[18.05] InstDisc

More is better
Unsupervised Feature Learning via Non-Parametric Instance Discrimination
Seizing a break in development, I quickly dive into some papers related to contrastive learning.
Although I’ve already listened to the master class before, reading through it myself feels more solid.
Here’s a recommended master class on contrastive learning: Contrastive Learning Paper Overview [Paper Reading]
The duration is about 90 minutes, covering the basic concepts of contrastive learning, its development history, detailed readings of related papers, and analyses. After watching, you'll have improved for the next 10 years. (?)
Before the concept of contrastive learning became popular, metric learning had already been widely used in the industry. The most well-known application is face recognition, with no exceptions.
The core of metric learning lies in learning feature representations , which establish a measure between samples and :
Once the model is trained, it can only make inferences based on the features it has learned, without the use of a linear classifier.
For classic papers on metric learning, refer to:
During the research process, it was found that normalization—projecting feature vectors uniformly onto a hypersphere—is a key step that can improve model performance.
Defining the Problem
However, what metric learning discusses is "class-level" learning, meaning we must know which class each image belongs to in order to perform metric learning.
Metric learning is inherently supervised learning, but in real-world applications, we typically only have large amounts of "unlabeled" data, making it difficult to apply metric learning in such scenarios.
Thus, researchers have come up with various solutions:
Generative Models
The concept of generative models is also quite appealing. By building an encoder and decoder, it transforms an image into a hidden feature representation and then reconstructs the image from that representation. Common models include Autoencoders, GANs, VAEs, etc.
The advantage is that no labels are required; as long as images are available, training can begin. However, the downside is the high computational cost. As the resolution of the reconstructed image increases, the computational load grows exponentially.
Moreover, generative models rely on the distribution of data, making them less generalizable, and in some cases, they may even experience model collapse.
Self-Supervised Structural Learning
Self-supervised learning leverages the internal structure of the data to create a prediction task and then trains the model.
Let’s look at some interesting examples:
-
Context Prediction
-
Color Restoration of Grayscale Images
-
Jigsaw Puzzle Solving Task
-
Filling In Missing Parts of an Image
-
Counting Objects



After seeing so many proxy tasks, they all seem reasonable, but we cannot explain why these tasks help semantic recognition, nor can we determine the best self-supervised task.
Since there’s no consensus, let’s create one. Inspired by metric learning, the authors propose a novel feature learning training method, aiming to work without artificial labels.
Solving the Problem
To obtain a "good" feature representation, the authors adopt an "instance-level discrimination" strategy: treating each image as an independent "class" and training a classifier to determine whether each image belongs to its own "class."
Let’s take a look at the model architecture.
Model Architecture
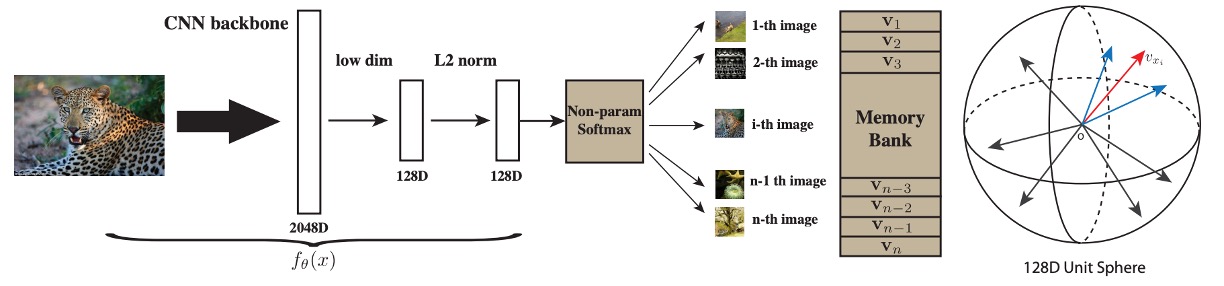
As shown in the diagram above, on the left is a deep convolutional neural network labeled "Backbone CNN." Its function is to transform the input image (e.g., a 224224 image) into higher-level semantic features. For common CNN networks, this might involve several layers of convolution, batch normalization, pooling, and other operations. The final layer typically outputs a high-dimensional vector, which serves as the "visual feature representation."
The high-level features output from the Backbone CNN are usually still of large dimensionality (e.g., 2048 dimensions). To run efficiently with large datasets, more compressed and abstract feature descriptions are needed, so the authors add a "Projection Head" to project the CNN output vector into a 128-dimensional vector space.
After projection, the 128-dimensional vector is then subjected to L2 Normalization (), which means each sample is constrained to unit length. This is especially useful when computing similarity because, at this point, the dot product represents the cosine of the angle between the two vectors on the hypersphere, with values ranging from . This makes the calculation more intuitive and stable.
The Problem with Traditional Classifiers
In traditional Softmax classification models, each class corresponds to a weight vector . Suppose we have images (equivalent to "classes"), with corresponding weight vectors . For a given image , the feature vector produced by the neural network is . The conditional probability of the image being classified as the -th image (i.e., the -th "class") can be written as:
In this equation, is used to measure the alignment between the feature and class ; the denominator is the sum of the exponentiated values of all class comparisons (from 1 to ), ensuring that the total probability across all classes sums to 1.
In typical classification problems, the number of classes is fixed and not too large, so this parameterized Softmax is commonly used. However, here, since "each image" is treated as a new class, the number of classes can be enormous (tens of thousands, millions, or more). As a result, each class requires an independent weight vector , which not only requires significant storage space but also results in high computational costs.
Simply put, it becomes too computationally expensive.
Non-Parametric Classifier
To address the above problem, the authors propose a "non-parametric" approach:
- Replace the formula's with the feature vector stored in a memory bank.
In other words, the "class weight" for the -th image is no longer an independent , but instead, it directly uses the feature vector of the -th image itself. Additionally, the authors enforce normalization of these feature vectors to unit vectors (i.e., length 1) for ease of similarity calculation.
Thus, the Softmax formula can be rewritten as:
Here, is the "temperature parameter," which can adjust the "sharpness" of the Softmax distribution; is the feature vector of the current image produced by forward propagation; is the feature vector of the -th image stored in the "memory bank" (also a unit vector), and is the dot product of the two unit vectors, ranging from -1 to 1, which represents their similarity.
Originally, is a learnable parameter, serving as the "anchor" for each class. The greater the inner product between the feature and the anchor, the higher the classification probability, making the model more likely to classify the input feature as that class.
Here, the authors forgo the and instead directly use the "feature " of the data itself as the comparison object. This eliminates the need to learn a separate for each possible image class, helping to reduce computational costs.
This leads to the next question: Since the classification anchors are not fixed but rather drift around as training progresses, how can the model ensure their stability?
We will discuss this shortly; let’s first continue with the rest of the architecture.
Memory Bank
The training objective for the non-parametric softmax is similar to that of typical classification problems: to maximize the probability of each training image being "correctly identified as itself," or equivalently, to minimize the negative log-likelihood over the entire training set:
Here, is denoted as . When computing , theoretically, the features of all images are needed. However, if every backpropagation requires passing all images through the neural network, the computational cost would be very high.
Thus, in practice, the authors maintain a "Memory Bank" () to store the features of all images, and after each training iteration, the corresponding entry for each image in this Memory Bank is updated using the feature from the forward pass.
Since each image has a corresponding position in memory, the previous features can be quickly retrieved to reduce computational cost when dealing with large datasets. If the total number of images is large, calculating the denominator would be prohibitively expensive. For every image, this computation would be , and when reaches millions or more, it becomes almost unmanageable.
Noise-Contrastive Estimation
The core idea of NCE is:
- Transform a multi-class classification problem into multiple binary classification problems.
- The goal of the binary classification: distinguish between "real data samples" and "noise samples."
In the multi-class scenario, each image is treated as a "class." With NCE, for a given image, we only need to distinguish "whether it is this image" versus "not this image (noise)."
The approach is to treat "other images" as noise, or sample negative examples from a noise distribution (), and let the model learn to differentiate between positive and negative examples.
For example, to calculate the "probability that feature comes from the -th image," we can write:
Where:
- is the feature corresponding to the -th image (stored in the memory bank), and is the feature of some other image.
- is the "normalizing constant" to ensure that the probabilities for all sum to 1.
- If is large, calculating requires traversing all , which is computationally expensive.
The cleverness of NCE is that, in the case of "a large number of possible classes," it does not directly compute the full denominator of the formula. Instead, it separates the "positive sample" corresponding to the "class " and the "negative sample" corresponding to the "noise distribution."
In other words: anything that is not like me is a negative sample, so just pick a small batch to compute.
Let the noise distribution be uniform ().
The paper introduces a hyperparameter , which represents that "there are times more noise samples than real samples," and then defines a "posterior probability":
The meaning of is that, given feature and class , it is the probability that " comes from the -th image (real data), rather than from noise." is the output of the above formula, and is the relative probability of selecting a noise sample corresponding to class .
The next key point is:
- Take the negative log-likelihood for positive samples (positive samples are correctly classified as positive).
- Take the negative log-likelihood for negative samples (negative samples are correctly classified as negative).
It might seem like empty talk, but many people zone out when they see "calculating negative log-likelihood." Actually, it just means: calculate the probabilities for positive and negative samples separately, then add them together.
Thus, we have:
- Where represents the "real data distribution," i.e., the actual images (positive examples).
- represents the "noise distribution," i.e., the noise samples (negative examples).
- and are feature vectors retrieved from the Memory Bank (); one corresponds to the "positive sample" (), and the other is a randomly selected noise sample.
Intuitively, a larger means the model is more confident that " belongs to the -th image" (good); whereas a larger means the model correctly rejects the noise.
Approximation of
Although we have discussed many aspects, the biggest challenge remains unsolved.
We still need to calculate , which involves , and when is large, this is still a bottleneck.
A common approach in NCE is to treat as a "constant" for estimation or approximation, and not involve it in gradient updates. In this paper, the authors refer to the following work:
They use Monte Carlo approximation to estimate:
Here, is a set of randomly selected indices used to approximate the average value of the entire set.
Instead of summing all terms to calculate , now we only sample negative examples, perform the exponential operation on them, sum them up, and then multiply by the factor to approximate the overall mean.
The paper also mentions that experimentally, a good estimate can be obtained with just a few batches early in training, and this estimate can be fixed for the remainder of the training, which works well.
Proximal Regularization
Reference: Proximal Algorithms
Earlier, we asked: If classification anchors are not fixed but shift during training, how can the model ensure their stability?
Unlike typical classification problems, here each "class" only has "one training sample." In each training epoch, each class is only sampled once, which can lead to large oscillations in the learning process. For example, if one image happens to be overfitted or shifted by the model, a large gradient update may occur the next time it is encountered, causing significant fluctuations in the overall training objective.
To mitigate this instability caused by random sampling, the authors introduce the concept of Proximal Regularization. By adding a smoothness constraint to the loss function, they ensure that the feature vector does not differ too much from the previous iteration. This helps stabilize training and accelerate convergence.
Specifically, we assume two variables:
- Current iteration (iteration ): For training data , compute the feature vector .
- Memory Bank: Stores the feature vector from the previous iteration (iteration ), denoted as .
In the original NCE loss, an additional term is added.
Thus, the objective function becomes:
- The first term () is the original positive example loss in NCE.
- The second term () encourages the new feature not to differ too much from the previous iteration's .
Through this proximal term, if the feature vector changes too drastically during each update, it will be penalized. As training progresses and the model converges, the ideal scenario is , and the penalty term gradually diminishes, eventually returning to the original objective function.
After incorporating this, the authors present the final objective function with Proximal Regularization:
This version retains the original NCE components for "positive example " and "negative example " while adding the term to suppress drastic changes in feature vectors.
To verify the effectiveness of Proximal Regularization, the authors compare the impact of different values (such as 0, 10, 30, 50) on training:
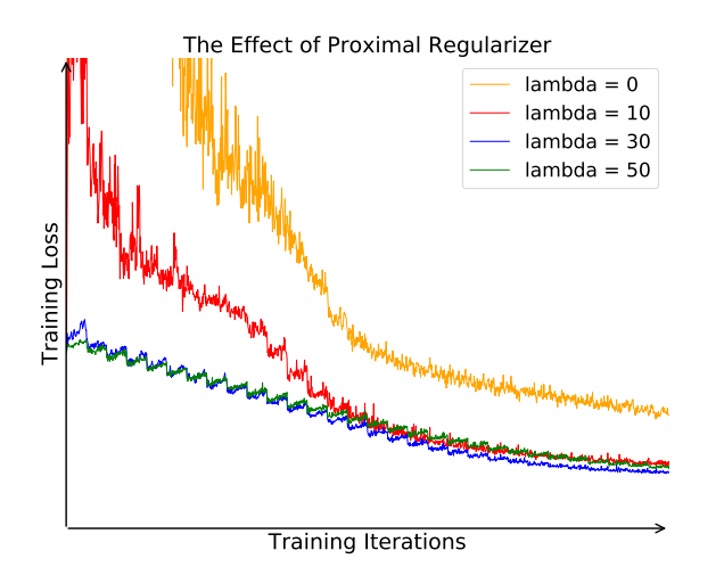
As shown in the figure above, when (i.e., no proximal term), the original objective function oscillates significantly during training and converges more slowly. With an appropriately sized , the objective function smooths out, converges faster, and ultimately learns better feature representations.
Discussion
Parametric vs Non-Parametric Softmax
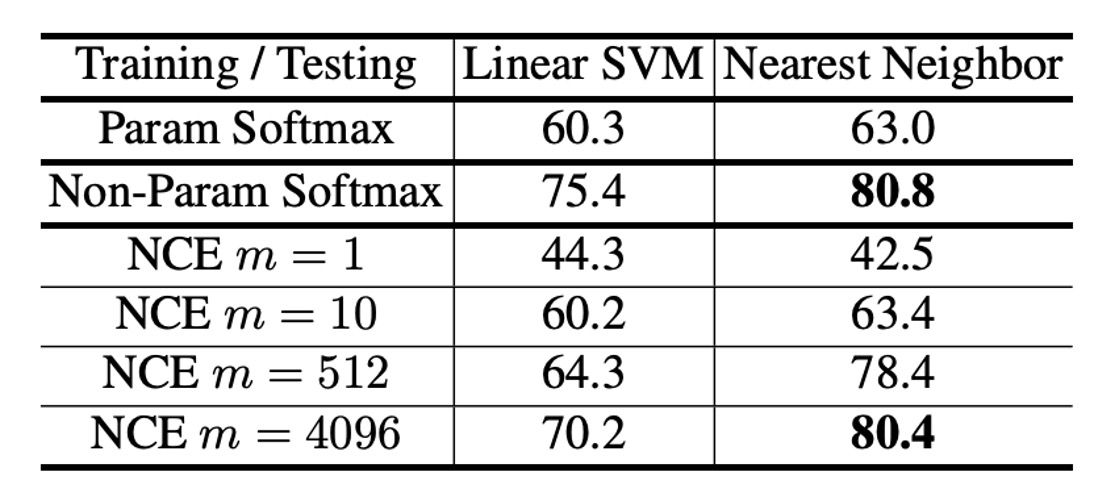
Since the core of this paper is the "non-parametric Softmax," the authors first conducted an experiment on CIFAR-10 to compare the performance of "parametric Softmax" and "non-parametric Softmax."
Since the CIFAR-10 dataset is relatively small, the non-parametric Softmax denominator can be directly computed, allowing a direct comparison of the two approaches. The evaluation methods used were Linear SVM and k-NN classifiers, applied to "parametric" and "non-parametric" features, and their accuracy rates were compared.
The results, shown in the table above, reveal that the parametric Softmax achieved accuracy rates of 60.3% for SVM and 63.0% for k-NN, while the non-parametric Softmax achieved 75.4% and 80.8%, respectively. This demonstrates a significant improvement in performance with the non-parametric Softmax, validating the authors' approach.
Additionally, the authors explored the effects of using NCE approximation in the non-parametric setting, as shown in the table. The hyperparameter in NCE indicates how many negative samples are drawn for each positive sample:
- When (only 1 negative sample), the k-NN accuracy dropped drastically to 42.5%, indicating excessive approximation (too few negative examples).
- As increases, the accuracy gradually rises. When , the results were close to the "full version" (), suggesting that with enough negative samples, NCE can closely approximate the complete non-parametric Softmax.
Performance in Image Classification Tasks
The authors then conducted larger-scale experiments on ImageNet to compare the performance of different methods across various network architectures.
The experimental setup was as follows:
- Dataset: ImageNet, approximately 1.28 million images, 1,000 categories.
- Temperature parameter : Set to 0.07.
- NCE negative samples : 4,096. The authors balanced "computational cost" and "feature quality."
- Training:
- Trained for 200 epochs using Momentum SGD.
- Batch size = 256.
- Initial learning rate of 0.03, maintained for the first 120 epochs, then decayed every 40 epochs by a factor of 0.1.
The authors listed several representative unsupervised (or self-supervised) learning methods, including:
- Random initialization (random initialization, as a lower bound).
- Self-supervised
- Adversarial learning
- Exemplar CNN
- Split-brain autoencoder: One of the recent self-supervised benchmark methods.
For fair comparison, the authors used multiple common architectures: AlexNet, VGG16, ResNet-18, and ResNet-50. Since network depth significantly influences results, they specifically compared the differences between "same method, different depth."
The evaluation methods were as follows:
- Linear SVM (conv1 ~ conv5): Trained a linear classifier on the intermediate features from different convolutional layers (such as conv1, conv2, conv3, ...) and tested the classification performance on the ImageNet validation set.
- k-NN (final 128-dimensional output): Directly applied nearest neighbor classification on the final 128-dimensional feature output.
The experimental results are shown in the table below:
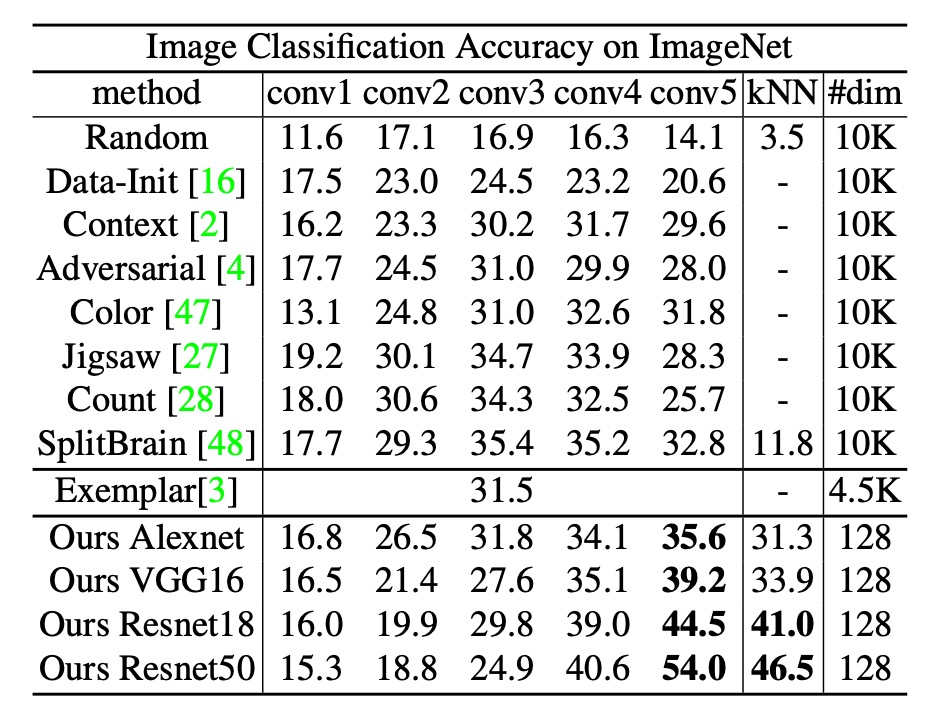
The authors' method achieved a top-1 accuracy of 35.6% in conv1 ~ conv5, outperforming previous methods, including Split-brain.
Next, when attempting deeper networks such as ResNet-50, the accuracy reached 54.0%, while Exemplar CNN, even using the deeper ResNet-101, only achieved 31.5%. This demonstrates that the authors' method achieves significant improvements as the network depth increases.
The k-NN classification results were close to those of the linear classifier (conv5), indicating that the final 128-dimensional features formed a good metric space. Moreover, the deeper the layer (such as conv4, conv5), the better the results, indicating the authors' method excels in extracting high-level features.
Finally, in terms of efficiency, many methods have features with more than 10,000 dimensions at the optimal layer (such as conv3, conv4), which are not friendly for storage and computation. In contrast, the authors' method only requires 128 dimensions for the final output, making it highly compact. Storing all features for the full ImageNet dataset (1.28 million images) takes only about 600 MB, and nearest neighbor retrieval on a Titan X GPU takes less than 20 ms.
Cross-Dataset Generalization
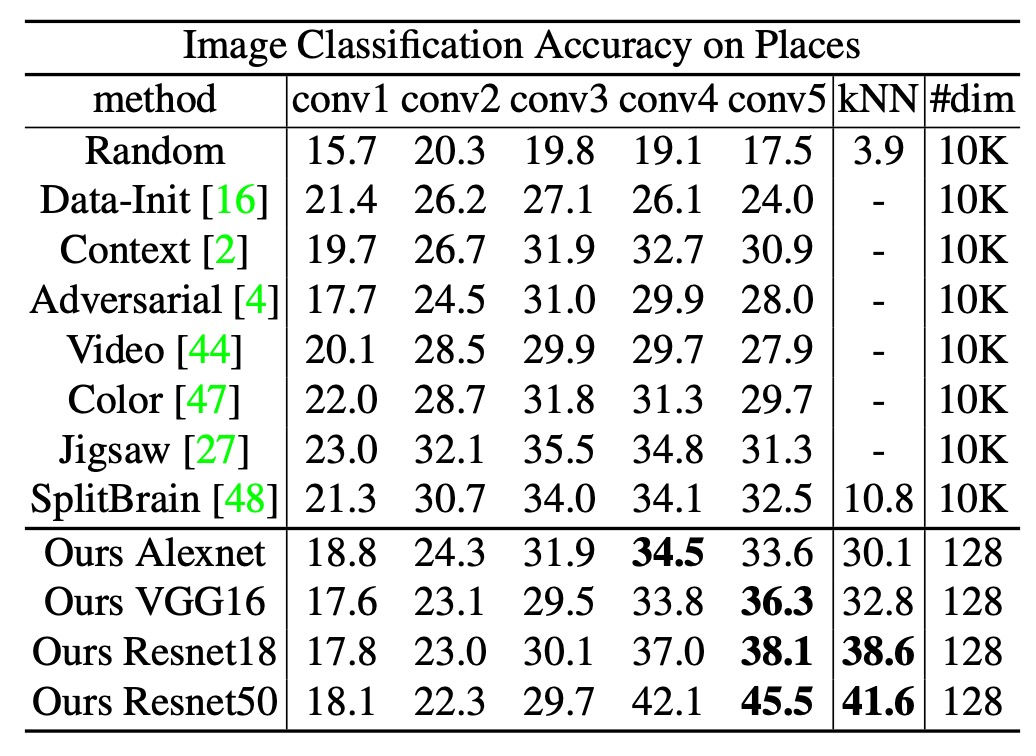
The authors then tested the features learned on ImageNet, directly applied to another large dataset, Places (2.45 million images, 205 categories), without fine-tuning, only feature extraction, and then trained a linear classifier or performed k-NN on Places.
The experimental results are shown in the table above. The method achieved accuracy rates of 45.5% and 41.6% on linear classification and k-NN for ResNet-50, outperforming other methods (such as Exemplar CNN, Split-brain, etc.).
These results demonstrate that the features learned on ImageNet can maintain good performance even in different domains (scene classification), showing the method's cross-domain generalization ability.
Ablation Experiment - Feature Dimension

After confirming that the model architecture is effective, the authors conducted some ablation experiments.
The first explores the impact of feature dimension. The authors compared feature dimensions of 32, 64, 128, and 256, with results shown in the table above.
The experiments show that performance significantly improves when the dimension increases from 32 to 128. However, the improvement from 128 to 256 saturates, meaning that 128 dimensions already provide sufficient representation power. While increasing the dimension further may bring slight benefits, it is not as significant as the earlier increase.
Ablation Experiment - Training Set Size

Next, the authors explored the impact of "training set size" on model performance. The experimental setup was as follows:
- ImageNet training set: Used 10%, 50%, and 100% of the images as the training set.
- Validation set: The complete ImageNet validation set was used for testing the model.
The experimental results are shown in the table above. As the training set size increases, the model performance continues to improve. This shows that the method effectively utilizes more unlabeled data to improve feature quality, and performs better with larger training sets.
This result is very appealing because it means that as long as we keep extracting more unlabeled data, this method can continually benefit and learn stronger features.
Visualization Analysis

Finally, the authors presented some feature visualization results, which demonstrate the "image search by image" functionality. By comparing image features, the model finds the closest images to the "query."
The experimental results are shown in the figure above:
- Best case (top four rows): The top 10 retrieved images are all from the same category as the query image (indicating that the model's metric space is extremely precise).
- Worst case (bottom four rows): The top 10 images are not from the same "real class," but are visually or shape-wise very similar. For example, although they belong to different species or categories, they look similar (e.g., having the same black-and-white stripes or similar shapes and backgrounds).
The authors point out that even in "failure cases," visually similar images can still be retrieved, which proves that the "instance-level" embedding space truly captures visual features, rather than just random correspondences.
Conclusion
The paper also includes experiments applied to "semi-supervised classification" and "object detection," but we won't go into detail here. Interested readers can refer to the original paper.
Overall, these experiments thoroughly validate the versatility and scalability of the authors' approach: it is effective not only for classification and retrieval but also demonstrates good generalization across different network architectures, data scales, and downstream tasks (semi-supervised classification, detection).
After the paper's release, the unsupervised learning framework based on NCE loss quickly achieved impressive results on large-scale datasets and demonstrated strong performance in practical applications.
There are still several classic papers to follow up on, so let’s continue reading.