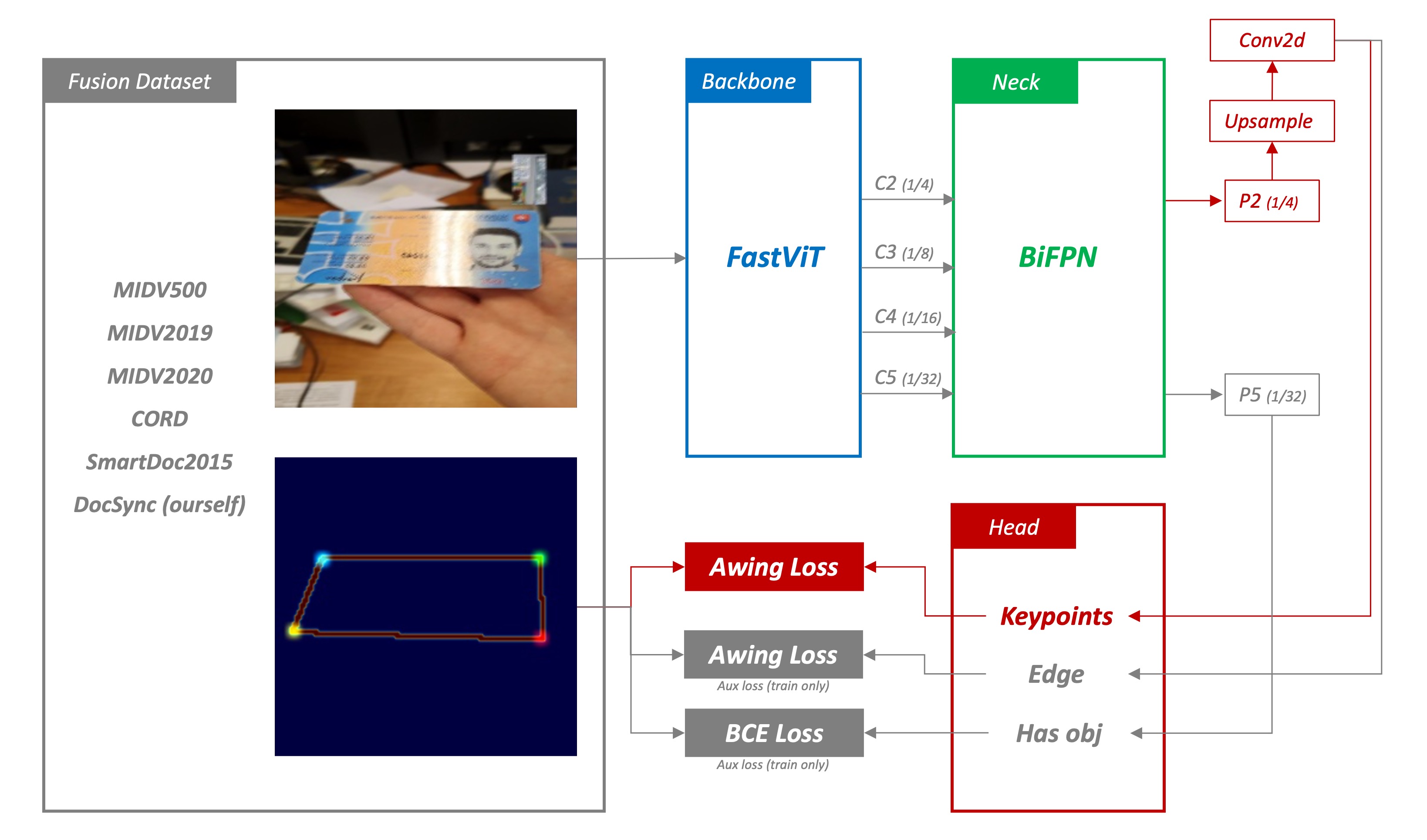
このモデル構造は、元の特徴抽出器を使用しつつ、Neck と Head 部分を修正しました。
1. 特徴抽出
LCNet を使用するモバイル用モデルのほかに、さらに大きなモデルを使用してより多くの特徴を抽出しています。SOTA を超えるモデルを作りたいので、単純に LCNet だけでは不十分だと考えています。
このモデルでは、FastViT や MobileNetV2 などの比較的「軽量」な畳み込みニューラルネットワークを使用しています。計算リソースが制限された環境でも高効率な特徴抽出が可能です。Backbone は入力データから十分な特徴情報を抽出し、その後のヒートマップ回帰に備えます。
2. BiFPN
次に、異なるスケールの特徴をより効果的に融合するために、BiFPN(双方向特徴ピラミッドネットワーク)を導入しました。これにより、上下文情報の双方向の流れを通じて特徴の表現能力を強化します。BiFPN は異なるスケールのオブジェクトを捉えるのに非常に有効であり、最終的な予測精度に良い影響を与えると考えています。
3. ヒートマップ回帰
先述の拡大誤差を解決するために、予測結果に一定の「ぼやけ」を加えます。つまり、モデルには正確に角点の位置を指定するのではなく、「この角点はおおよそこの領域にある」と予測させます。
そのために、人間の顔の特徴点検出や人体姿勢推定でよく使われる手法であるヒートマップ回帰を採用しました。
ヒートマップ回帰は、物体が異なる位置に現れる可能性を反映した熱マップを生成します。これを分析することで、モデルは物体の位置と姿勢を正確に予測できます。私たちのケースでは、ヒートマップは文書の角点を見つけるために使用されます。
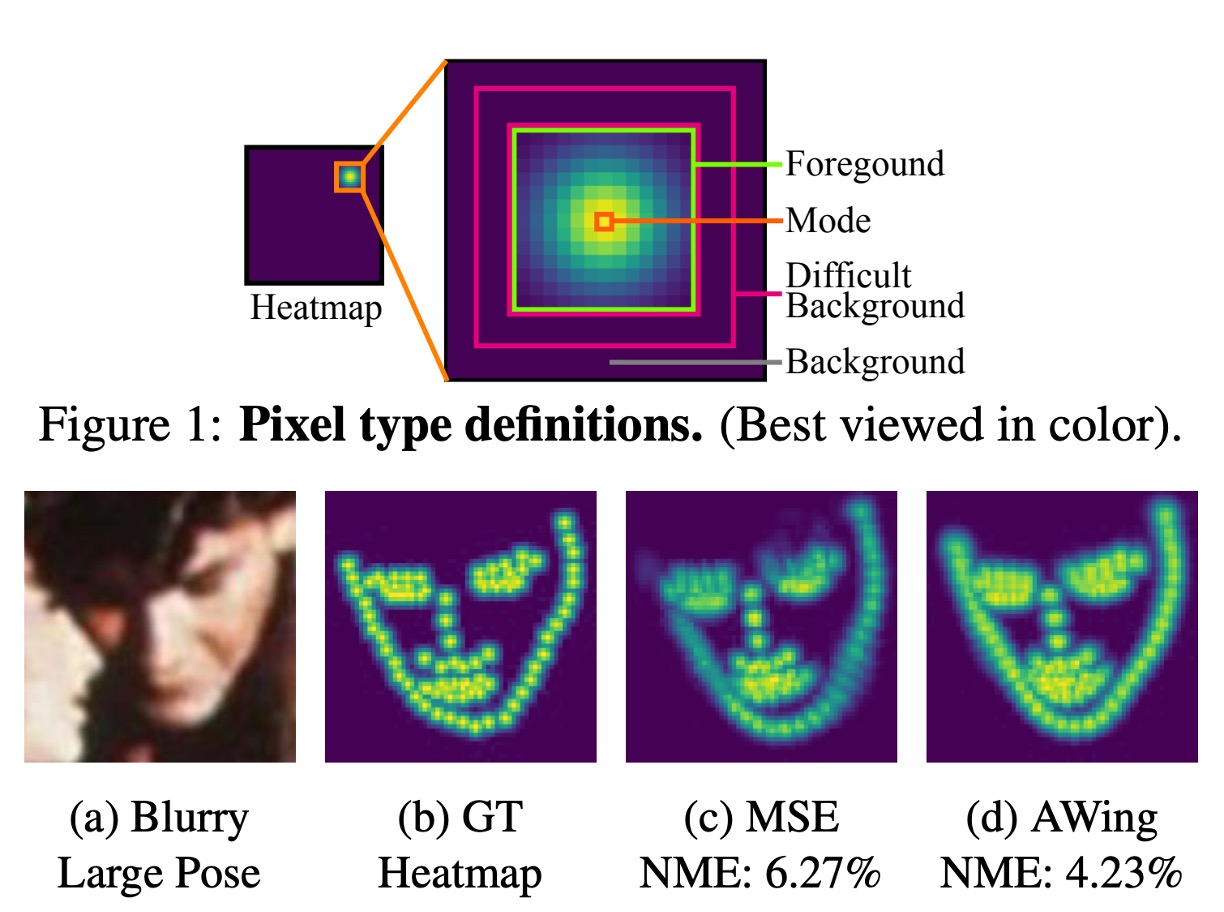
4. Adaptive Wing Loss
Loss はモデルのトレーニングにおいて重要であり、予測結果と実際のラベルの差を計算します。
このモデルでは、Adaptive Wing Loss を使用しています。これは顔の特徴点検出に特化した損失関数で、ヒートマップ回帰の損失関数に革新を加えたものです。この方法は、前景のピクセル(顔の特徴点近くのピクセル)に強いペナルティを、背景のピクセルには少ないペナルティを与えることによって、より精度の高い予測を実現します。
ここでは、文書の角点予測の問題を顔の特徴点検出の問題として扱い、専用の損失関数を使用しています。この方法は、文書角点の検出問題を効果的に解決し、異なるシーンで良好な結果を得られると考えています。
角点の損失に加え、他にもいくつかの補助的な損失を使用しています:
- Edge Loss: 物体の境界情報を監視するために、AWing Loss を使用しています。
- Classification Loss: 画像に文書が存在するかどうかを予測するために、BCE Loss を使用しています。
拡大誤差の解決
ヒートマップ回帰モデルの出力はヒートマップであり、このヒートマップは文書の角点がどのあたりにあるかを示します。
次に、このヒートマップをそのまま使うことはできません。なぜなら、このヒートマップは縮小されたものであるため、実際には次のようにすべきです:
- ヒートマップを元の画像のサイズに拡大します。
- 画像後処理を行い、各熱点に対応する角点領域のコンターを見つけます。
- コンターの質心を計算し、この質心が文書の角点です。
このようにして、モデルは角点を正確に見つけ、先述の拡大誤差の問題を解決できます。
結論
ヒートマップモデルのアーキテクチャには明確な欠点があります:
- エンドツーエンドモデルではない
これが私たちがモデルを設計する際に常に考えている問題です。ユーザーにとって簡単で、モデルが各コンポーネントを学習できるエンドツーエンドモデルを設計したいのです。しかし、点回帰モデルで直面した問題を考慮し、ヒートマップ回帰モデルの設計方法を使用することに決めました。
結局のところ、完璧ではありませんが、少なくとも拡大誤差の問題は解決しました。
私たちのヒートマップモデルの実験では、より大きなバックボーンや複雑なネックを使用することで、モデルの精度を向上させることができました。
デプロイ段階では、使用シーンにおける計算能力の制限を考慮して、適切なモデルを選択するだけで済みます。