[19.09] UNITER

The Song of the Unifiers
UNITER: UNiversal Image-TExt Representation Learning
We've seen previous papers evolve from "single-stream models" to "dual-tower models" and "dual-stream models."
Essentially, you can either combine multimodal information in a single computation or process them separately.
If you process them separately, someone will later try to combine them and surpass you. If you combine them, someone will eventually separate them and surpass you.
We just wanted to casually read some papers, but we've stumbled upon some life lessons.
Now, let's get back to UNITER.
In the field of vision and language (V+L) research, joint multimodal encoding has been widely used to bridge the semantic gap between images and text. However, these multimodal encoding methods and representations are often tailored for specific tasks. This means that methods designed for particular V+L tasks might struggle to adapt to other related tasks. This phenomenon is common in multimodal research, making it challenging for the research community to find a universal solution.
Previous studies, such as MCB, BAN, DFAF, SCAN, and MAttNet, have all proposed advanced methods within their specific domains. However, due to the diversity of these models' architectures and the highly task-specific nature of the learned representations, their application across various V+L tasks has been limited.
Problem Definition
The authors believe that current research, although successful in specific tasks, still faces many issues and challenges in learning generalized multimodal representations, effective masking strategies, and optimized alignment techniques:
-
Task-Specific Multimodal Encoding: Existing visual and linguistic multimodal encoding methods are often designed for specific tasks, limiting the model's generalization ability to other V+L tasks.
-
Diversity of Model Architectures and Representations: Previous studies like MCB and BAN have their unique architectures and representation methods within specific domains. Due to this diversity, these models struggle to adapt to a wide range of V+L tasks.
-
Direct Application of NLP Strategies: Although Transformers and BERT have achieved great success in NLP, directly applying these strategies to the V+L field may not be the optimal solution. Specific strategies and pre-training tasks are needed to ensure success in V+L tasks.
-
Limitations of Masking Strategies: Existing multimodal pre-training methods face challenges in masking strategies. Different masking strategies may affect the learned representations and further impact the performance on downstream tasks.
-
Challenges in Semantic Alignment: Ensuring semantic alignment between images and text is a core challenge in multimodal research. Although previous studies have proposed some methods, fine-grained alignment remains difficult.
The authors raise a central question:
- Can we learn a truly universal image and text representation for all V+L tasks?
Solution
UNITER Model Design
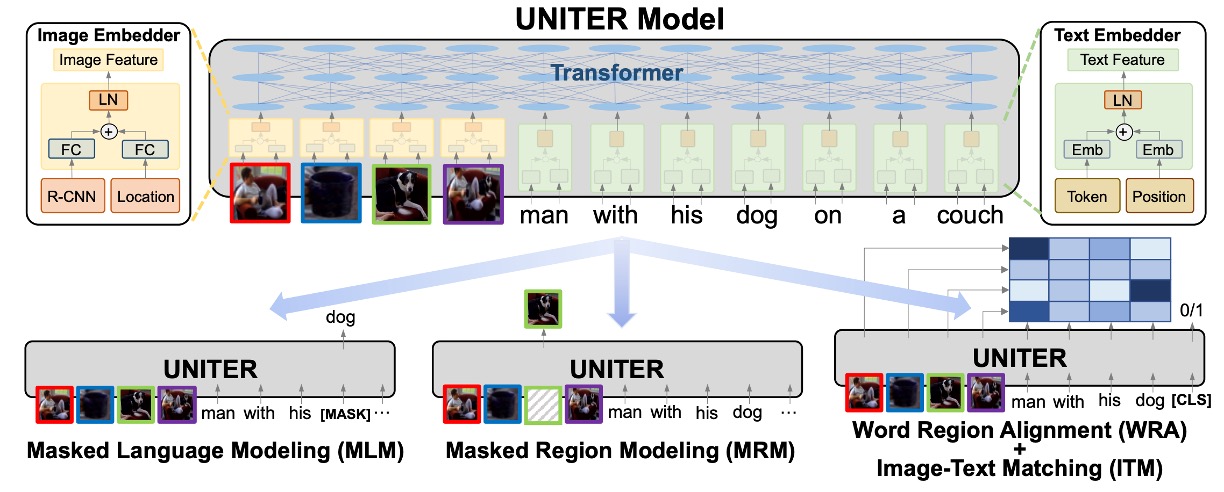
As a solution specifically designed for vision and language tasks, the primary goal of the UNITER model is to effectively bridge the semantic gap between images and text. Below is an in-depth discussion of the main components and ideas of the model's design.
-
Model Architecture
- The basic structure of UNITER consists of an image encoder, a text encoder, and multiple layers of Transformers. This ensures that the model can extract complex features from both images and text, which are then deeply interacted and integrated through the Transformers.
-
Encoding Strategies
- For images, UNITER utilizes Faster R-CNN to extract visual features and encodes each region's positional features through a 7-dimensional vector. These two features are merged via a fully connected layer, ensuring both positional and visual information are considered.
- For text, UNITER follows BERT's strategy, using WordPieces for tokenization and then encoding each token. This ensures effective encoding of word meanings and contextual information.
-
Self-Attention Strategy
- UNITER's Transformers leverage self-attention mechanisms to learn contextual encodings, allowing the model to establish deep associations between different modalities. By explicitly encoding tokens and regions' positions, the model captures more detailed contextual information.
-
Pre-Training Tasks
- A highlight of UNITER is its diverse pre-training tasks, including masked language modeling (MLM), masked region modeling (MRM), image-text matching (ITM), and word-region alignment (WRA). These tasks are designed to enhance the model's cross-modal learning capabilities from multiple angles.
-
Conditional Masking Strategy
- Unlike other pre-training methods, UNITER chooses to mask only one modality while keeping the other intact. This strategy aims to prevent potential modality misalignment during the learning process, ensuring the model more accurately aligns images and text.
-
Word-Region Alignment Strategy
- By introducing a pre-training task based on optimal transport for word-region alignment, UNITER explicitly encourages fine-grained alignment between words and image regions. This strategy ensures the model effectively optimizes cross-modal semantic alignment.
Pre-Training Strategy
The pre-training strategy of the UNITER model is core to its success, designed to address the unique challenges of cross-modal learning. These strategies aim to optimize the model's ability to deeply understand and integrate the interrelationships between images and text.
Let's examine these pre-training strategies in detail:
-
Masked Language Modeling (MLM)
Masked language modeling (MLM) is a pre-training strategy designed to enhance a model's language understanding and cross-modal learning capabilities. Specifically, MLM works by randomly selecting and masking certain words (typically 15% of the words) in the input text and then using the context and any associated auxiliary information (such as images) to predict the masked words.
Imagine a scenario where we have the sentence "The puppy is playing in the [MASK]," accompanied by an image showing a puppy happily playing on a green lawn. In this scenario, the model needs to use the visual information from the image—namely, the puppy on the lawn—to correctly predict the word in the [MASK] position, which is "lawn."
This approach is not merely a fill-in-the-blank game. The underlying idea is to force the model to understand not only the textual context but also the visual content of the image and its association with the text. When the model is trained to optimize this prediction task, it simultaneously learns to understand both the text and the image more deeply and intricately.
-
Image-Text Matching (ITM)
Image-text matching (ITM) is a strategy used to evaluate how well a model can match a textual description to an image. This task is not just about finding matching items; it involves assessing the deep semantic relationship between the text and the image.
To perform this task, the model uses a special token in the input, known as [CLS]. The purpose of this token is to generate a fused representation of the image and the text for the model. This fused representation provides a single perspective from which the model can judge whether the image and the text match.
For example, consider a text description "A beach at sunset" and a photo showing a beach with a sunset. When these are input into the model, the model will generate a fused representation with the help of the [CLS] token. This representation is then passed through a fully connected layer (FC layer) and a sigmoid function to produce a score between 0 and 1. This score indicates how well the text and the image match.
In the training process, along with correctly matched image-text pairs, there are so-called "negative pairs," which are mismatched combinations of images and texts. For instance, the description "A beach at sunset" might be paired with a mountain image. These negative pairs are created by randomly selecting an image or text from other samples and pairing it with the original sample.
The model's goal is to minimize its prediction errors for both the correct and negative pairs. This is usually achieved using binary cross-entropy loss, a common loss function for evaluating a model's binary classification performance.
-
Word-Region Alignment (WRA)
Word-region alignment (WRA) is an advanced strategy that uses optimal transport (OT) to refine the association between textual elements (such as words or phrases) and image regions. The primary goal of this strategy is to ensure that the model can accurately map textual descriptions to their corresponding parts in the image.
For example, given the description "red apple" and an image containing apples of various colors, WRA aims to make the model align "red apple" precisely with the red apple in the image, rather than with the green or yellow apples.
OT provides a robust mathematical framework for achieving this goal, featuring the following characteristics:
- Normalization: This ensures that the sum of all transport values equals 1, regularizing the alignment between the data.
- Sparsity: OT offers a sparse solution for alignment, considering only the most relevant matches, making the alignment more precise and interpretable.
- Efficiency: Although traditional OT methods can be computationally intensive, there are strategies to efficiently solve large-scale problems, which is particularly useful for large model pre-training.
OT works by evaluating the distance between two distributions and optimizing a "transport plan" to describe how to move from one distribution to another. In this paper's context, these two distributions are the text and the image. Once this transport plan is obtained, it can be used as a loss function to update the model parameters, improving the alignment between text and images.
-
Masked Region Modeling (MRM)
Masked region modeling (MRM) is a critical strategy in the UNITER model, specifically targeting the visual features of image regions. Similar to MLM, this strategy randomly selects and masks the features of image regions with a probability of 15%. For instance, if we have an image of multiple birds flying in the sky, MRM might randomly select and mask the features of a few birds. The model's primary task is to use the remaining visual information and relevant textual content to reconstruct or infer the features of the masked birds. This not only strengthens the model's understanding of image regions but also enhances its reasoning capabilities with incomplete information.
There are three main variations of this strategy:
-
Masked Region Feature Regression (MRFR):
This is the most intuitive strategy, aiming to reconstruct the masked visual features. For example, if some birds' features are masked, MRFR will attempt to directly reconstruct the masked birds' features using other birds' features and relevant textual descriptions.
-
Masked Region Classification (MRC):
This strategy is more abstract, attempting to predict the possible classes or characteristics of the masked regions. For instance, if some birds' features are masked, MRC will try to predict which species or type the masked birds might be, based on other information in the image and relevant textual content.
-
Masked Region Classification with KL Divergence (MRC-kl):
This is an advanced version of MRC. Unlike MRC, it does not solely rely on hard labels or the most likely answer but considers multiple possible answers. It uses the original output of an object detector as a form of soft labels, providing probabilities for each object category, and the model then tries to match these distributions.
Pre-Training Datasets
In this paper, the authors meticulously designed a pre-training dataset drawn from four well-known V+L datasets: COCO, Visual Genome (VG), Conceptual Captions (CC), and SBU Captions. The combination of these four datasets ensures that the model is exposed to rich and diverse data during the pre-training phase, thus enhancing its performance on subsequent tasks. However, these datasets are not used indiscriminately. Recognizing that different datasets may have varying impacts on pre-training, the authors categorized them accordingly. Firstly, COCO image caption data and VG dense caption data were combined, labeled as "in-domain" data because many V+L tasks' base datasets are built on them.
When using these "in-domain" data, the authors implemented specific strategies to ensure fairness and uniqueness. For example, given that COCO and Flickr30K images are both crawled from Flickr and may overlap, these overlapping images were excluded. This process ultimately resulted in 5.6 million image-text pairs for training and 131K pairs for internal validation.
In addition to these "in-domain" data, the authors also utilized two extra datasets, Conceptual Captions and SBU Captions, as "out-of-domain" data for pre-training.
Discussion
Performance on Pre-Training Tasks
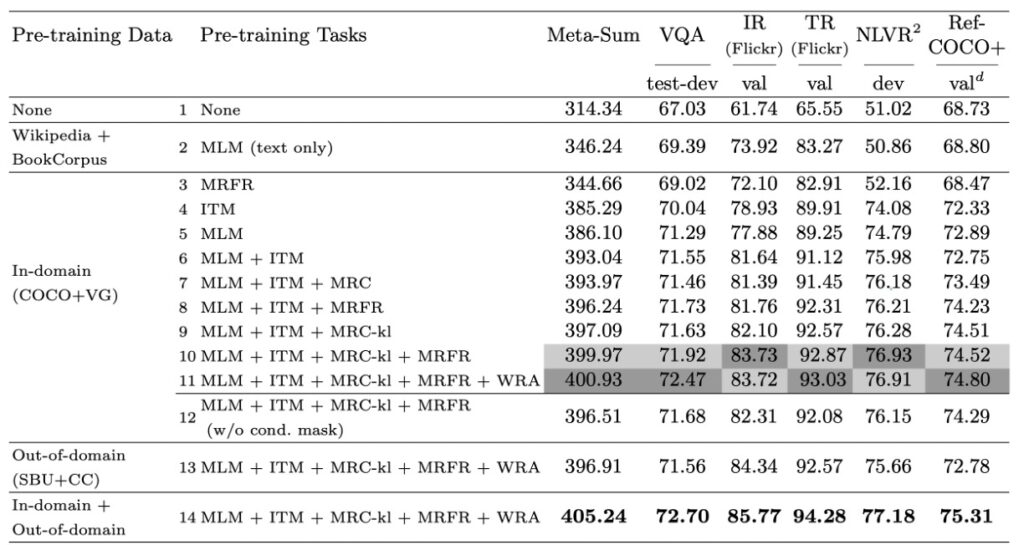
In evaluating the effectiveness of the multimodal pre-training strategies proposed by the authors, they selected four representative V+L benchmarks: VQA, NLVR2, Flickr30K, and RefCOCO+. Additionally, they introduced a global indicator, Meta-Sum, which is the sum of all scores across all benchmarks, providing a comprehensive evaluation perspective.
-
Baseline Settings
The authors first established two baselines. The first baseline (L1) involved no pre-training, while the second baseline (L2) used MLM weights pre-trained only on text. Results indicated that even text-only pre-training significantly improved the Meta-Sum score compared to L1.
-
Effect of Single Pre-Training Tasks
Next, they explored the effect of single pre-training tasks. Specifically, when the model was pre-trained only on ITM (L4) or MLM (L5), there were significant performance improvements across all tasks compared to baselines L1 and L2.
-
Combination of Pre-Training Tasks
The authors further discovered that combining different pre-training tasks, such as MLM and ITM (L6), resulted in better performance than using any single task alone. When MLM, ITM, and MRM were trained together, the model showed consistent performance gains across all benchmarks.
-
Fine-Grained Alignment
Adding the WRA pre-training task (as in L11) led to significant improvements, particularly in VQA and RefCOCO+. This strongly suggests that learning fine-grained alignments between words and regions during pre-training is highly beneficial for downstream tasks involving region-level recognition or reasoning.
-
Conditional Masking Strategy
By comparing different masking strategies, the authors found that the conditional masking strategy allowed the model to effectively learn better joint image-text representations.
-
Impact of Pre-Training Datasets
Finally, the authors explored the effect of different pre-training datasets. Results showed that even pre-training on out-of-domain data could improve model performance as long as the data were similar to the downstream tasks. When pre-training on both in-domain and out-of-domain data, the model's performance further improved.
Through this series of experiments, the authors provided valuable insights into the effects of different pre-training settings, helping us better understand the deep mechanisms of multimodal pre-training.
Performance on Downstream Tasks
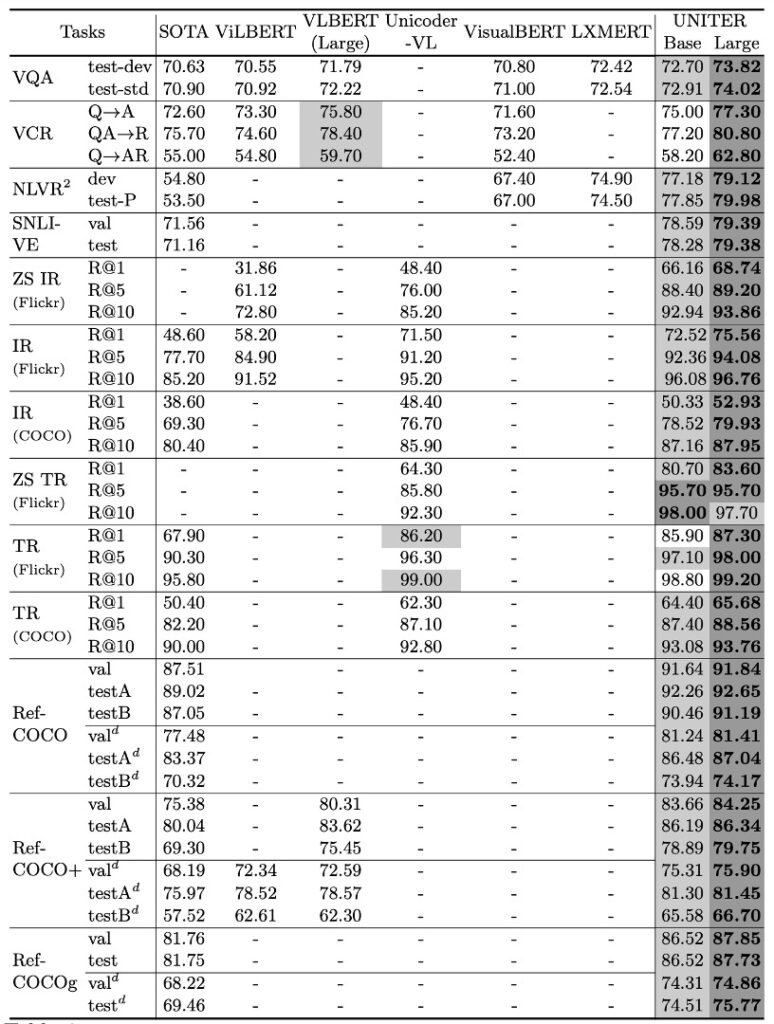
The authors conducted extensive tests on various downstream tasks to evaluate the performance of the UNITER model, revealing several key findings:
-
Overall Performance
The UNITER model achieved outstanding results across all downstream tasks, with the UNITER-large model reaching state-of-the-art levels in all benchmarks. The model's performance even surpassed current best techniques in some tasks.
-
Comparison with Task-Specific Models
Compared to some task-specific models like MCAN, MaxEnt, and B2T2, the UNITER-based model performed exceptionally well in most tasks. For example, in the VCR task, the UNITER model outperformed the current best technique by about 2.8%.
-
Comparison with Other Pre-Training Models
Compared to other multimodal pre-training models like ViLBERT and LXMERT, UNITER outperformed in most tasks. Specifically, it excelled in VQA, outperforming all other models pre-trained on image-text pairs, with an improvement of over 1.5%.
-
Single-Stream vs. Dual-Stream Models
While previous research like ViLBERT and LXMERT observed that dual-stream models outperformed single-stream models, the authors found that the single-stream UNITER model could also achieve state-of-the-art levels under pre-training settings and with fewer parameters.
-
Two-Stage Pre-Training Method
For tasks like VCR, the authors proposed a two-stage pre-training method, first pre-training on standard datasets, then pre-training on the downstream VCR dataset. This strategy proved effective for new downstream tasks.
-
Adaptability to NLVR2
For special tasks like NLVR2, the authors tried different settings to ensure the model's adaptability. They found that bidirectional attention mechanisms could complement inter-image interactions, leading to better performance.
These results further emphasized the powerful capabilities of the UNITER model in multimodal tasks. By combining state-of-the-art pre-training strategies, it successfully achieved excellent performance across various downstream tasks, demonstrating its leading position in the field of vision and language integration.
What Did the Model Learn?
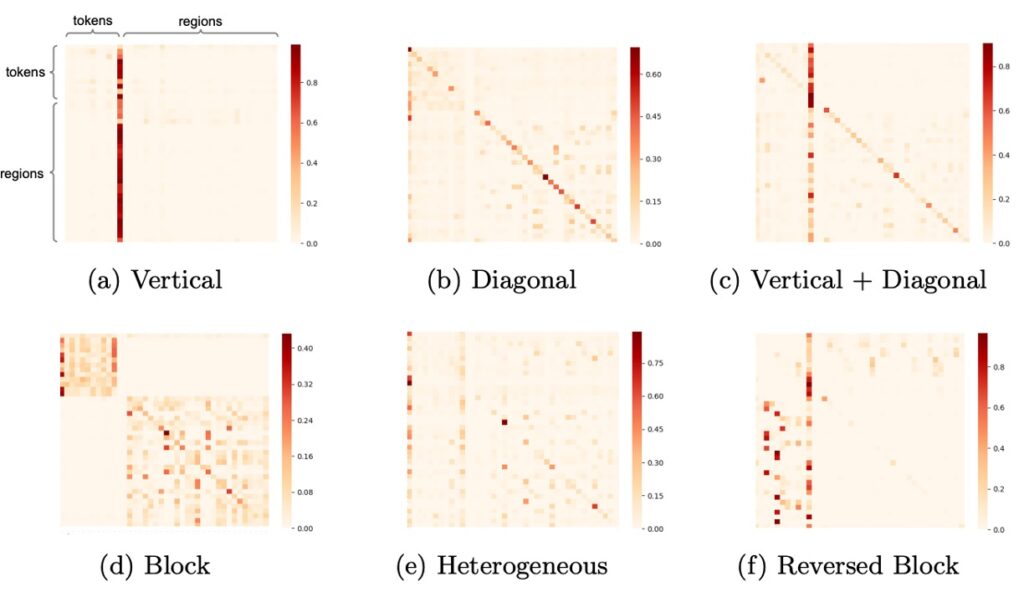
In the UNITER model, the authors conducted an in-depth analysis of the model's learning behavior through attention visualization.
This visualization revealed how the model understands and connects information from different modalities. Here are the main findings:
-
Vertical Pattern
This pattern occurs when the model mainly focuses on specific tokens such as [CLS] or [SEP]. It indicates that the model is searching for overall context or summary information at those positions. Frequent appearance of this pattern might suggest that the model is overly reliant on these special tokens, possibly due to over-parameterization or insufficient training data.
-
Diagonal Pattern
This pattern appears when the model's attention is concentrated on tokens or regions and their immediate surroundings. It indicates that the model is parsing local information within the current context, which is a normal expected pattern.
-
Vertical + Diagonal Pattern
This is a fusion of the first two patterns, indicating that the model is interpreting both overall information and local context simultaneously.
-
Block Pattern
In this pattern, the model's attention is mainly concentrated within its modality, such as text or visual, rather than cross-modality. This might indicate that the model is conducting certain modality-specific reasoning at that moment.
-
Heterogeneous Pattern
This pattern shows a diverse distribution of the model's attention, indicating that the model is understanding information from different perspectives based on the current input.
-
Reversed Block Pattern
In this pattern, the model's attention is cross-modal, discerning the relationship between text and images. The existence of this pattern indicates that the model is closely integrating visual and linguistic information.
Conclusion
Looking back at this paper, we can see that a few years ago, researchers continued to show deep interest in the exploration of vision and language fusion. In this study, UNITER was proposed as a large-scale pre-training model designed to establish a powerful and universal image-text representation. Through a series of ablation studies, the researchers clearly evaluated the four proposed pre-training tasks.
By training on both in-domain and out-of-domain datasets, UNITER demonstrated relatively outstanding performance at the time, especially in multiple vision and language tasks. The insights provided by this research also pointed out several directions worth exploring, especially in the interaction between images and sentences and more efficient pre-training strategies.
This paper provides us with an opportunity to review and reflect, helping us better understand the historical progress and development of the field of vision and language integration.