[20.03] CeFA

Discrimination in Models
CASIA-SURF CeFA: A Benchmark for Multi-modal Cross-ethnicity Face Anti-spoofing
The CASIA-SURF in the paper title refers to a face anti-spoofing dataset created by the Chinese Academy of Sciences, Institute of Automation (CASIA), called:
CASIA-SURF: A Large-Scale Multi-Modal Benchmark for Face Anti-Spoofing
This dataset was released in 2019 and became one of the key datasets created for multi-modal face anti-spoofing at the time.
This paper presents an extended version of the dataset aimed at addressing ethnic bias, named CASIA-SURF CeFA.
Defining the Problem
In the field of Face Anti-Spoofing (FAS), everyone is striving for models that are "more accurate, faster, and more generalized."
However, there's an old issue that everyone tends to avoid discussing: Ethnic Bias.
So, has everyone forgotten about this? Or are they just too afraid to address it?
If you have worked on facial recognition, you are definitely familiar with this issue.
Currently, most of the faces in large public facial recognition datasets predominantly belong to "Caucasians," which results in poorer recognition performance for other ethnic groups, and in severe cases, can even lead to erroneous system responses.
As a result, anyone who wants to tackle this problem must collect a dataset for their "target group" to ensure the model learns stable and accurate features.
This issue is also present in FAS.
The authors found that current state-of-the-art (SOTA) models exhibit a significant performance drop when applied across ethnic groups. According to their experiments:
The same FAS model has an ACER at least 8% higher for Central Asian groups compared to East Asian groups.
Just imagine, if the model you deploy starts spitting out: Fake! Fake! Fake! whenever it encounters a specific ethnic group, wouldn't the customer immediately toss both the system and you, the deployment engineer, into the river?
Solving the Problem
The main focus of this paper is on the content and design of the dataset, with only a brief mention of the model architecture.
CeFA Dataset
The CeFA dataset is compared with other datasets in the table below:
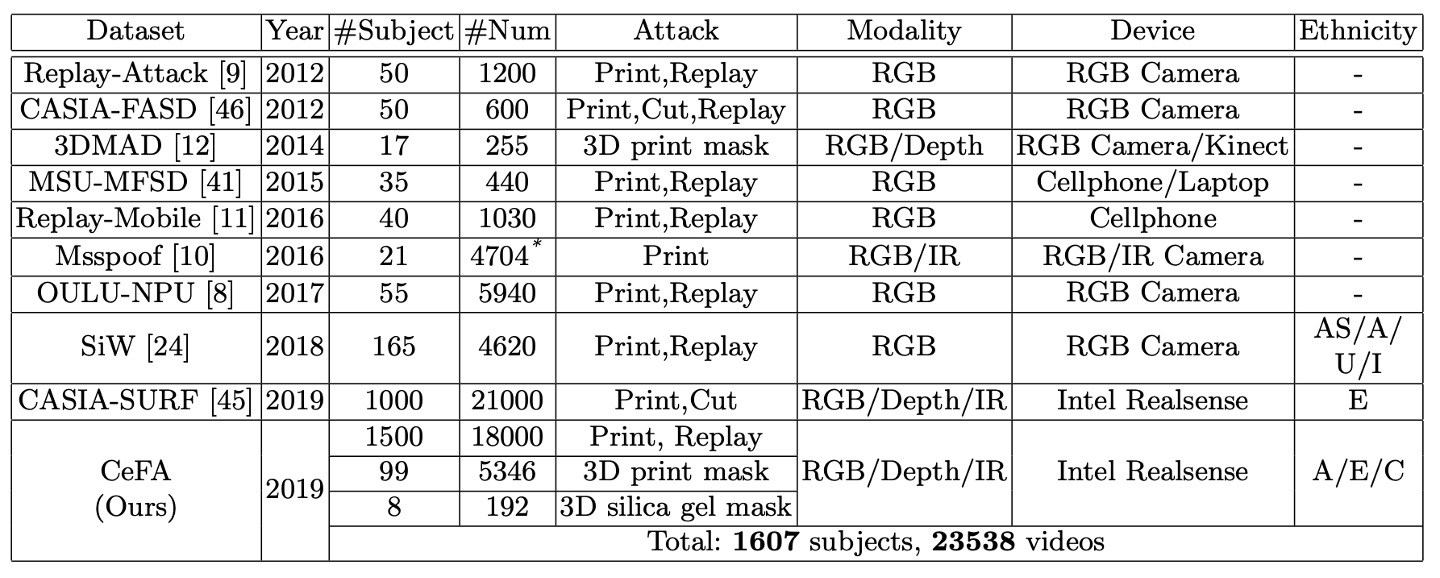
CeFA uses the Intel RealSense camera to capture three-modal video data, including RGB (color), Depth (depth), and IR (infrared). The resolution of each video is 1280 × 720, with a frame rate of 30 fps.
During the recording, participants were asked to naturally rotate their heads, with a maximum deviation angle of about 30 degrees, simulating natural facial dynamics in real-world scenarios.
The preprocessing steps for the data are as follows:
-
Face detection uses the 3DFFA model (replacing PRNet).
-
The aligned facial regions are extracted and the corresponding three-modal samples are retained.
-
Multimodal facial samples are shown in the image below:

The CeFA dataset consists of two subsets: the 2D Attack Subset and the 3D Attack Subset, covering three ethnic groups (African, East Asian, and Central Asian) and designed with various attack types and lighting conditions.
-
2D Attack Subset (Print & Replay)
- Number of participants in each group:
- 500 participants per group, for a total of 1500 participants
- Samples per participant:
- 1 real sample
- 2 print attack samples (one indoors, one outdoors)
- 1 video replay attack sample
- Modal data:
- RGB, Depth, and IR modalities are captured synchronously for each sample
- Total number of samples:
- 1500 participants × 4 video clips = 6000 clips × 3 modalities = 18,000 video clips
The paper also provides demographic statistics on age and gender for participants in the 2D subset, which will be helpful for future fairness analysis.
- Number of participants in each group:
-
3D Attack Subset (3D Masks and Silicone Masks)
This subset simulates more realistic advanced attack scenarios, including two types of attacks:
-
3D Printed Mask Attacks
- Number of participants: 99 people
- Samples per participant:
- 3 types of attack styles:
- Plain mask
- Wig + glasses
- Wig without glasses
- 6 lighting conditions:
- Outdoor sunlight, outdoor shade
- Indoor side light, front light, back light, regular light
- A total of 18 video clips × 3 modalities
- 3 types of attack styles:
-
Total number of samples: 99 × 18 × 3 = 5346 video clips
-
Silicone Mask Attacks
- Number of participants: 8 people
- Samples per participant:
- 2 types of attack styles:
- Wig + glasses
- Wig without glasses
- 4 lighting conditions:
- Indoor side light, front light, back light, regular light
- A total of 8 video clips × 3 modalities
- 2 types of attack styles:
-
Total number of samples: 8 × 8 × 3 = 196 video clips
Although the 3D subset is relatively small in quantity, its attack styles are realistic, and the variable factors are complex, making it an important test set to evaluate the model's generalization capability.
-
Evaluation Protocols
The detailed concepts of these four protocols have been introduced in previous papers, so we will briefly go over them here.
In order to systematically evaluate the generalization ability of models in different scenarios, the CeFA dataset designs four evaluation protocols, covering challenges such as cross-ethnicity, cross-attack types, cross-modality, and their combinations.
The table below shows the specific configurations for each protocol:
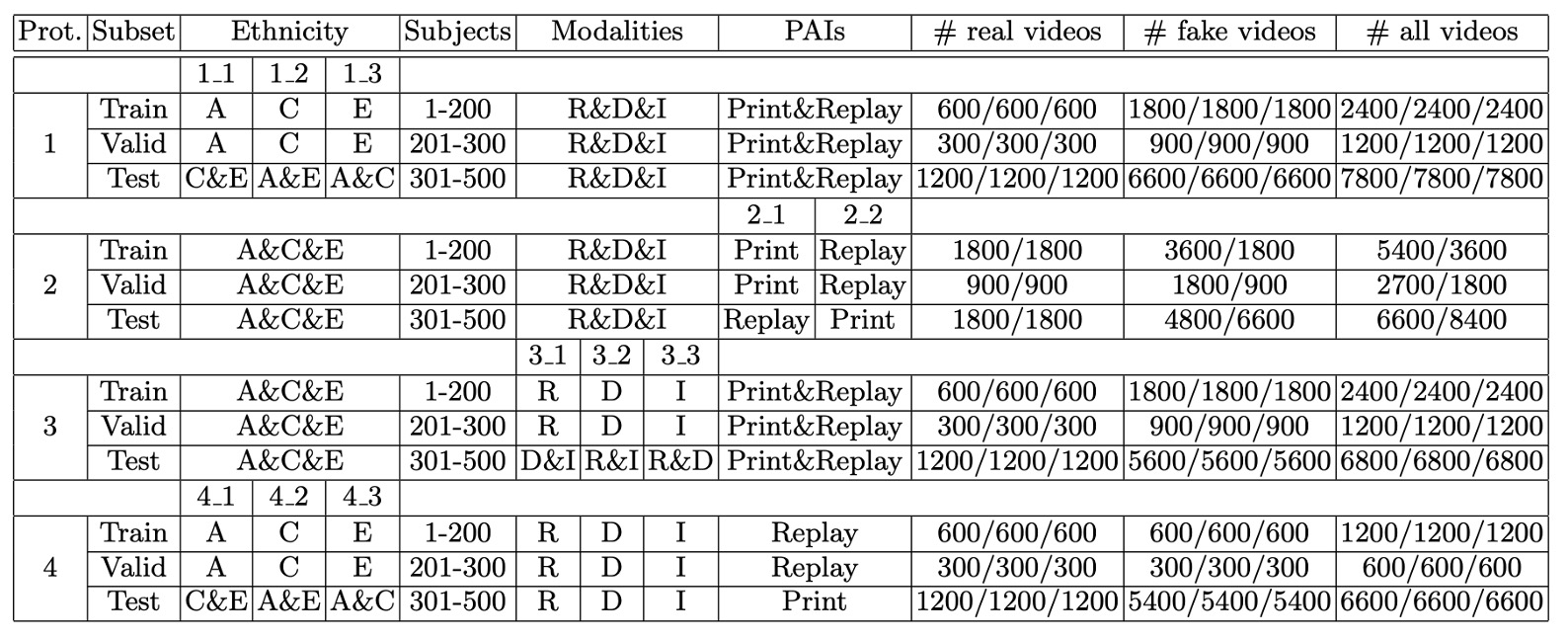
-
Protocol 1: Cross-ethnicity
This protocol addresses the common issue in existing PAD datasets, which lack ethnicity annotations and cross-group testing setups. It is designed to evaluate the model’s generalization ability when faced with previously unseen ethnic groups.
The approach involves selecting one ethnic group for training and validation, and using the remaining two groups' data as the test set. This results in three different experimental configurations.
This setup simulates a real-world scenario where a model is developed for a specific ethnic group and then deployed in environments with other ethnic groups.
-
Protocol 2: Cross-PAI
This protocol tackles the diversity and unpredictability of presentation attack instruments (PAI) in attack forms, evaluating the model’s robustness when faced with unknown attack styles.
During the training and validation stages, only certain attack types are used, while the test stage employs previously unseen attack methods to observe whether the model can identify different types of spoofing behavior.
-
Protocol 3: Cross-modality
This protocol is designed to explore the model's generalization ability across different modalities. During the training stage, only one modality (RGB, Depth, or IR) is used, while the test stage evaluates the remaining two modalities.
This setup is designed to test the model’s performance when sensor equipment is limited, or modality information is incomplete, simulating real-world scenarios where cross-modal feature alignment is lacking.
-
Protocol 4: Cross-ethnicity & Cross-PAI
This is the most challenging protocol, combining the conditions of Protocol 1 and Protocol 2. The test set includes both unknown ethnic groups and unknown attack types.
This setup simulates the most difficult deployment scenarios, where a model is faced with both previously unseen ethnic group appearances and attack methods. This protocol effectively reveals the model’s real generalization ability and sensitivity to bias.
Model Architecture
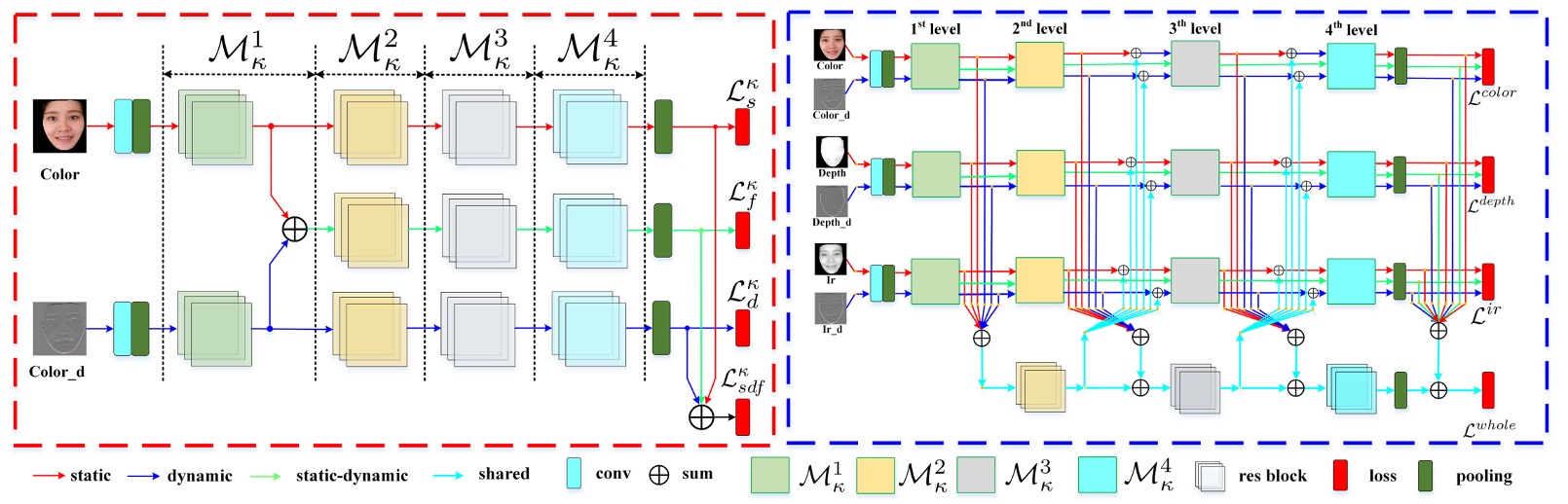
For the CeFA dataset, the model proposed in this paper consists of two major modules:
- SD-Net: A single-modality static-dynamic feature extraction network that focuses on capturing spatial and temporal information within a single modality.
- PSMM-Net: A partially shared multimodal network designed for feature fusion and interactive learning across different modalities.
SD-Net
SD-Net processes single-modality inputs (RGB, Depth, or IR), and its core design aims to simultaneously capture both static image and dynamic sequence information. The overall architecture consists of three feature branches:
- Static Branch (red arrow): Handles single static images to extract spatial features.
- Dynamic Branch (blue arrow): Summarizes K-frame sequences using Rank Pooling, converting them into a dynamic feature map.
- Static-Dynamic Branch (green arrow): Fuses the above two features, enhancing the interaction between spatial and temporal information.
Each branch uses a ResNet-18 backbone, consisting of five residual modules and a global average pooling (GAP) layer. The input to the Static-Dynamic branch is the sum of the outputs from the res1 layer of both the Static and Dynamic branches.
Each module is denoted as , where:
- : Modality type;
- : Feature layer levels.
Each branch produces an independent feature vector at each layer, denoted as:
- (Static)
- (Dynamic)
- (Fusion)
To ensure that the three branches can learn complementary information, the authors designed independent loss functions for each branch (using BCE) and also introduced a loss for the combined features:
PSMM-Net
Next, let's look at the PSMM-Net portion.
The goal of PSMM-Net is to capture common semantics and complementary information across modalities. It consists of two parts:
- Modality-specific Networks: Three SD-Nets, each corresponding to RGB, Depth, and IR modalities, independently extracting static and dynamic features.
- Shared Branch: Based on a ResNet-18 architecture (removing the conv and res1 layers), used to model shared semantics across modalities.
To achieve effective modality interaction, PSMM-Net employs a bidirectional fusion strategy:
-
Forward Feeding (to shared branch)
The static and dynamic features of all three modalities are summed at each layer and fed into the shared branch:
Where is the output of the shared branch at layer (, starting from zero).
-
Backward Feeding (from shared branch back)
The is fed back into each modality’s SD-Net and summed with the original features to correct the output features:
This step only affects the static and dynamic branches, preventing the fusion branch from being interfered with by semantic differences between modalities.
The overall architecture clearly decouples static and dynamic features through SD-Net and then enhances the model’s generalization ability across different ethnicities and attack types using the bidirectional modality interaction design in PSMM-Net.
The final loss function is:
Where is the total loss after summing the features from all modalities and the shared branch.
Discussion
Model Bias Analysis Under Ethnic Diversity

The authors conduct a performance bias analysis on three different ethnic groups (East Asian, Central Asian, African) in the CeFA dataset, observing the performance differences of current mainstream models when facing ethnic variations.
The experiment uses two state-of-the-art (SOTA) models trained on two public datasets, representing multimodal and single-modality anti-spoofing methods:
- MS-SEF: A multimodal method trained on CASIA-SURF (mainly East Asian samples)
- FAS-BAS: A single-modality RGB method trained on OULU-NPU (also primarily East Asian)
After training, both models are tested on the three ethnic groups in the CeFA dataset, using ACER as the primary evaluation metric.
The results show that Central Asian recognition performance is the worst, with both models significantly dropping performance on this ethnic group, with an increase in ACER of about 7–10%. East Asian recognition performance is the best, likely because the training datasets (CASIA-SURF, OULU-NPU) mainly consist of East Asian faces, causing the model to exhibit clear ethnic bias.
This experiment highlights the limitations of training on single-ethnicity datasets for model generalization. When faced with unseen ethnic group features, the recognition performance significantly drops. The results also validate the necessity of the cross-ethnicity protocol (Protocol 1) in CeFA, which helps to push forward facial anti-spoofing research with better fairness and generalization capabilities.
Baseline Model Evaluation Results
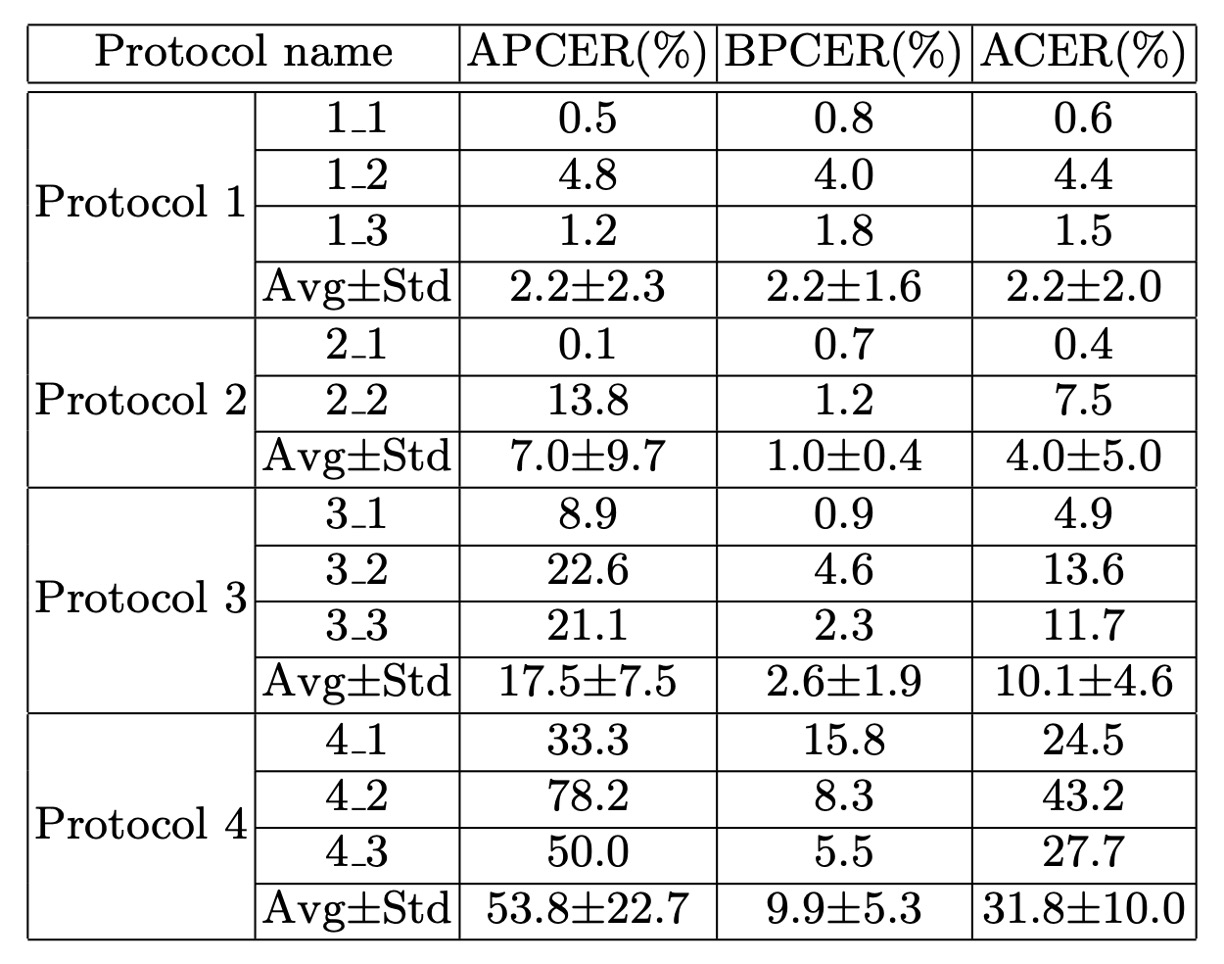
The authors conduct comprehensive experiments on the SD-Net and PSMM-Net models under the four evaluation protocols designed in CeFA:
-
Protocol 1: Cross-ethnicity
- Sub-protocols 1-1, 1-2, and 1-3 have ACER values of 0.6%, 4.4%, 1.5%, respectively.
- The performance differences between ethnic groups confirm the existence of ethnic bias. These results support the design motivation for cross-ethnicity evaluation protocols and demonstrate the importance of incorporating ethnic diversity during training.
-
Protocol 2: Cross-PAI (Generalization Across Different Attack Tools)
-
Sub-protocol 2-1 (trained on print, tested on video-replay + 3D) has an ACER of 0.4%.
-
Sub-protocol 2-2 (trained on video-replay, tested on print + 3D) has an ACER of 7.5%.
-
The results show that the physical property differences of attack tools (e.g., screen display vs print materials) lead to significant performance gaps, indicating that current PAD models are highly sensitive to attack styles.
-
-
Protocol 3: Cross-modality (Generalization Across Modalities)
-
The best result is from sub-protocol 3-1, with an ACER of 4.9%.
-
The model demonstrates a certain level of modality transfer capability, but performance is still limited by the semantic alignment between the training and testing modalities. This protocol highlights the importance of multimodal data and validates the benefits of the PSMM-Net fusion strategy.
-
-
Protocol 4: Cross-ethnicity & Cross-PAI (Dual Generalization Test)
- Sub-protocols 4-1, 4-2, and 4-3 have ACER values of 24.5%, 43.2%, 27.7%, respectively.
- This is the most difficult scenario, as it involves dealing with both unknown ethnic groups and unknown attack types. The overall performance significantly drops, highlighting the multiple generalization challenges faced during real-world deployment and also validating the value and difficulty of the CeFA design.
Conclusion
This paper presents the largest multimodal facial attack detection dataset at the time, covering RGB, Depth, and IR modalities, and for the first time, introduces ethnic group labels, explicitly incorporating "cross-ethnicity generalization" into the discussion core.
In terms of model design, the PSMM-Net "partial sharing + bidirectional fusion" strategy, combined with the SD-Net static-dynamic feature decoupling, was one of the more systematic attempts in multimodal learning at the time. Although later architectures have emerged with more streamlined or enhanced cross-modality alignment, the design philosophy of PSMM-Net still leaves its mark in many variant architectures.
Looking back, the key contribution of CeFA is clearly defining the research challenges of "cross-modality, cross-ethnicity, and cross-attack types," providing a reasonable starting point. For us today, this is not just a dataset but a continuously extending problem space.