
臺灣股市每隔一段時間就會更迭一次股票代號,每次都用人工查找,總不是辦法。
所以我們需要自動化!
安裝環境
遇到困難就自己寫個程式吧,首先安裝必要的套件:
pip install requests beautifulsoup4 json
提示
這邊我會假設你已經有了可以正常運行的 Python 環境。
目標網頁
股票相關的資料都在臺灣證券交易所(TWSE)的網站上,因此我們需要找到目標網頁:
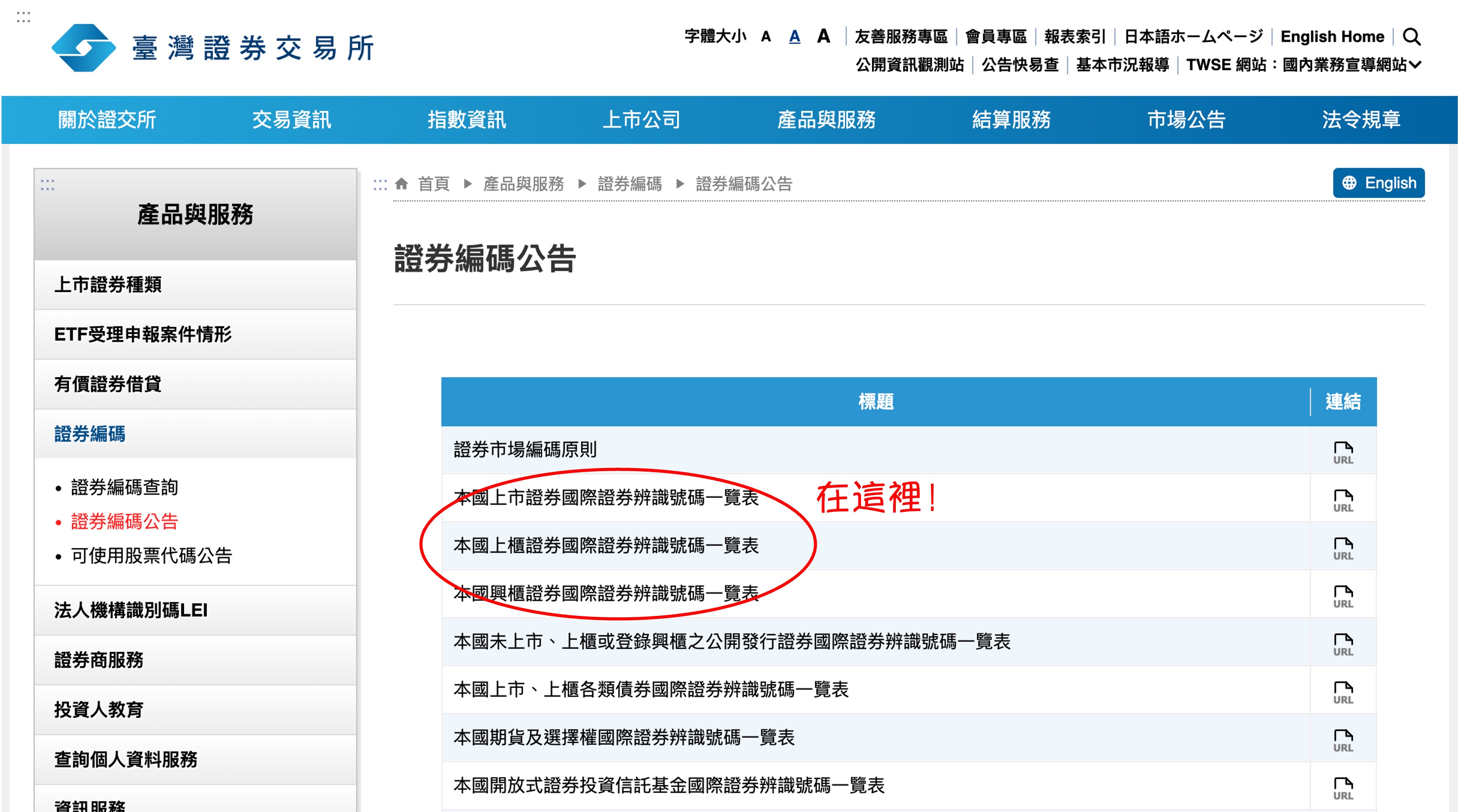
先把這三個網頁記下來:
urls = [
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=2", # 上市證券
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=4", # 上櫃證券
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=5" # 興櫃證券
]
解析網頁
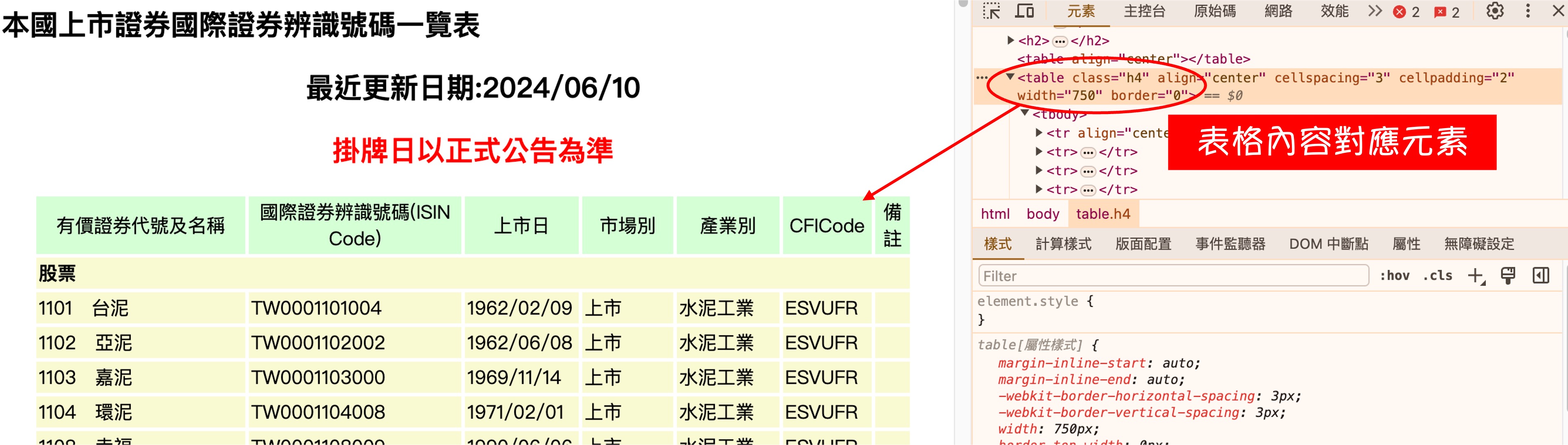
網頁點進去之後,查詢一下主要表格對應的 HTML 標籤是:class=h4。
好,找到目標之後,就可以開始寫程式了:
update_stocks_code.py
import json
import requests
from bs4 import BeautifulSoup
# 取得臺灣證券交易所公告內容
urls = [
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=2", # 上市證券
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=4", # 上櫃證券
"https://isin.twse.com.tw/isin/C_public.jsp?strMode=5" # 興櫃證券
]
# All data infos
data = {}
total_urls = len(urls)
for index, url in enumerate(urls, start=1):
print(f"Processing URL {index}/{total_urls}: {url}")
response = requests.get(url)
response.encoding = 'big5' # 設定正確的編碼格式
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', {'class': 'h4'})
if not table:
print(f"Table not found for URL: {url}")
continue
for row in table.find_all('tr')[1:]: # 跳過表頭
cells = row.find_all('td')
if len(cells) != 7:
continue
code, name = cells[0].text.split("\u3000")
internationality = cells[1].text
list_date = cells[2].text
market_type = cells[3].text
industry_type = cells[4].text
data[code] = {
"名稱": name,
"代號": code,
"市場別": market_type,
"產業別": industry_type,
"上市日期": list_date,
"國際代碼": internationality
}
with open("stock_infos.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("All data has been processed and saved to stock_infos.json")
輸出結果
stock_infos.json
{
"1101": {
"名稱": "台泥",
"代號": "1101",
"市場別": "上市",
"產業別": "水泥工業",
"上市日期": "1962/02/09",
"國際代碼": "TW0001101004"
},
"1102": {
"名稱": "亞泥",
"代號": "1102",
"市場別": "上市",
"產業別": "水泥工業",
"上市日期": "1962/06/08",
"國際代碼": "TW0001102002"
},
...以下省略...
}
最後用 json 來輸出結果,這樣之後串接其他程式比較方便。
常見問題
我只要一般股票
我猜你指的是股票代號為「四碼」的股票,不要 ETF、權證等等,想取得這個資料的話,直接在程式中加入過濾條件即可:
if len(code) != 4:
continue
我只要特定的產業
這個需求可以拓展到特定的市場別、產業別、上市日期等,甚至是上一個「取得一般股票」的問題,都一樣!
你只需要把輸出的 json 檔案用 Pandas 讀進來,然後用條件篩選即可:
import pandas as pd
df = pd.read_json("stock_infos.json", orient="index")
target = df[df["產業別"] == "水泥工業"]
程式壞掉了
那可能是臺灣證券交易所的網站改版,導致網頁結構變了,這個部分遇到了再來改吧。
結語
之後只需要不定期的執行這個程式,就可以取得最新的股票資訊。
提示
不過既然你都來一趟了,不妨喝杯茶再走。
我這裡順手寫了一個 API,串接 FinMind 的股票資料。點選下面的下載按鈕,就可以從 FinMind 取得最新的股票資訊。雖然資料格式可能和證交所有點差異,但你應該不會介意才對。
JSON
☕ 一杯咖啡,就是我創作的燃料!
贊助我持續分享 AI 實作、全端架構與開源經驗,讓好文章不斷更新。
AI / 全端 / 客製 一次搞定
從構想到上線,涵蓋顧問、開發與部署,全方位支援你的技術實作。
包含內容
- 顧問服務 + 系統建置 + 客製開發
- 長期維運與擴充規劃
🚀 你的專案準備好了嗎?
如果你需要客製服務或長期顧問,歡迎與我聯繫!