[24.10] FM-CLIP

Guidance from Language
FM-CLIP: Flexible Modal CLIP for Face Anti-Spoofing
In the field of Face Anti-Spoofing (FAS), the term "multimodal" typically refers to different sensors such as RGB, depth, and infrared.
However, in recent years, another kind of "modality" has become popular: natural language.
Problem Definition
The original battlefield of Face Anti-Spoofing (FAS) is the image itself.
Researchers designed convolutional networks to extract features like texture, depth, and reflectance to distinguish between genuine and fake faces.
However, as attack methods evolve—such as high-resolution printing, replay attacks, and 3D masks—the defense relying on a single modality has gradually fractured.
To cope with this escalation, the FAS community introduced multimodal fusion. RGB captures color, IR senses heat, Depth measures structure; by interleaving signals from different sensors, they attempt to piece together a more realistic picture.
Yet this approach has its cracks.
Multimodal fusion depends on having all modalities available during both training and testing. Once any sensor data is missing, the system’s recognition ability collapses like a breached dam, becoming almost completely ineffective. Hardware costs for deployment and variable scene conditions make "modality consistency" a luxury.
The concept of Flexible Modal emerged in response.
Its goal is to design a model that learns multimodal features during training but does not rely on the presence of all modalities during testing. However, past research on Flexible Modal still focused on traditional modalities such as spectral, thermal, or geometric signals.
The rise of natural language offers another possibility.
Language does not directly capture the world's light and shape; instead, it describes, interprets, and aligns experiences.
It provides an alignment mechanism beyond the sensor level, enabling heterogeneous observations to find commonality at the semantic level.
Perhaps, through natural language as a bridge, we can reconstruct the cognition of authenticity within the gaps of these fragmented modalities.
Solution
This paper uses CLIP as its foundational architecture. If you are not familiar with CLIP, you can refer to our previous paper.
Model Architecture
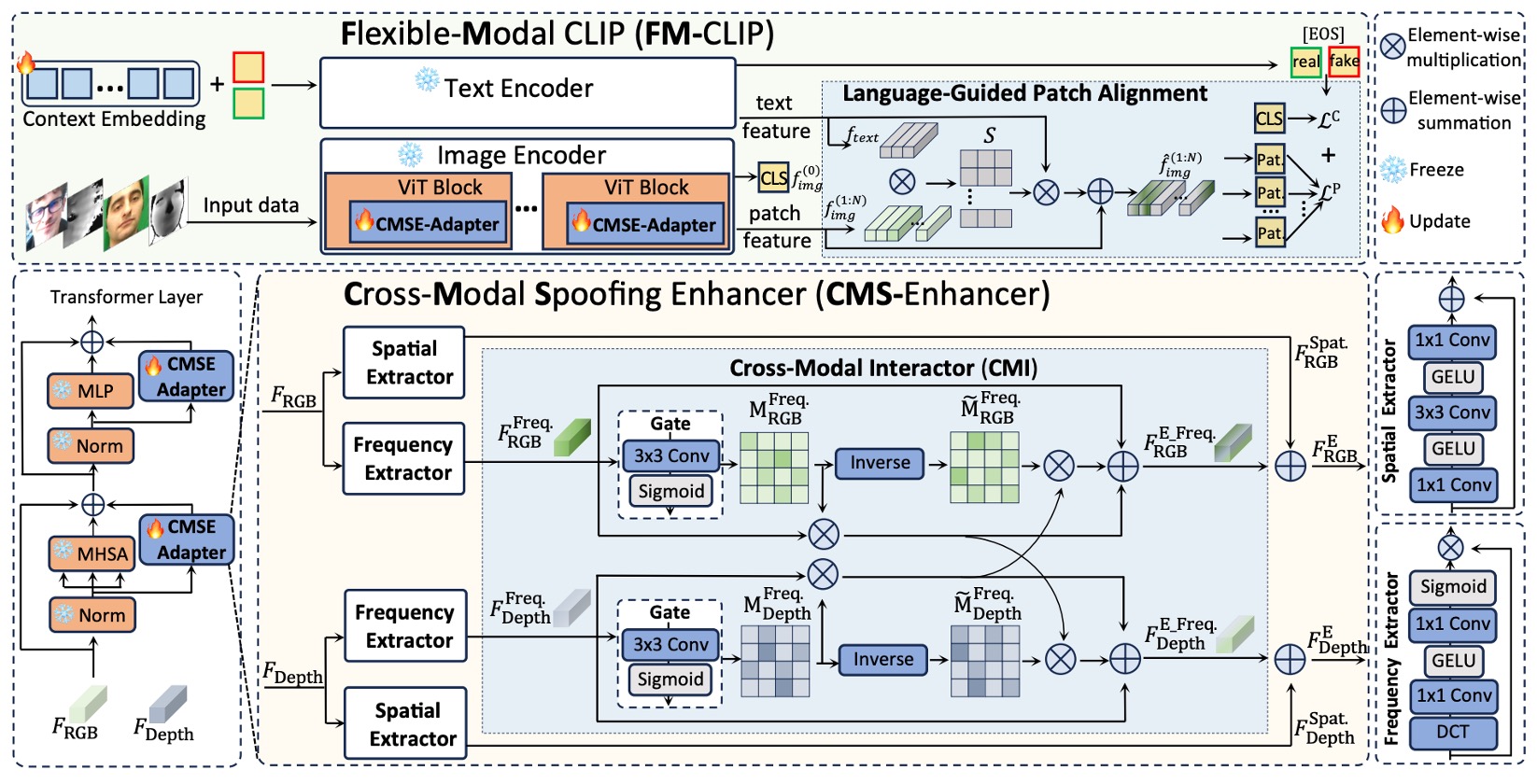
The authors propose FM-CLIP, a multimodal alignment model based on CLIP, specifically designed for Face Anti-Spoofing (FAS).
The entire architecture is built upon a frozen CLIP model.
As shown in the figure above, FM-CLIP can be divided into two main branches:
- Visual Branch: Takes sensor data such as RGB and Depth, processed by a ViT image encoder.
- Language Branch: Uses prompt learning to generate text vectors as auxiliary signals to guide the alignment of visual features.
Next, we examine each component in the order of signal flow.
CMS-Enhancer
The original ViT is purely self-attention based and lacks sensitivity to local structures and frequency signals.
To compensate for this, the authors insert a cross-modal spoofing enhancement module at each ViT stage:
- Cross-Modal Spoofing Enhancer (CMS-Enhancer)
The input features are decomposed into two parallel streams:
- Spatial Features: Fine-grained texture extraction by the Spatial Extractor (SE).
- Frequency Features: The Frequency Extractor (FE) maps images to the frequency domain to extract high-level structural differences.
The Spatial Extractor (SE) operates as:
This is a simple convolutional structure with GELU activation to obtain local image features.
A residual connection is added:
The Frequency Extractor (FE) is defined as:
After transforming the image into a spectral map, convolution and GELU are applied. Although the operation is similar, the target is now the spectral domain, extracting distinctly different features.
Finally, the output is element-wise multiplied with the original input to strengthen or weaken certain frequencies:
Cross-Modal Interactor
Different modalities may vary greatly in spatial features, but in frequency space they can be mapped onto a shared intermediate plane. To facilitate this frequency-domain interaction, the authors design the Cross-Modal Interactor (CMI) module:
- Compute a gate map for each modality indicating regions of high and low information density.
- Use the gate maps to supplement useful information from the other modality, repairing weak regions.
Gate maps are computed as:
Since the output passes through a sigmoid function, values range between 0 and 1, representing retention or suppression of image regions deemed unnecessary by the model.
The interaction and supplementation process is:
This means that, for example, for RGB features, regions not retained by the model are supplemented with corresponding information from the Depth features, encouraging cross-modality inspection.
Finally, the original features, enhanced features, and supplemented features are fused:
These are then combined with the corresponding spatial features to form enhanced representations.
In this way, the visual branch within each ViT block learns not only its own modality details but also receives frequency supplementation from other modalities.
Language-Guided Patch Alignment
After processing visual signals, the authors introduce the natural language modality to further guide each patch to focus on spoofing cues.
In the text branch, Prompt Learning is used to initialize a set of learnable context vectors , combined with class labels , forming the prompt:
This technique is not novel per se; it has become a common and effective method to leverage large model capabilities. Its downside is that learned tokens are often hard to interpret.
After passing through the text encoder , text features are obtained.
From the visual branch, we have the CLS token and Patch tokens .
The authors adopt dual alignment:
- CLS Token Alignment: Compute similarity between CLS and EOS (real/fake) vectors for global classification.
- Patch Token Alignment (LGPA): Calculate similarity matrix between each Patch token and text features:
Then perform weighted fusion:
Thus, each patch can refocus on local clues potentially indicating spoofing, guided by language.
Loss Function Design
To supervise both global and local alignment, the authors introduce two loss terms:
-
CLS Loss (Global Alignment):
-
Patch Loss (Local Alignment):
The total loss is:
This design maintains tension between global recognition and local detail, capturing both high-level semantics and subtle flaws.
Discussion
The authors evaluated their method on three commonly used multimodal FAS datasets:
- CASIA-SURF (SURF): A tri-modal dataset focusing on unknown attack types.
- CASIA-SURF CeFA (CeFA): Contains variations in race and modality, using Protocols 1, 2, and 4.
- WMCA: A highly realistic multi-attack scenario dataset, covering both “seen” and “unseen” evaluation settings.
Experiments were conducted under two testing settings:
- Fixed Modal: Training and testing modalities are consistent.
- Flexible Modal: Only a single modality is provided during testing.
Evaluation metrics include APCER, BPCER, and ACER.
Fixed Modal Results
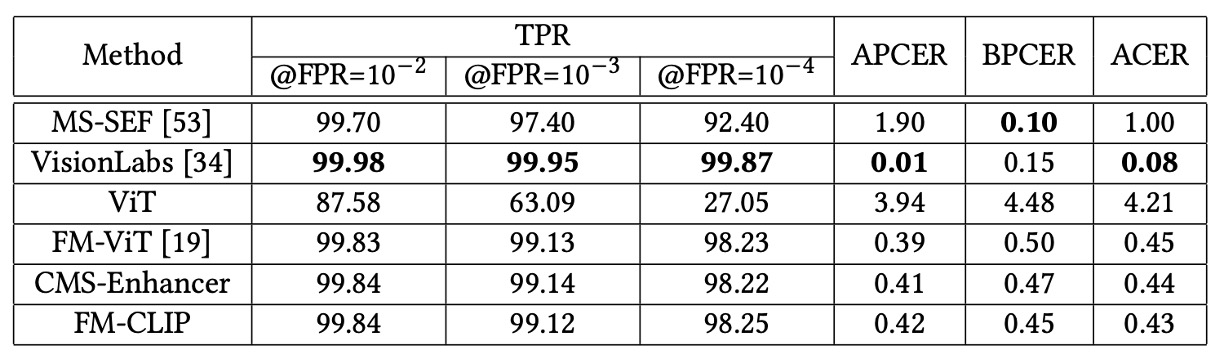
Under the fixed modal setting, FM-CLIP demonstrates a stable improvement trend.
- SURF dataset: After introducing CMS-Enhancer, ACER dropped from 0.45 to 0.44; with LGPA integration, it further decreased to 0.43.
- WMCA dataset (unseen protocol): CMS-Enhancer reduced ACER from 2.49% to 2.36%; with LGPA, FM-CLIP finally reached 2.29%.
- CeFA dataset: FM-CLIP slightly lowered APCER, BPCER, and ACER across three protocols, showing robust cross-domain generalization.
Since FM-CLIP has fewer trainable parameters than FM-ViT, its absolute performance under WMCA “seen” scenario is slightly lower than FM-ViT, an expected trade-off.
Flexible Modal Results
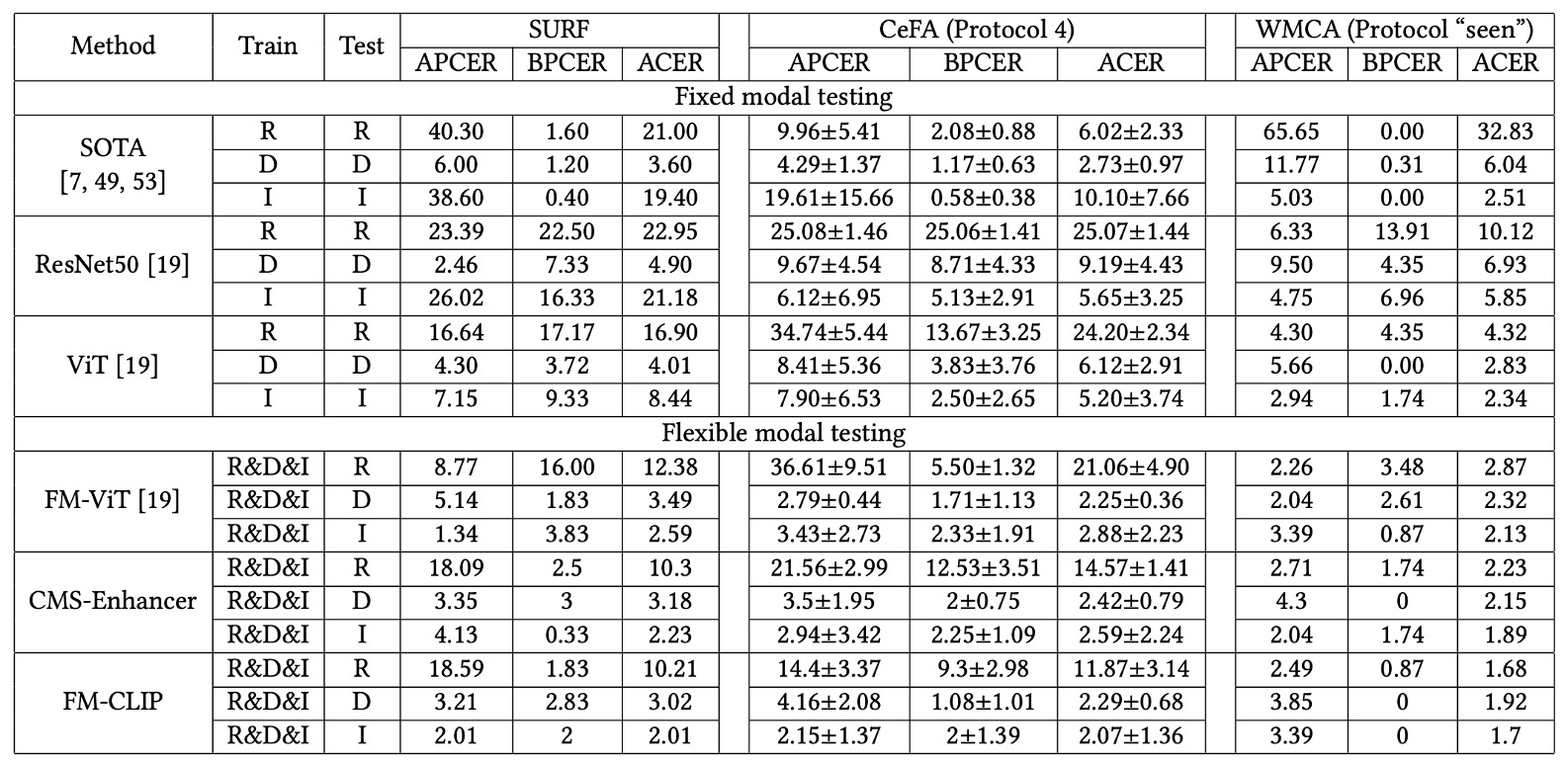
In the more challenging flexible modal tests, FM-CLIP exhibits clear advantages.
- SURF dataset: Across RGB, Depth, and IR single modalities, FM-CLIP consistently outperformed FM-ViT, achieving up to a 2.17% reduction in ACER.
- CeFA Protocol 4: Especially in the IR modality, FM-CLIP reduced ACER by 8.1 compared to FM-ViT, showing particular effectiveness for difficult infrared data.
- WMCA (seen protocol): FM-CLIP showed additional gains across all modalities (RGB, Depth, IR), maintaining stable low error rates.
Core Components Analysis
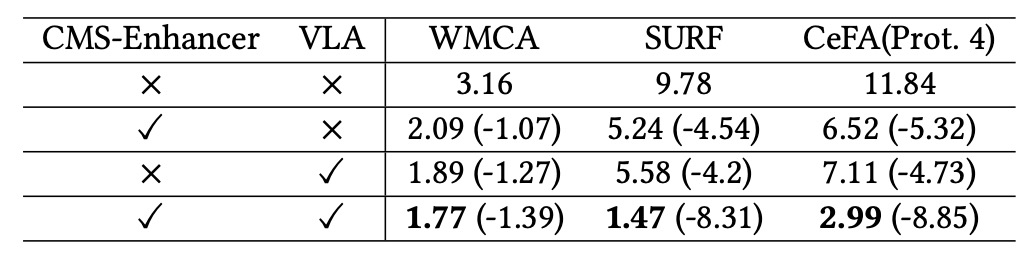
Ablation studies on FM-CLIP’s two main modules—CMS-Enhancer and VLA (Vision-Language Alignment)—were conducted on WMCA (seen), SURF, and CeFA (Protocol 4) datasets under the flexible modal setting.
Results show:
- Introducing CMS-Enhancer alone lowered ACER by over 4%, effectively stabilizing visual features.
- Introducing VLA alone similarly reduced ACER by about 4%, demonstrating the role of language guidance in local feature alignment.
- Combining both modules (FM-CLIP) resulted in ACER reductions of 8% to 9% across datasets, indicating their complementary nature.
Conclusion
Introducing Vision-Language Models (VLMs) into the FAS domain has become a popular trend in recent years.
Given the heterogeneity of data sources and diversity of attack types, relying solely on single sensors or handcrafted features is increasingly inadequate for maintaining stable recognition systems. Natural language, as a high-level alignment mechanism, offers potential links across sensors and attack modes, making it a promising direction many researchers are exploring.
From this study, two key directions emerge:
- When physical-layer observations inevitably fragment, semantic-level alignment and repair will become a crucial pillar of recognition systems.
- Pure language guidance alone is insufficient to fully replace sensor-level information enhancement; frequency domain, local structures, and semantic relations still need to be tightly integrated.
FM-CLIP demonstrates the feasibility of cross-modal alignment with a lightweight design, leaving room for further exploration in deeper structural modeling and active perceptual repair.