[20.06] BYOL

No Need for Negative Samples
Bootstrap your own latent: A new approach to self-supervised Learning
While everyone is actively discussing how to design negative samples, the authors of this paper stand out by proposing an approach that doesn’t require negative samples.
The authors claim: as long as you learn from yourself, the model can surpass its own limits.
Problem Definition
The core concept of contrastive learning is to pull together representations of the same image from different views (referred to as "positive sample pairs") while pushing apart representations from different images (referred to as "negative sample pairs") to learn representations.
However, these methods require carefully designed negative sample handling strategies, such as large-batch training (SimCLR) or memory banks (MoCo), to ensure effective learning.
Furthermore, these methods heavily rely on image augmentations, with techniques like random cropping proven to be very effective in experiments.
Given how troublesome the design of negative samples can be, is there a way to avoid them altogether?
If you haven’t read SimCLR and MoCo yet, you can refer to our previous articles:
Solution
Model Architecture
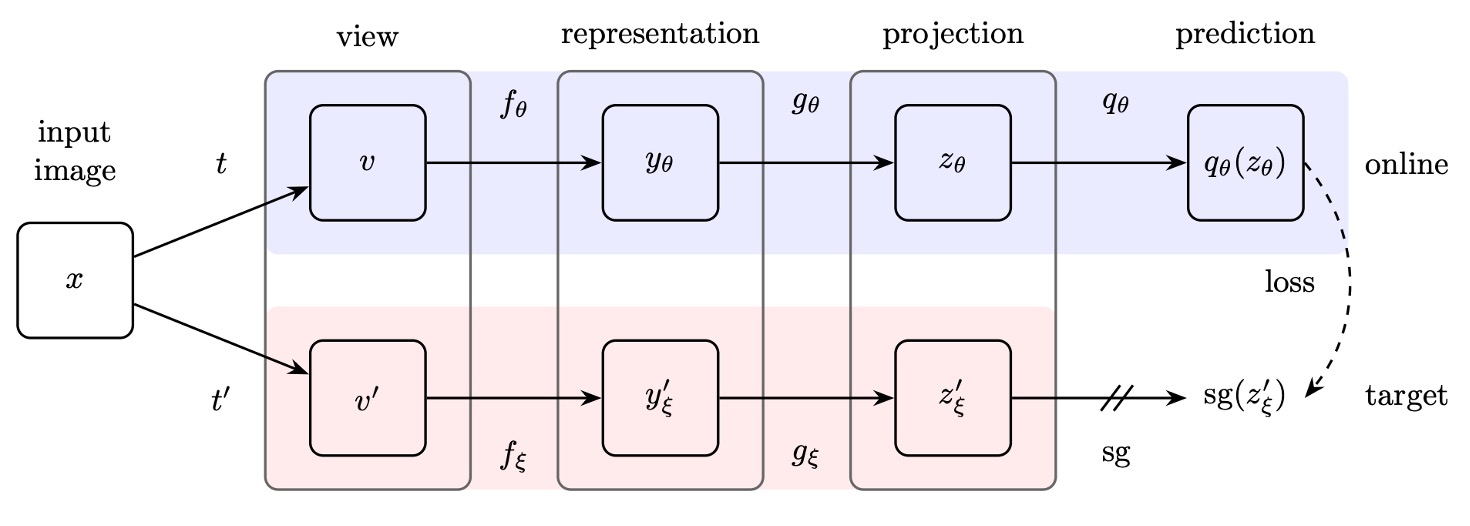
The authors propose the BYOL architecture, which consists of two parts: an online network and a target network:
-
Online Network: The upper half of the figure above, consisting of three parts:
- Encoder : Converts the input image into features.
- Projector : Maps the features into a high-dimensional space, similar to contrastive learning methods like SimCLR.
- Predictor : Learns a nonlinear mapping in the projected space to predict the output of the target network.
-
Target Network:
The structure is the same as the online network, but with different parameters , which are an exponentially moving average (EMA) of the online network parameters . The update rule is as follows:
Here, is the decay factor that controls the update speed of the target network.
Training Process
The BYOL training process begins with a given image dataset . A random image is selected, and two different image augmentations and are applied to generate two different views:
Where , .
For the first augmented view , the online network computes:
For the second augmented view , the target network computes:
At this point, we see that and are quite similar because the model architecture is the same, and the parameters are updated using EMA. If we directly perform contrastive learning on these two outputs, the model usually collapses.
Since they are so similar, the model doesn’t need to learn and can just pull the two outputs together. To solve this problem, the authors introduce a new mechanism. The idea is to pass through a projection head to obtain a predicted output:
Then, and are compared and pulled together, transforming the whole framework into a "prediction" problem rather than a "contrast" problem.
Finally, to ensure numerical stability, normalization is applied when comparing these vectors (making their norms equal to 1):
Loss Function
Here, the authors do not use InfoNCE, but instead use Mean Squared Error (MSE) as the loss function:
Expanding the computation:
Where is the inner product of two unit vectors, representing the cosine similarity between them.
Additionally, to symmetrize the learning, the views are swapped during training: passes through the online network, and passes through the target network. The same loss is then computed again:
The final total BYOL loss is:
Implementation Details
BYOL adopts the same image augmentation strategy as SimCLR:
- Random cropping and resizing to resolution.
- Random horizontal flipping.
- Color jittering (randomly changing brightness, contrast, saturation, and hue).
- Grayscale conversion (optional).
- Gaussian blur.
- Solarization.
For the network architecture, BYOL uses ResNet-50 as the base encoder and , and tests deeper ResNet variants (50, 101, 152, 200 layers) and wider variants (1× to 4×) in different experiments.
The detailed network structure is as follows:
- Output feature dimension: 2048 (when width multiplier is 1×).
- Projection layer (MLP):
- First layer: Linear layer with output dimension 4096.
- Batch normalization.
- ReLU activation.
- Final linear layer: Output dimension 256.
- Predictor: Same structure as the projection layer.
Unlike SimCLR, BYOL does not apply batch normalization to the output of the projection layer, as batch normalization may affect learning stability when there are no negative sample pairs.
Finally, BYOL uses the LARS optimizer with a cosine decay learning rate schedule:
- Train for 1000 epochs, with the first 10 epochs performing learning rate warmup.
- The base learning rate is:
- Weight decay: .
- Exponential moving average parameter : Starting value of 0.996, gradually increasing to 1 over training: Where is the current step, and is the maximum number of steps.
Discussion
Why Doesn’t BYOL Collapse?
This section is arguably the most interesting part of the paper.
In contrastive learning, the design of negative sample pairs ensures that the model does not collapse into a trivial constant representation.
Since BYOL does not have an explicit regularization term to avoid collapse during training, why doesn’t it collapse?
To address this, the authors provide a detailed explanation:
-
The target network parameters in BYOL are not updated through gradient descent. Therefore, the update direction for these parameters is not along the gradient of the loss function :
This type of update mechanism is similar to the learning dynamics in Generative Adversarial Networks (GANs), where the generator and discriminator learn through mutual competition rather than simply minimizing a joint loss function. Therefore, BYOL’s learning process is not a simple gradient descent on a loss function, and this dynamic reduces the likelihood of convergence to a trivial solution.
-
Further analysis assumes that the predictor is optimal (i.e., it minimizes the expected squared error):
The optimal should satisfy:
Under these conditions, it is possible to derive the update direction of BYOL’s parameters. The gradient update with respect to is related to the conditional variance:
where represents the -th feature component of .
This indicates that BYOL is actually minimizing the conditional variance, that is, reducing the variability of the target representation relative to the current representation . Based on the fundamental properties of variance, for any random variables , we have:
If we let:
- (target projection)
- (current online projection)
- be additional variability in the training dynamics
Then, we get:
This shows that BYOL cannot lower the conditional variance simply by discarding information, which contradicts the collapse solution (trivial representation), because a collapse solution would be unstable in BYOL.
-
Finally, let’s analyze the update mechanism for the target network parameters .
Suppose we directly transfer the online network parameters to the target network:
This would indeed quickly transfer the new variability of the online network to the target network, but it could destroy the assumption of optimality for the predictor, leading to instability in training. Therefore, BYOL uses exponential moving average to update the target network:
This smooth update strategy ensures that changes to the target network are gradual, allowing the predictor to stay close to optimal, which in turn stabilizes the overall learning process.
Performance on ImageNet
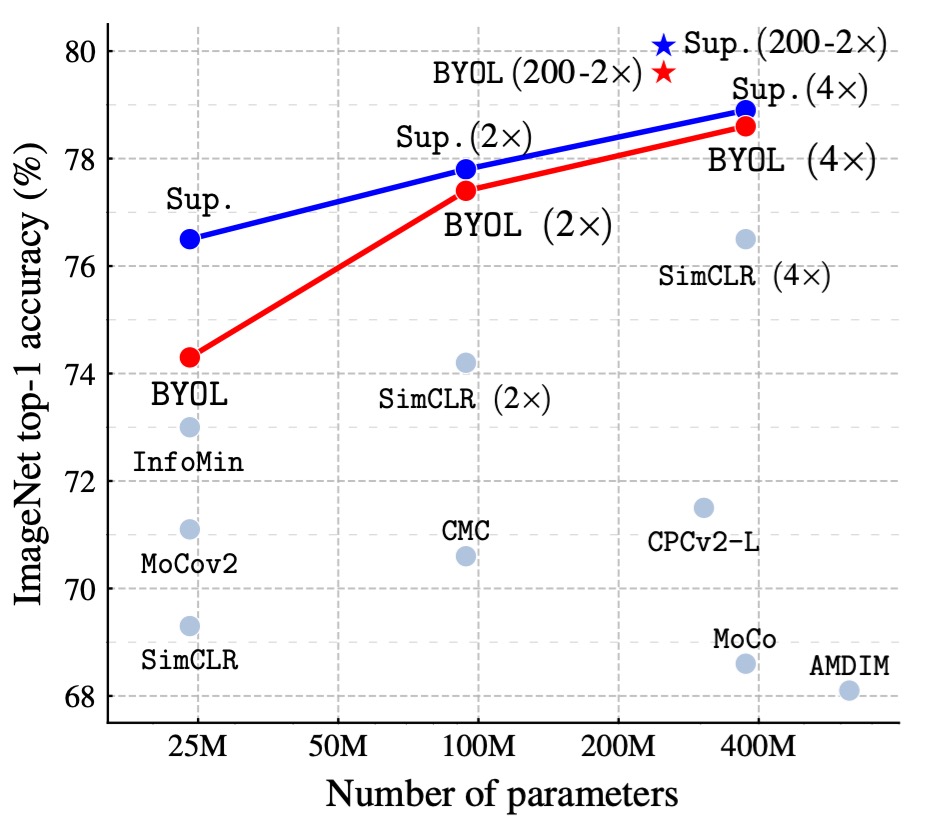
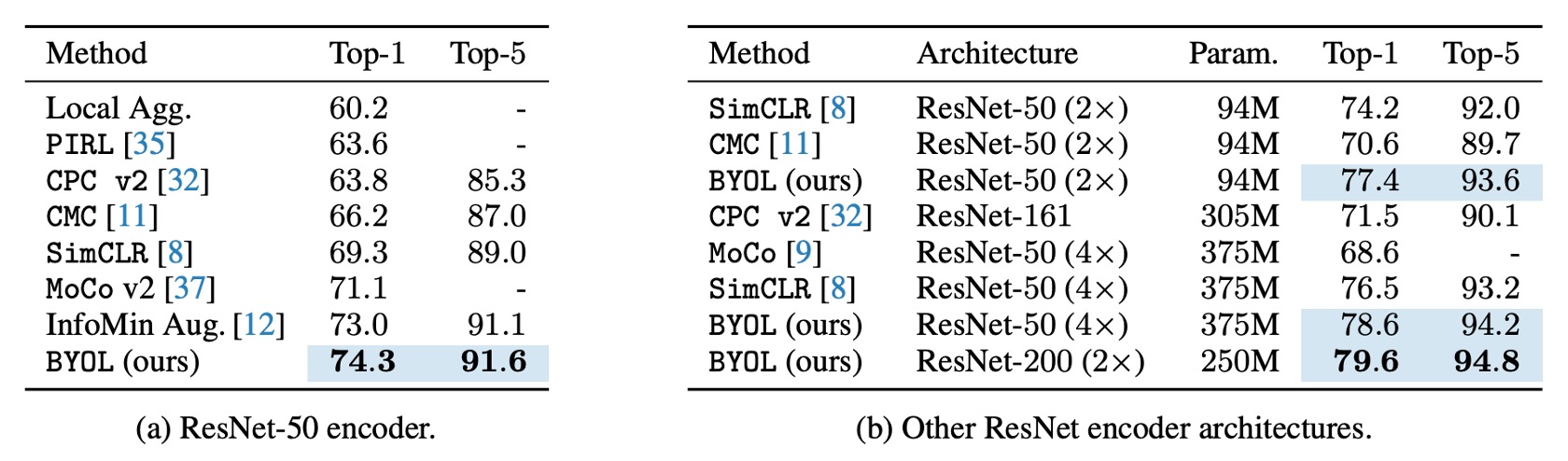
Following the standard linear evaluation protocol, the authors train a linear classifier on the frozen representations from BYOL pretraining and measure the Top-1 and Top-5 accuracy.
On the ResNet-50 (1×) architecture, BYOL achieves a Top-1 accuracy of 74.3% (Top-5 accuracy of 91.6%), outperforming previous state-of-the-art self-supervised methods by 1.3% (Top-1) and 0.5% (Top-5).
BYOL reduces the gap to the supervised learning baseline (76.5%) but is still below the stronger supervised learning baseline (78.9%).
On deeper and wider ResNet architectures (such as ResNet-50(4×)), BYOL continues to surpass other self-supervised methods, achieving a best result of 79.6% Top-1 accuracy, which is very close to the best supervised baseline.
BYOL achieves performance comparable to, or even better than, contrastive learning methods without requiring negative samples and approaches the supervised learning benchmark. Detailed table data is shown below:
Ablation Studies - Part 1
The authors performed a series of ablation studies to explore the impact of key factors in the BYOL design on the final model performance:
-
Impact of Batch Size on Performance:
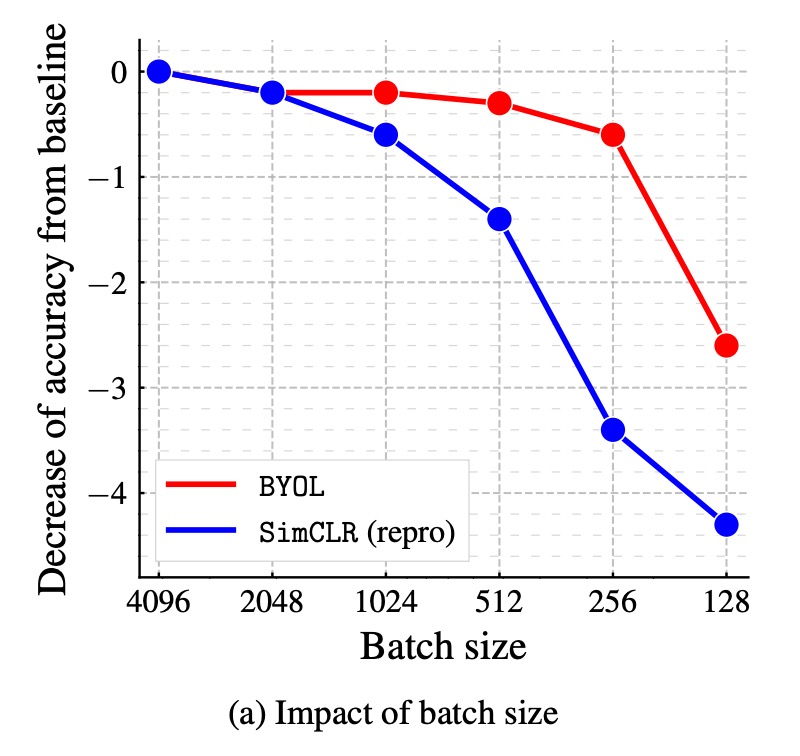
In contrastive learning methods, the batch size directly affects the number of negative samples. When the batch size is reduced, the number of negative samples decreases, leading to a worse training performance. Since BYOL does not rely on negative samples, it should theoretically be more robust.
The authors compared the performance of BYOL and SimCLR across batch sizes ranging from 128 to 4096. The results show that BYOL performs stably within the 256-4096 range, with performance starting to degrade only when the batch size is too small. In contrast, SimCLR's performance drops sharply as the batch size decreases, which is related to the reduced number of negative samples.
-
Impact of Image Augmentation:
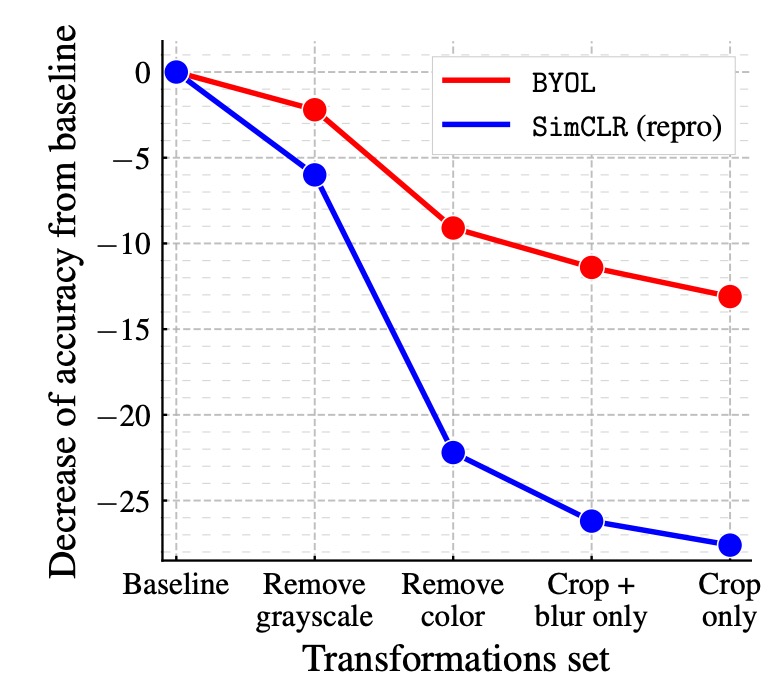
Contrastive learning methods are highly dependent on image augmentations, especially color jittering. This is because randomly cropped views often share color information, but the color variation between views from different images is larger. Without color augmentation, contrastive learning might only learn color histogram-based distinctions, rather than deeper features.
The authors compared the performance of BYOL and SimCLR under different image augmentation combinations. The results show that BYOL is less dependent on image augmentation. Even when color jittering is removed or only random cropping is used, BYOL still maintains a high accuracy.
-
Impact of Bootstrapping:

One of the core mechanisms of BYOL is using the target network to provide learning targets, where the target network weights are the exponential moving average (EMA) of the online network weights. If the decay rate is set to 1, the target network never updates, effectively using a fixed random network. If the decay rate is set to 0, the target network updates every step along with the online network.
The authors tested different target network update rates. The results show that:
- If the target network updates too quickly, the learning process becomes unstable because the learning target changes too rapidly.
- If the target network updates too slowly, learning progresses slowly, and the learned features are of poor quality.
- Using an appropriate EMA strategy (e.g., ) strikes the best balance between stability and learning efficiency.
Ablation Studies - Part 2
The authors further explore the relationship between BYOL and other contrastive learning methods and analyze why BYOL outperforms SimCLR.
Starting from InfoNCE, they consider an extended InfoNCE loss function:
Where:
-
: Temperature hyperparameter.
-
: Negative sample influence coefficient.
-
: Batch size.
-
: Augmented views in the batch, with and being different augmented versions of the same image.
-
: Similarity function between views, defined as:
Where:
- SimCLR:
- (no predictor used).
- (no target network used).
- (using negative samples).
- BYOL:
- (uses predictor).
- (uses target network).
- (does not use negative samples).
- SimCLR:
Based on the above setup, the experimental results are shown in the table below:
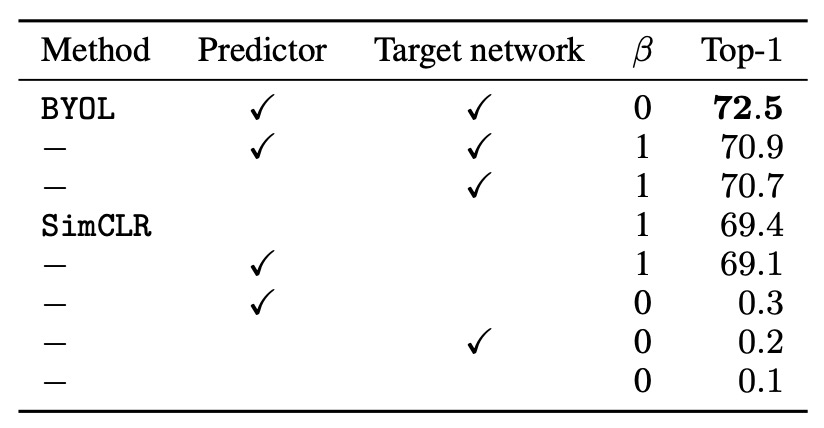
First, they test different values of to verify whether negative sample pairs are necessary:
- When (using negative sample pairs): The SimCLR loss function is recovered.
- When (no negative sample pairs): Only BYOL (with target network and predictor) is able to effectively learn.
The results show that BYOL is the only method that can maintain good performance without negative sample pairs.
Next, they add a target network to SimCLR to observe its impact on performance. The results show that adding a target network improves SimCLR's accuracy by 1.6%, highlighting the importance of the target network in contrastive learning methods.
Finally, they test adding only a predictor to SimCLR, and the performance improvement is limited compared to adding a target network. The authors believe that the combination of the predictor and target network is a key factor in avoiding the collapse solution in BYOL.
Conclusion
The innovation of BYOL lies in completely removing the need for negative sample pairs and using the combination of a target network and a predictor to avoid the collapse solution. On ImageNet, BYOL achieves state-of-the-art self-supervised learning results and is close to the supervised learning baseline. Additionally, BYOL outperforms many existing contrastive learning methods.
There has been much discussion regarding whether BYOL can truly eliminate the need for negative samples. After the publication of the paper, several articles addressed the "BN cheating" issue we previously discussed, which is quite interesting. Relevant discussions are as follows:
-
Critiques from other researchers:
-
The authors’ responses and follow-up experiments:
In short, after several rounds of experiments, other researchers found that when BYOL removed the BN structure, the model failed to converge. It was speculated that BN provided implicit negative samples, allowing the model to perform contrastive learning.
If this conclusion holds true, the innovation of BYOL (i.e., not requiring negative samples) would be undermined.
To defend the innovation of BYOL, the authors conducted a series of experiments and eventually found that even without BN, as long as the model was appropriately adjusted, BYOL could still be trained without BN and achieve performance comparable to the original setup.
Therefore, the authors' final conclusion is that the role of BN in BYOL is "not" to provide implicit negative samples, but to stabilize the training process, which is one of the reasons why BYOL can be trained without negative samples.
The "BN cheating" issue was also mentioned in MoCo v1, where the authors used the "Shuffle BN" method to address this problem.