[24.10] YOLOv11

Engineering-Optimized Edition
YOLOv11: An Overview of the Key Architectural Enhancements
It's rare for Ultralytics to publish a paper whenever they release a new architecture.
In any case, we should give them some encouragement.
Problem Definition
In the realm of object detection, the name YOLO has been around for a decade.
Back in 2015, Redmon came up with the slogan: "You Only Look Once." He decisively ditched the mainstream two-stage detection architecture, boldly redefining detection as a regression problem—combining classification and localization in a single shot.
Since then, each generation of YOLO has become synonymous with "real-time detection."
However, as the YOLO family evolved, two core issues have become apparent:
- The Performance-Speed Dilemma: Small models are fast but inaccurate; large models are accurate but slow.
- Multi-task Integration: Tasks like detection, segmentation, pose estimation, and rotated bounding boxes are often required in real-world applications, but past versions could never truly integrate them all.
So, the Ultralytics team has tried to push YOLO forward into an all-in-one vision system.
Oh? Is that really possible? Let’s take a look.
Problem Solving
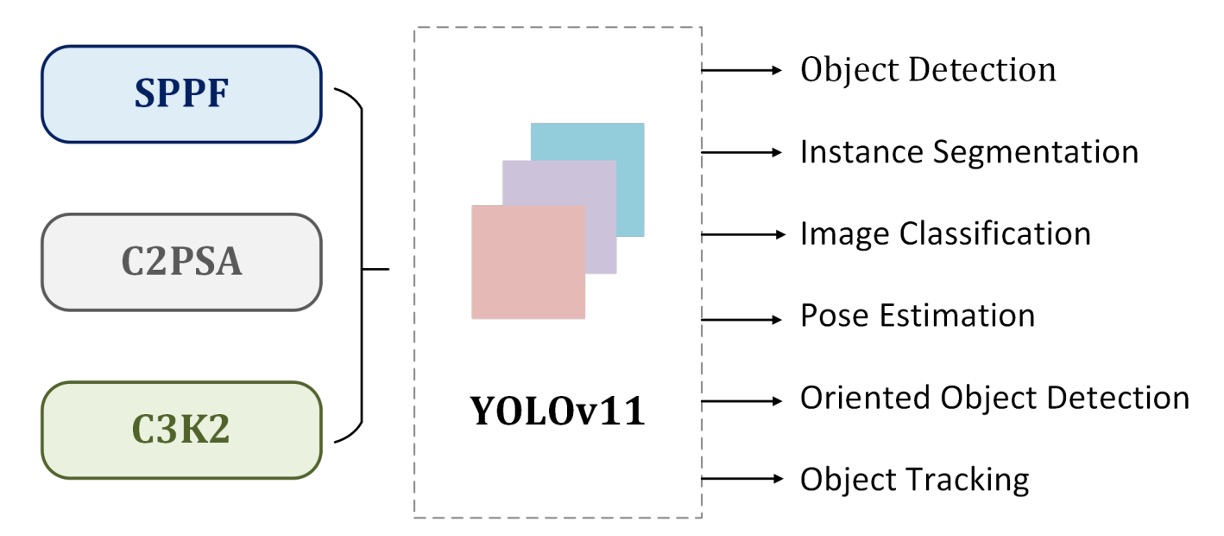
YOLOv11 continues the design foundations of YOLOv9 and YOLOv10. The overall architecture still follows the classic three-stage structure:
- Backbone → Neck → Head
There are no radical overhauls here, but with several local tweaks, they attempt to achieve more stable performance in both speed and accuracy.
Backbone: Minor Replacement
-
C2f → C3k2
The previously common C2f block is now replaced by the new C3k2 block.
The purpose of this change is purely to pursue "faster and more efficient" performance: breaking large convolutions into smaller ones, using smaller kernels to reduce computation and the number of parameters. In practice, C3k2 delivers a better latency-accuracy tradeoff, providing more efficiency without sacrificing too much accuracy.
tipLet’s visualize the architecture—the overall structure remains mostly the same.
Essentially, the stacked Bottleneck modules have been replaced by the C3k module.
C2f
C3k2
-
SPPF + C2PSA
After the SPPF module, a C2PSA (Cross Stage Partial with Spatial Attention) is added.
This allows the model to focus a bit more on critical areas of the image, which is helpful for small objects or occluded items.
However, this type of attention design isn’t particularly novel—it's more of a "keeping up with the trend" kind of choice.
tipAs usual, let’s also visualize this new C2PSA module.
C2‑PSA
PSA(Position‑Sensitive Attention)
ConvAttention(PSA 內部 MHSA 細節)
Neck: Minor Feature Fusion Tweaks
The neck’s role is still to bring together features at different resolutions.
Here, YOLOv11 also switches to the C3k2 block, combined with C2PSA, to make the fusion process slightly more efficient.
Overall, these changes make YOLOv11’s speed-accuracy curve look a bit better than v8 or v9.
Head: Extended Output Layer
For the head, YOLOv11 doesn’t drastically change the structure—just continues to use the C3k2 block and CBS (Conv-BN-SiLU), finally outputting bounding boxes, objectness scores, and classification results.
Multi-Task Integration
Compared to previous versions, the most significant change in YOLOv11 isn’t in the detection architecture itself, but in its official positioning as a "multi-task framework."
As shown in the table below:
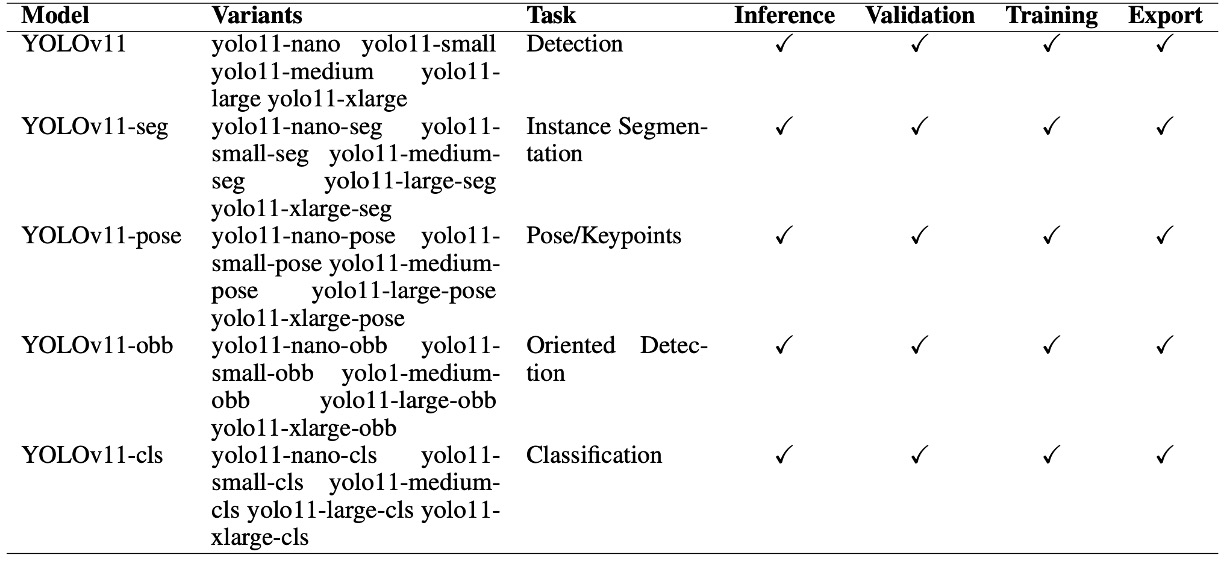
Beyond standard object detection, Ultralytics now includes segmentation, pose estimation, rotated bounding boxes (OBB), and classification—all in a unified system, with the same inference, validation, training, and export interfaces.
In practical terms, this integration is meaningful. For researchers or industry developers, it used to be necessary to rely on separate toolchains or scattered implementations for detection, segmentation, pose, and so on. Now, with YOLOv11’s unified version, it can all be done in one place.
However, note that YOLOv11 isn’t the state-of-the-art in accuracy for every task; more often, it maintains a “usable and consistent” standard.
In other words, its strength isn’t peak performance in a single task, but rather the convergence of various computer vision needs into a single entry point, forming a relatively stable multi-task ecosystem. This positioning also aligns with Ultralytics’ product strategy, making the YOLO series applicable across a broader range of real-world scenarios.
Discussion
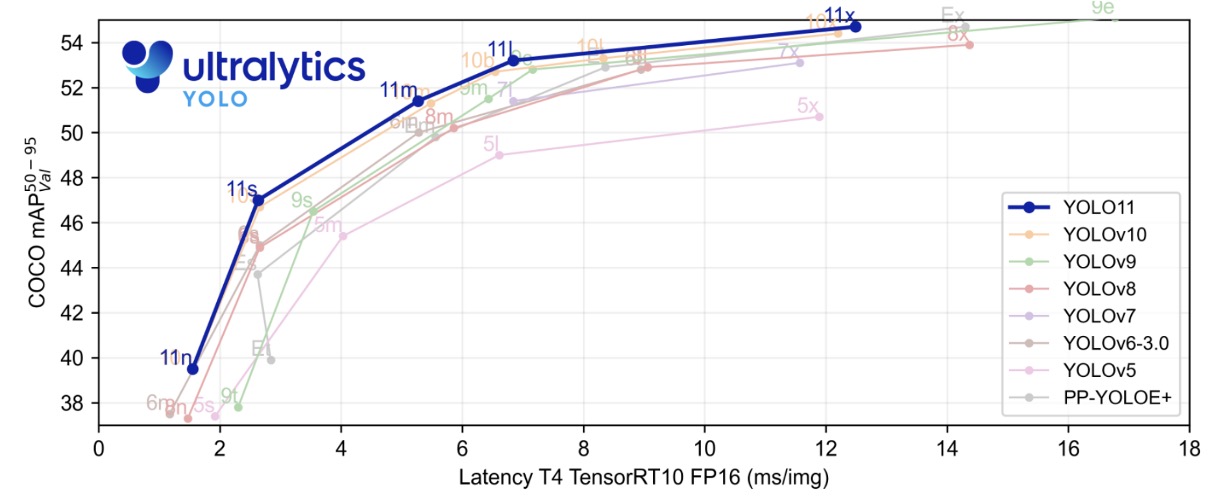
Looking at the official benchmark, YOLOv11 does appear neater on the speed-accuracy curve than previous generations.
Models of various sizes (n, s, m, x) achieve slightly higher mAP on COCO than YOLOv8, YOLOv9, and YOLOv10, while maintaining relatively low latency. Notably, YOLOv11m achieves accuracy close to YOLOv8l, but with fewer parameters and lower FLOPs, demonstrating real effort in efficiency optimization.
In the high-latency range, large models like YOLOv11x can reach about 54.5% mAP@50–95 with inference times around 13ms; in the low-latency range, small models like YOLOv11s can still maintain around 47% mAP within 2–6ms. This distribution allows YOLOv11 to offer suitable model sizes for various real-time requirements—a practical convenience.
Conclusion
After reading this paper, I think YOLOv11’s contribution is more about engineering refinements than methodological breakthroughs.
By switching the backbone, neck, and head entirely to the C3k2 block, it does bring better parameter efficiency and inference speed, with solid results in low-latency scenarios. Still, these changes don’t alter YOLO’s fundamental paradigm—they’re just optimizations of existing designs.
Strictly speaking, the magnitude of these improvements doesn’t quite justify being called a “next-generation architecture”...
But hey, it’s released, so let’s accept it.