評估模型
本專案的測試資料集為私有資料集。我們僅提供這份資料集的評估結果。
這份資料集包含大約兩萬多張經過「定位裁切」後的文件圖像,包含七種不同的類別,其數量極度不均衡。數據中存在大量不同光影變化、模糊、反光、角點定位誤差所導致的裁切形變等。
我們僅清洗該資料集的「錯誤類別標註」,而後將所有資料用於評估模型的效能。
評估協議
AUROC
AUROC (Area Under the Receiver Operating Characteristic Curve,接收者操作特徵曲線下面積) 是用於評估分類模型效能的統計指標,特別是在處理二分類問題時。AUROC 值的範圍從 0 到 1,一個較高的 AUROC 值表示模型具有較好的區分兩個類別的能力。
-
ROC 曲線
- 定義:ROC 曲線是一個圖形化的評估工具,展示了分類模型在所有可能的分類閾值下的表現。 它透過將真正例率(TPR, True Positive Rate)和假正例率(FPR, False Positive Rate)在不同閾值下的值繪製在圖表中來實現。
- 真正例率(TPR):也被稱為敏感度,計算公式為 TPR = TP / (TP + FN),其中 TP 是真正例的數量,FN 是假負例的數量。
- 假正例率(FPR):計算公式為 FPR = FP / (FP + TN),其中 FP 是假正例的數量,TN 是真負例的數量。
-
AUROC 的計算
- AUROC 是 ROC 曲線下的面積。 它提供了一個度量值來總結模型在所有分類閾值下的表現。
- 分析方式:
- AUROC = 1:完美分類器,能夠完全區分兩個類別。
- 0.5 < AUROC < 1:模型具有區分一定的能力,AUROC 值越接近 1,模型的效能越好。
- AUROC = 0.5:無區分能力,相當於隨機猜測。
- AUROC < 0.5:比隨機猜測還差,但如果模型預測反向解釋,可能會有較好的效能。
TPR@FPR 閾值表
TPR@FPR 閾值表是在人臉辨識領域中廣泛使用的一種關鍵評估工具,其主要用途是衡量模型在不同閾值設定下的表現。這種表格是基於 ROC 曲線衍生出來的,提供了一種直觀且精確的方法來評估模型效能。
例如:若目標是在 FPR(假陽性率)為 0.01 時達到至少 TPR(真陽性率)0.9 的效能,我們可以透過 TPR-FPR 閾值表來確定相對應的閾值,並根據這個閾值來判定推論的結果。
在本專案的實作中,我們也使用這個評估方法。我們選擇 TPR 在 FPR 為 0.0001 時的表現作為標準,這樣的標準幫助我們更準確地理解模型在特定條件下的效能。
Zero-shot Testing
我們採取零樣本測試策略,確保測試資料中的所有類別或樣態都沒有出現在訓練資料中。這意味著在模型的訓練階段,它未曾接觸或學習任何測試集的樣本或類別。 這樣做的目的是為了評估和驗證模型在面對完全未知的數據時的泛化能力和辨識性能。
這種測試方法特別適用於評估零樣本學習(Zero-shot Learning)模型,因為零樣本學習的核心挑戰在於處理模型在訓練期間從未見過的類別。 在零樣本學習的脈絡中,模型通常需要利用其他形式的輔助資訊(如類別的文字描述、屬性標籤或類別間的語意關聯)來建立對新類別的理解。 因此,在零樣本測試中,模型必須依賴它從訓練類別中學到的知識,以及類別間的潛在關聯,來辨識測試集中的新樣本。
消融實驗
-
Global settings
- Num of classes: 394,080
- Num of epochs: 20
- Num of data per epoch: 2,560,000
- Batch Size: 512
- Optimizer: AdamW
- Setting:
- flatten: Flatten -> Linear (Default)
- gap: GlobalAveragePooling2d -> Linear
- squeeze: Conv2d -> Flatten -> Linear
-
綜合比較
Name TPR@FPR=1e-4 ROC FLOPs (G) Size (MB) lcnet050-f256-r128-ln-arc 0.754 0.9951 0.053 5.54 lcnet050-f256-r128-ln-softmax 0.663 0.9907 0.053 5.54 lcnet050-f256-r128-ln-cos 0.784 0.9968 0.053 5.54 lcnet050-f256-r128-ln-cos-from-scratch 0.141 0.9273 0.053 5.54 lcnet050-f256-r128-ln-cos-squeeze 0.772 0.9958 0.052 2.46 lcnet050-f256-r128-bn-cos 0.721 0.992 0.053 5.54 lcnet050-f128-r96-ln-cos 0.713 0.9944 0.029 2.33 lcnet050-f256-r128-ln-cos-gap 0.480 0.9762 0.053 2.67 efficientnet_b0-f256-r128-ln-cos 0.682 0.9931 0.242 19.89 -
目標類別數量比較
Name Num_Classes TPR@FPR=1e-4 ROC lcnet050-f256-r128-ln-arc 16,256 0.615 0.9867 lcnet050-f256-r128-ln-arc 130,048 0.666 0.9919 lcnet050-f256-r128-ln-arc 390,144 0.754 0.9951 - 類別數量越多,模型效果越好。
-
MarginLoss 比較
Name TPR@FPR=1e-4 ROC lcnet050-f256-r128-ln-softmax 0.663 0.9907 lcnet050-f256-r128-ln-arc 0.754 0.9951 lcnet050-f256-r128-ln-cos 0.784 0.9968 - 單獨使用 CosFace 或 ArcFace 時,ArcFace 效果好。
- 搭配 PartialFC 後,CosFace 效果好。
-
BatchNorm vs LayerNorm
Name TPR@FPR=1e-4 ROC lcnet050-f256-r128-bn-cos 0.721 0.9921 lcnet050-f256-r128-ln-cos 0.784 0.9968 - 使用 LayerNorm 效果優於 BatchNorm。
-
Pretrain vs From-Scratch
Name TPR@FPR=1e-4 ROC lcnet050-f256-r128-ln-cos-from-scratch 0.141 0.9273 lcnet050-f256-r128-ln-cos 0.784 0.9968 - 使用 Pretrain 是必要的,可以節省我們大量的時間。
-
降低模型規模的方法
Name TPR@FPR=1e-4 ROC Size (MB) FLOPs (G) lcnet050-f256-r128-ln-cos 0.784 0.9968 5.54 0.053 lcnet050-f256-r128-ln-cos-squeeze 0.772 0.9958 2.46 0.053 lcnet050-f256-r128-ln-cos-gap 0.480 0.9762 2.67 0.053 lcnet050-f128-r96-ln-cos 0.713 0.9944 2.33 0.029 - 方法:
- flatten: Flatten -> Linear (Default)
- gap: GlobalAveragePooling2d -> Linear
- squeeze: Conv2d -> Flatten -> Linear
- 降低解析度和特徵維度
- 使用 squeeze 方法,雖犧牲一點效能,但減少一半的模型大小。
- 使用 gap 方法,準確度大幅降低。
- 降低解析度和特徵維度,準確度小幅降低。
- 方法:
-
加大 Backbone
Name TPR@FPR=1e-4 ROC lcnet050-f256-r128-ln-cos 0.784 0.9968 efficientnet_b0-f256-r128-ln-cos 0.682 0.9931 - 參數量增加,效果降低,我們認為這個跟訓練資料集的資料多樣性有關。由於我們所採用的方式無法提供太多的多樣性,因此增加參數量並不能提高效果。
-
引入 ImageNet1K 資料集及使用 CLIP 模型進行知識蒸餾
Dataset with CLIP Norm Num_Classes TPR@FPR=1e-4 ROC Indoor X LN 390,144 0.772 0.9958 ImageNet-1K X LN 1,281,833 0.813 0.9961 ImageNet-1K V LN 1,281,833 0.859 0.9982 ImageNet-1K V LN + BN 1,281,833 0.912 0.9984 由於資料集規模擴大,原本的設定參數已經無法順利地讓模型收斂。
因此我們對模型進行了一些調整:
- Settings
- Num of classes: 1,281,833
- Num of epochs: 40
- Num of data per epoch: 25,600,000 (如果模型無法順利收斂,可能是資料量不足。)
- Batch Size: 1024
- Optimizer: AdamW
- Learning Rate: 0.001
- Learning Rate Scheduler: PolynomialDecay
- Setting:
- squeeze: Conv2d -> Flatten -> Linear
- 使用 ImageNet-1K 將類別擴充到約 130 萬類,給予模型更豐富的圖面變化,增加資料多樣性,將效果提高 4.1%。
- 在 ImageNet-1K 的基礎上再引入 CLIP 模型,在訓練的過程中進行知識蒸餾,則效果可以在 TPR@FPR=1e-4 的比較基準中再往上提升 4.6%。
- 若將 BatchNorm 和 LayerNorm 同時使用,可以將結果提升到 91.2%。
- Settings
評估結果
我們在評估模型的能力上,採用 TPR@FPR=1e-4 的標準,但實際上這個標準相對嚴格,且在部署時候會要成比較不好的使用者體驗。因此我們建議在部署時,可以採用 TPR@FPR=1e-1 或 TPR@FPR=1e-2 的閾值設定。
目前我們預設的閾值是採用 TPR@FPR=1e-2 的標準,這個閾值是經過我們的測試和評估後,認為是一個比較適合的閾值。詳細的閾值設定表如下列:
-
lcnet050_cosface_f256_r128_squeeze_imagenet_clip_20240326 results
-
Setting
model_cfgto "20240326" -
TPR@FPR=1e-4: 0.912
FPR 1e-05 1e-04 1e-03 1e-02 1e-01 1 TPR 0.856 0.912 0.953 0.980 0.996 1.0 Threshold 0.705 0.682 0.657 0.626 0.581 0.359 -
TSNE & PCA & ROC Curve
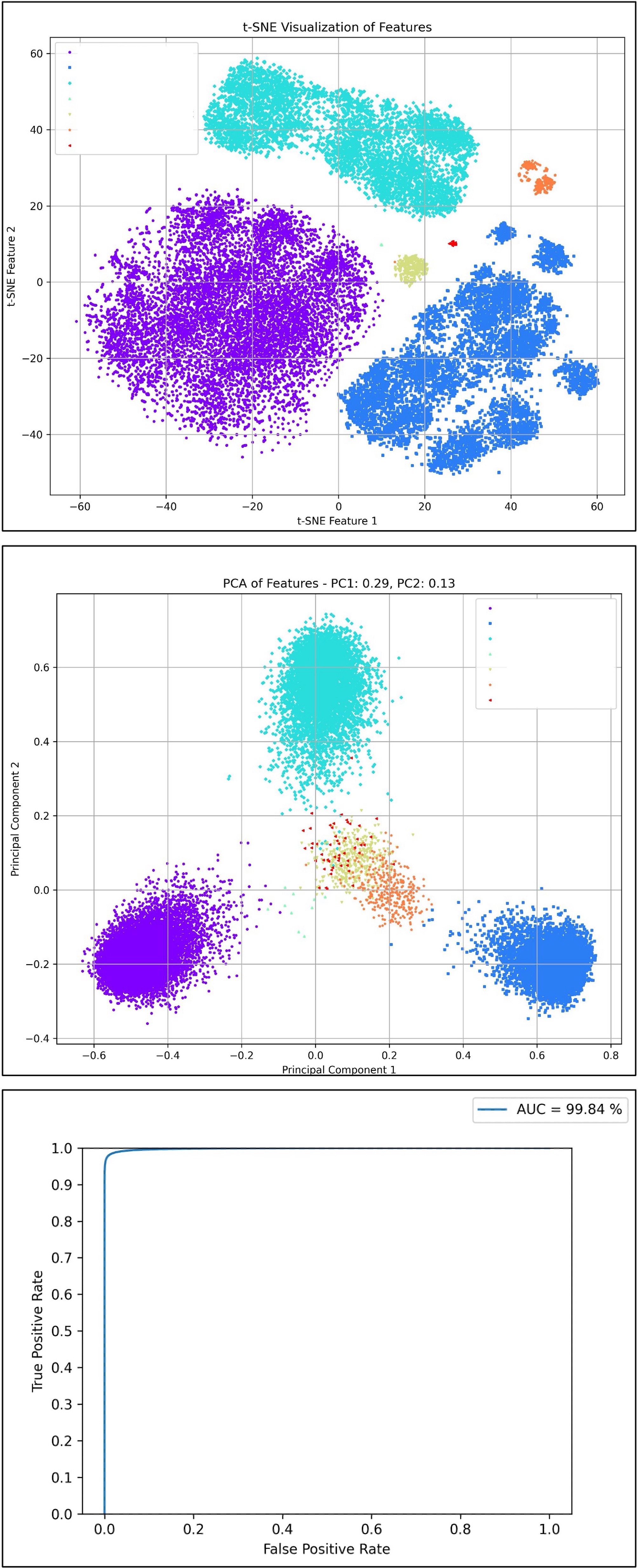
-