
The stock codes in the Taiwanese market change periodically, making manual tracking impractical.
It's time to automate!
Setup Environment
Let's tackle the challenge by writing a program. First, install the necessary packages:
pip install requests beautifulsoup4 json
Assuming you have a functional Python environment.
Target Webpages
Stock-related data resides on the website of the Taiwan Stock Exchange (TWSE). Let's identify the target pages:
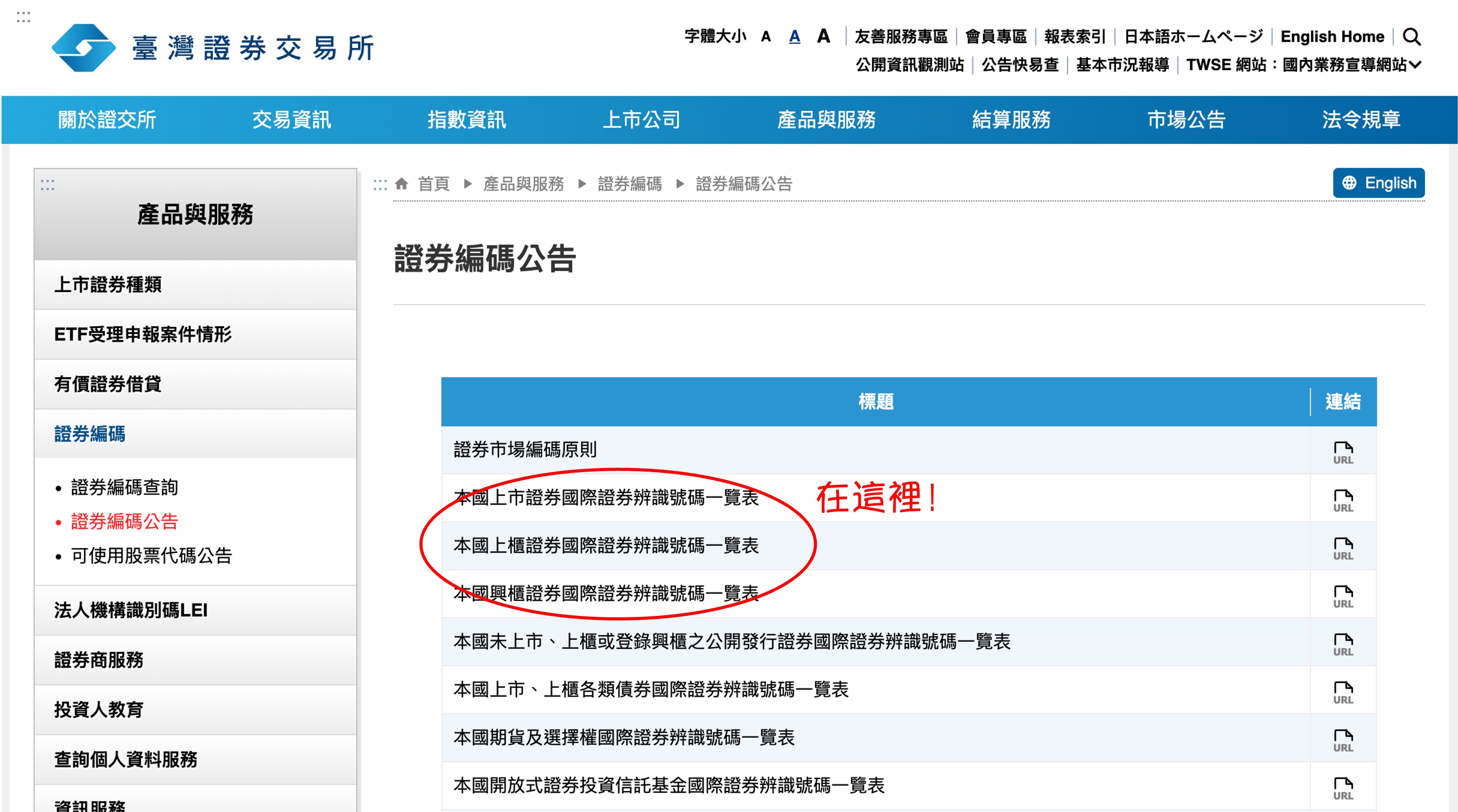
Note down these three URLs:
urls = [
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=2", # Listed securities
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=4", # OTC securities
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=5" # Emerging stocks
]
Parsing the Webpage
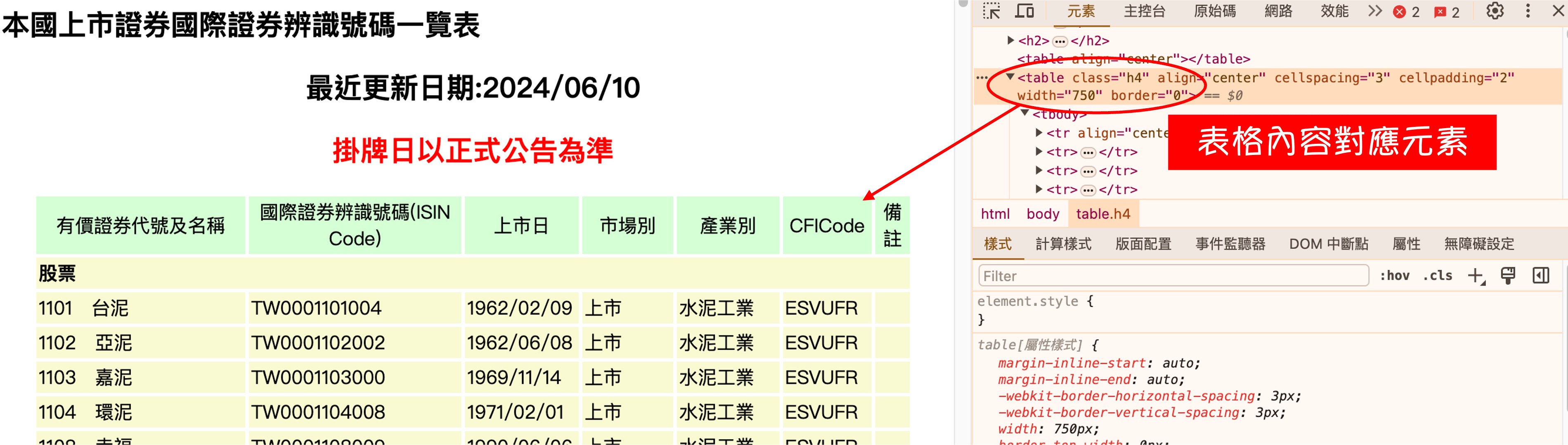
Upon inspecting the webpage, we identify that the main table corresponds to the HTML tag class=h4.
Now that we've located our target, let's start coding:
import json
import requests
from bs4 import BeautifulSoup
# Retrieve content from Taiwan Stock Exchange announcements
urls = [
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=2", # Listed securities
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=4", # OTC securities
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=5" # Emerging stocks
]
# All data infos
data = {}
total_urls = len(urls)
for index, url in enumerate(urls, start=1):
print(f"Processing URL {index}/{total_urls}: {url}")
response = requests.get(url)
response.encoding = 'big5' # Set the correct encoding
# Parse HTML using BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', {'class': 'h4'})
if not table:
print(f"Table not found for URL: {url}")
continue
for row in table.find_all('tr')[1:]: # Skip header row
cells = row.find_all('td')
if len(cells) != 7:
continue
code, name = cells[0].text.split("\u3000")
internationality = cells[1].text
list_date = cells[2].text
market_type = cells[3].text
industry_type = cells[4].text
data[code] = {
"Name": name,
"Code": code,
"Market Type": market_type,
"Industry Type": industry_type,
"Listing Date": list_date,
"International Code": internationality
}
with open("stock_infos.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("All data has been processed and saved to stock_infos.json")
Output Results
{
"1101": {
"Name": "Taiwan Cement",
"Code": "1101",
"Market Type": "Listed",
"Industry Type": "Cement Industry",
"Listing Date": "1962/02/09",
"International Code": "TW0001101004"
},
"1102": {
"Name": "Asia Cement",
"Code": "1102",
"Market Type": "Listed",
"Industry Type": "Cement Industry",
"Listing Date": "1962/06/08",
"International Code": "TW0001102002"
},
...omitting the rest...
}
We output the result as a JSON file for convenient integration with other programs.
FAQs
I only want ordinary stocks.
I assume you mean stocks with "four-digit" codes, excluding ETFs, warrants, etc. To achieve this, simply add a filtering condition in the program:
if len(code) != 4:
continue
I only want specific industries.
This requirement can be extended to specific market types, industry types, listing dates, or even the previous "ordinary stocks" question. We just need to load the output JSON file into Pandas and filter with conditions:
import pandas as pd
df = pd.read_json("stock_infos.json", orient="index")
target = df[df["Industry Type"] == "Cement Industry"]
The program is broken.
That could be due to changes in the TWSE website's layout, causing the HTML structure to alter. We'll need to adjust the code accordingly.
Conclusion
By periodically running this program, we can obtain the latest stock information.
Since you're here, why not take a moment to enjoy a cup of tea before you go?
We also wrote an API to integrate FinMind's stock data. By clicking the download button below, you can retrieve the latest stock information from FinMind. The data format may differ from the one used by the stock exchange, but you probably won't mind.
☕ Fuel my writing with a coffee
Your support keeps my AI & full-stack guides coming.
AI / Full-Stack / Custom — All In
From idea to launch—efficient systems that are future-ready.
All-In Bundle
- Consulting + Dev + Deploy
- Maintenance & upgrades
🚀 Ready for your next project?
Need a tech partner or custom solution? Let's connect.