Submission
In the real world, you are bound to encounter situations where things don't work as expected.
Our model is no different; it may not handle all situations effectively. If during your use of our model, you find scenarios where our model fails to perform adequately, we encourage you to provide us with some datasets. We will then adjust and optimize our model based on your data.
We appreciate your willingness to contribute datasets and will test and integrate them as soon as possible.
Format Instructions
Here is an example of the format for submitting data:
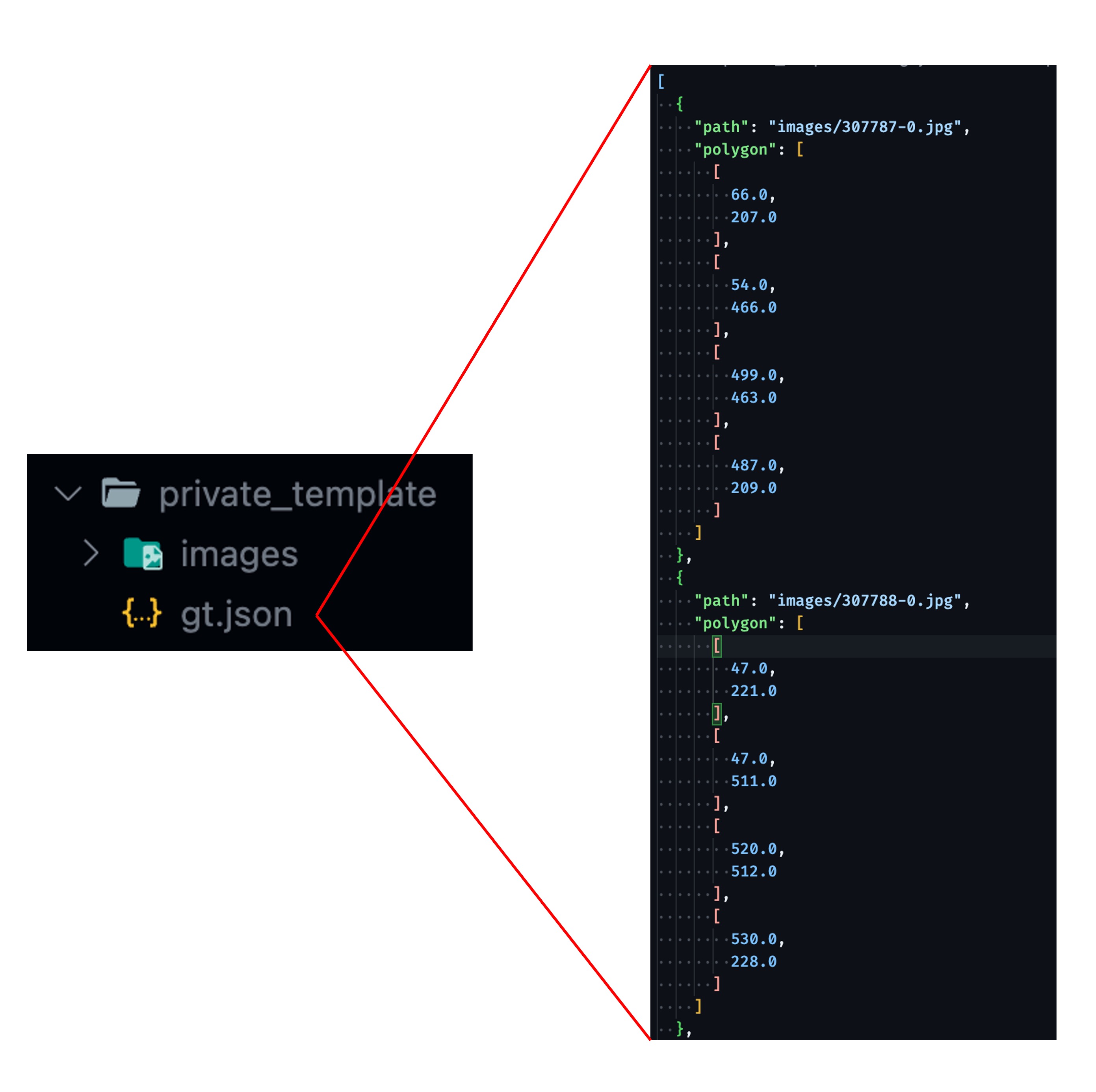
As you can see, first there is a dataset containing your collected images, and in the same directory, there is a gt.json file containing labels for each image.
The label format must include:
- Image Relative Path
- The 'four corner points polygon' boundaries of the document in the image
A simple data structure might look like this:
[
{
"file_path": "path/to/your/image.jpg",
"polygon": [
[
[0, 0],
[0, 1080],
[1920, 1080],
[1920, 0]
]
]
}
]
After you have labeled your data, we recommend uploading it to your Google Drive and providing the link to us via email. We will test and integrate your data as soon as we receive it. If your data does not meet our requirements, we will notify you promptly.
-
Reasons for non-compliance may include:
-
Insufficient Dataset Precision:
For example, some images in your dataset might have inaccurate labels, or some image labels might be incorrect.
-
Unclear Labeling Objectives:
Our goal is to locate the four corners of documents in images, so if your data contains more than "one target" or more than "four corners," it cannot be used.
-
Target Too Small:
If your target is too small, we recommend reconsidering your algorithm choice, as our model is not suitable for handling small targets and does not align well with our processing goals.
-
Overly Refined Dataset Scale:
Even if you provide just tens of images, we will gladly accept them, but such data might cause overfitting if used to fit models, so we would advise increasing the dataset size to avoid this issue.
-
The data format and naming standards mentioned above are not strict; essentially, including the image path and polygon boundaries is sufficient, but to facilitate our testing, please try to follow the format above.
For labeling data, we recommend using LabelMe, an open-source labeling tool that helps you quickly label images and export them as JSON files.
FAQs
-
Is the order of the four corners important?
- No. Our training process will automatically sort these points.
-
What are the requirements for label formatting?
- The format requirements are not strict; just include the image path and polygon boundaries. However, for ease of testing, it is recommended to stick to the standard format.
-
How important is the filename?
- The filename is not a primary concern as long as it correctly links to the corresponding image.
-
What image format do you recommend?
- We recommend using jpg format to save space.
-
How does the accuracy of labeling affect model training?
- Label accuracy is extremely important; inaccurate labels will directly impact the effectiveness of model training.
-
How important is the type of target in the labels?
- Yes, it is crucial.
- The target must be a document, and each image should contain only one target.
-
How does the size of the target affect model training?
- The size of the target is important. Our model is not suited for small targets as this impacts the efficiency of subsequent processing.
-
How do you define 'small targets'?
- For an image with a resolution of 1920x1080, if the target is smaller than 32 x 32 pixels, it is considered a small target. The specific formula is
min(img_w, img_h) / 32.
- For an image with a resolution of 1920x1080, if the target is smaller than 32 x 32 pixels, it is considered a small target. The specific formula is
Contact Us
For further assistance, please contact us via email: docsaidlab@gmail.com